Asiaye
(AsiaYe)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】 线上环境
【概述】线上环境中,服务器宕机之后,状态字段显示有问题
【背景】利用pd-ctl清理了store和member
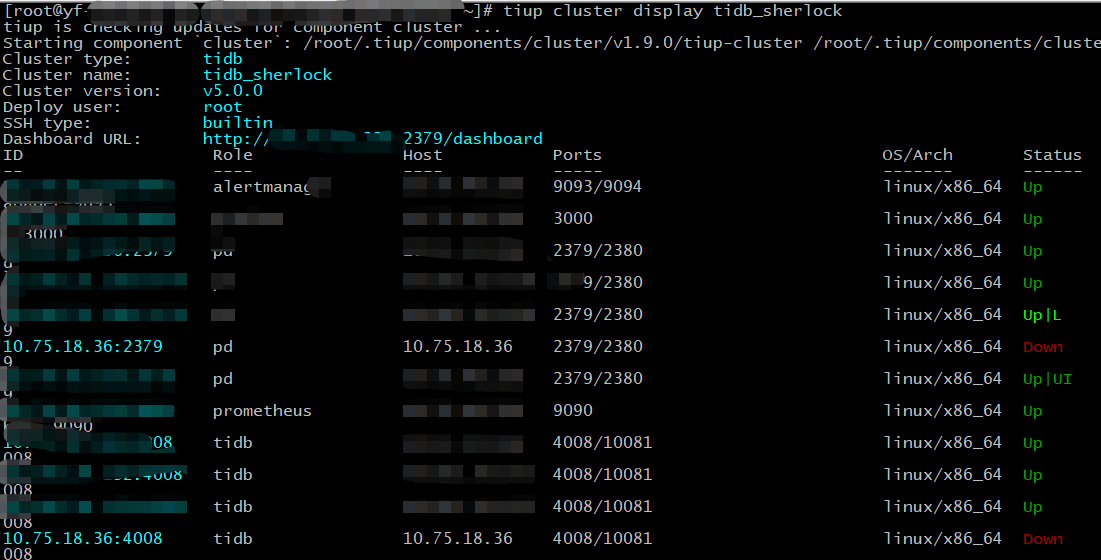
【现象】某台tidb服务器上部署了pd、tikv、tidb三个组件,宕机之后,使用pd-ctl执行了store delete和member delete,发现tidb cluster display的结果中这个节点依旧存在,且状态是down。实际上pd-ctl查看member和store,节点已经不存在了。
【业务影响】无影响
【TiDB 版本】5.0.0
【附件】
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
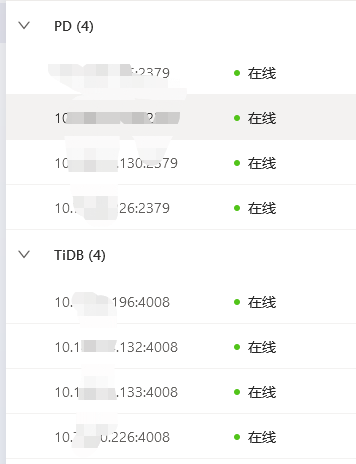
TiDB- Overview 监控
h5n1
(H5n1)
4
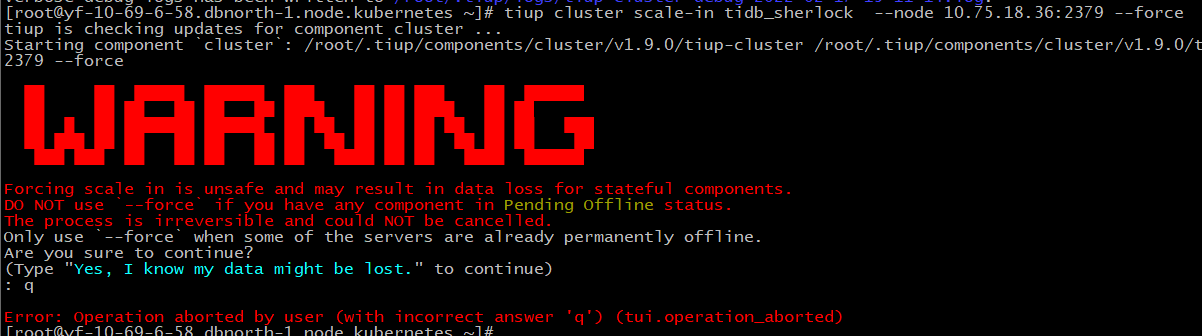
tiup cluster scale-in 把down的缩容
Asiaye
(AsiaYe)
6
正常来说,我机器宕机了,而且使用ctl工具驱逐了节点,在prune一手,应该就完事儿了吧?
Asiaye
(AsiaYe)
7
现在是prune之后,没用,还是在,但是tidb的dashboard上已经没有了。
h5n1
(H5n1)
9
使用tiup工具正常应该是先缩容,然后在Prune ,如果监控还有在从Pd处理
3 个赞
Asiaye
(AsiaYe)
10
节点宕机了,连接不上了,这种情况,也需要先缩容吗?缩绒的时候肯定提示SSH不通啊。
Asiaye
(AsiaYe)
11
问题已经解决,通过强制scale-in --force解决。感谢。
2 个赞
system
(system)
关闭
12
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。