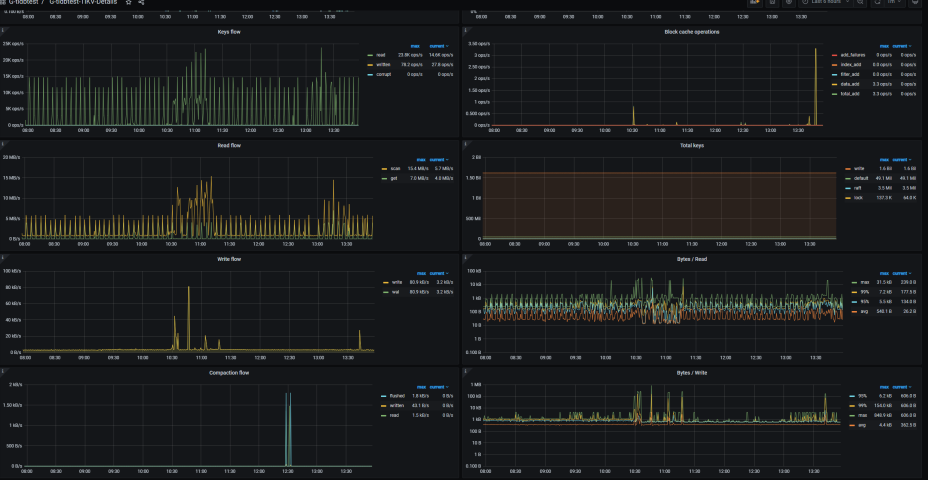
【概述】 场景 + 问题概述
项目在11点左右访问慢,这个该怎么优化?
Cluster-Overview → TiDB → Statments QPS
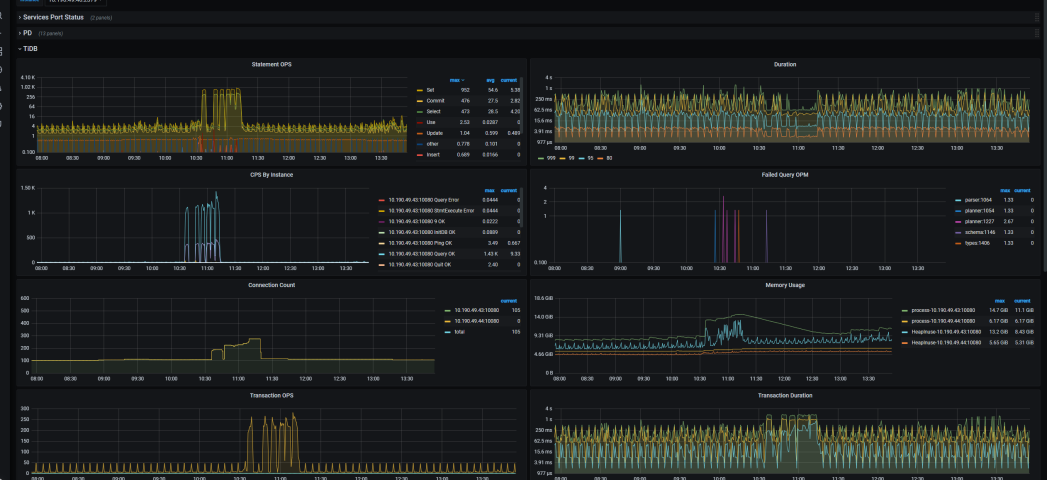

。
qps增高说明这段时间业务量有变化,可以在dashboard里看看慢SQL,确认是什么任务造成? PD TSO耗时有增高看看tidb/pd 的CPU、网络情况,这集群的资源应该不高吧
优化,首先要找到问题。系统瓶颈是啥,是io吗,或者是网络,内存? 如果单个语句慢,考虑在where条件涉及到的表增加合适的索引
业务高峰期,主要看有没有遇到瓶颈
没影响业务正常进行,或是具备承载冗余没必要优化
QPS变高不是坏事吧?只要系统正常运行,没有影响到业务访问的性能
你这个比较奇怪,QPS多出的操作都是set、commit和select操作.
1、业务SQL中有set、commit操作吗?
