版本:v4.0.14
tidb-pd部署在同一台机器上,三个tidb节点,三个pd节点,三个kv节点。
背景:用haproxy代理,开启了ip传透,宕机原因是因为慢sql造成的oom
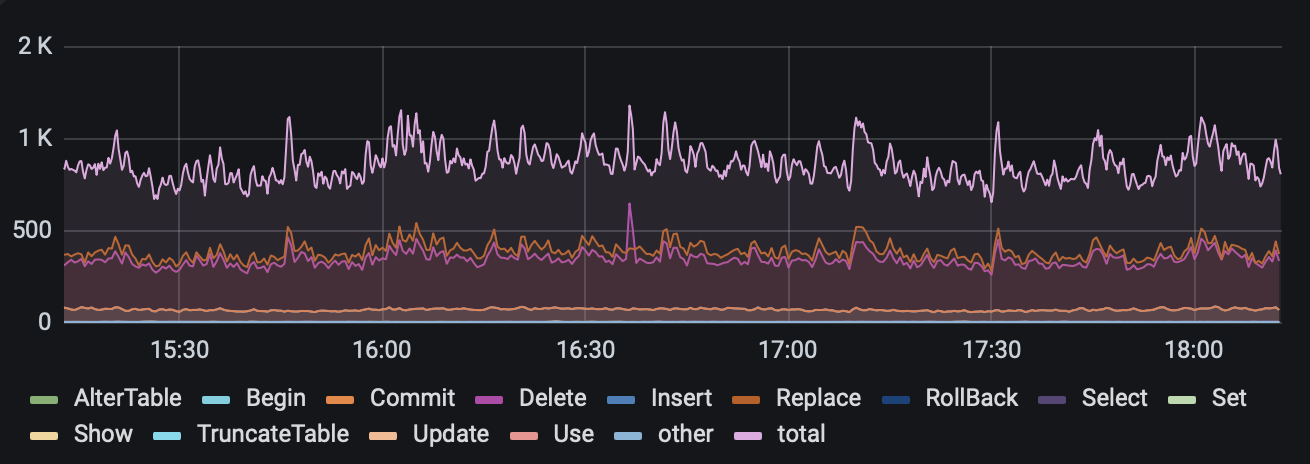
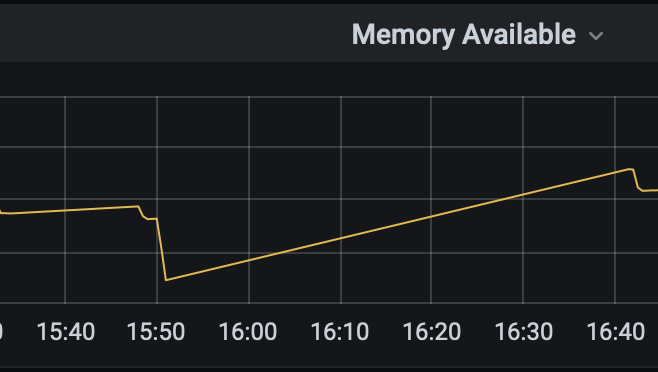
内存监控如下:
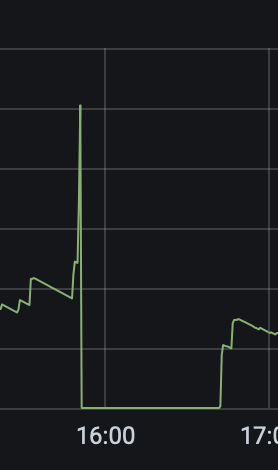
下面的文件为welcome前后的日志,不理解为什么需要这么长时间来恢复
a.txt (1.1 MB)
版本:v4.0.14
tidb-pd部署在同一台机器上,三个tidb节点,三个pd节点,三个kv节点。
背景:用haproxy代理,开启了ip传透,宕机原因是因为慢sql造成的oom
内存监控如下:
下面的文件为welcome前后的日志,不理解为什么需要这么长时间来恢复
a.txt (1.1 MB)
tidb是无状态的,oom 后会快速拉起,看日志也是快速拉起来的,也有 cop 请求,你说的慢是指的什么?