2、是不是用的框架导致的?怀疑是心跳之类的,因为select增多,时延反而降低,说select很轻量级的。
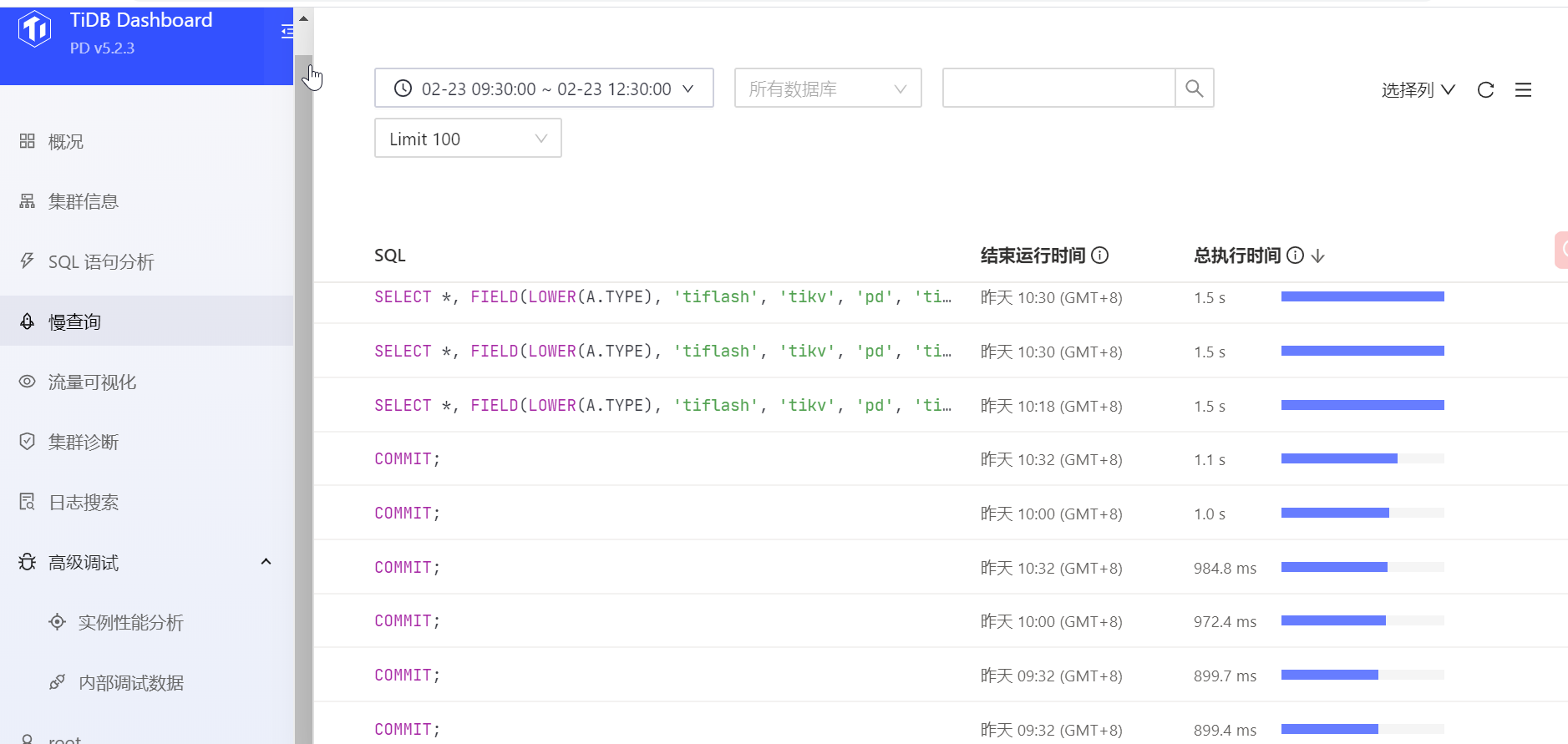
3、在dashboard中查看下那段时间内出现高频的select语句是什么?
这些SELECT有点像监控采集数据的SQL啊
那时候不知道测试在做压测,项目访问比较慢,所以想看看是不是数据库性能有影响
那个select不是业务里面的sql,还有这些commit也不知道是哪里的
应该可以定位到这些SQL的来源
上面的语句 看似是系统的SQL,能否把完整的语句发出来下? 其次当时或者之前有做过什么操作吗?
SELECT
*,
FIELD(LOWER(A.TYPE), ‘tiflash’, ‘tikv’, ‘pd’, ‘tidb’) AS _ORDER
FROM
(
SELECT
TYPE,
INSTANCE,
DEVICE_TYPE,
DEVICE_NAME,
JSON_OBJECTAGG(NAME, VALUE) AS JSON_VALUE
FROM
INFORMATION_SCHEMA.CLUSTER_LOAD
WHERE
DEVICE_TYPE IN (?, ?)
GROUP BY
TYPE,
INSTANCE,
DEVICE_TYPE,
DEVICE_NAME
) AS A
ORDER BY
_ORDER DESC,
INSTANCE,
DEVICE_TYPE,
DEVICE_NAME [arguments: (memory, cpu)];
除了测试在压测之外没有其他操作了
集群资源不足
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。