您看日志里面8:21就开始没有记录了,8:41才有welcome的消息,应用7:57就不能访问了,因为是utc时间,所以日志这里的8:00对应16:00
tidb err 和系统内核日志排查下呢,以及节点流量监控看下
期待大牛指点
主要是看下事发当时该节点的流量情况、访问报错的信息,操作系统内核日志是不是发错了,tidb error 有报错么
tidb error日志:
[15020087.583767] Killed process 14471 (tidb-server) total-vm:65937704kB, anon-rss:63770352kB, file-rss:0kB
[15889190.856602] tidb-server invoked oom-killer: gfp_mask=0x24201ca, order=0, oom_score_adj=0
[15889190.856606] tidb-server cpuset=/ mems_allowed=0
[15889190.856611] CPU: 5 PID: 10622 Comm: tidb-server Not tainted 4.4.0-1128-aws #142-Ubuntu
[15889190.856890] [10592] 20065 10592 16580923 15924955 31552 66 0 0 tidb-server
[15889190.856895] Out of memory: Kill process 10592 (tidb-server) score 979 or sacrifice child
流量不是很大,有10条左右慢查询,占用了大量内存
内核日志我是用的dmesg -T,应该没有错吧,或者您这头要哪个
大佬,还有什么需要提供的请告诉我
请提供下以下信息:
1./var/log/kern.log oom重启前后的日志
2.问题时间段,该机器上的其它进程正常么?
3.故障前后的监控导出看下吧,TiDB 的和 Node_exporter 的
1.这个看了下只有重启后的日志,这个文件就100多行
kern.log (15.4 KB)
2.问题其他的进程没法观看,问题期间登陆不上机器,exporter死掉了,能登陆的时候发现ldap服务也掉了,应该也是oom影响的
3.监控私发给大佬了,如果有问题您在告诉我
看起来是系统夯死了吧,sar -B 事发时间段的数据贴下
抱歉啊,这个没有开,还有其他方法么,看了下系统信息,确实应该hung死了
我大概清楚我昨天的问题了,是tidb占用的内存太大了,机器hung住了,但是tidb的进程貌似还没有死,等到8:40的时候才真正死的,然后8:41就起来了
请问大佬有什么办法可以避免这个问题么
那段时间点的cpu情况
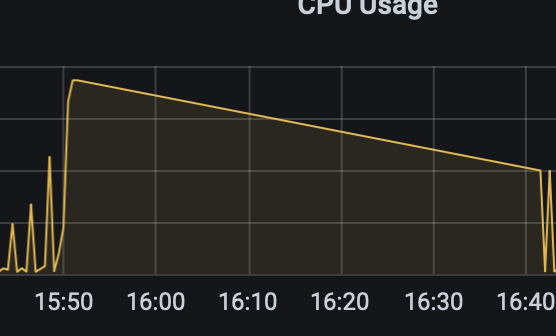
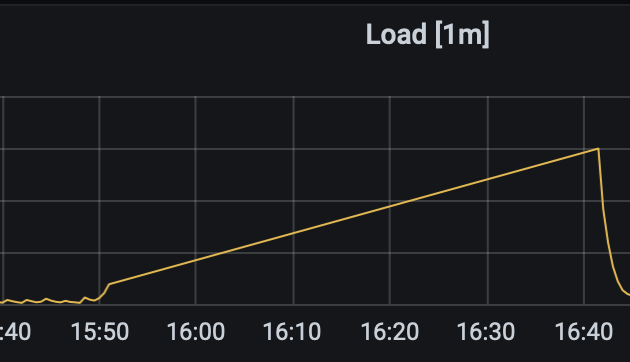
可以考虑降低 vm.dirty_ratio 的比例到一个适合业务负载的值
好的,感谢大佬,我明天试试,cpu,内存隔离和这个参数,看能不能避免hung死的情况
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。