【概述】
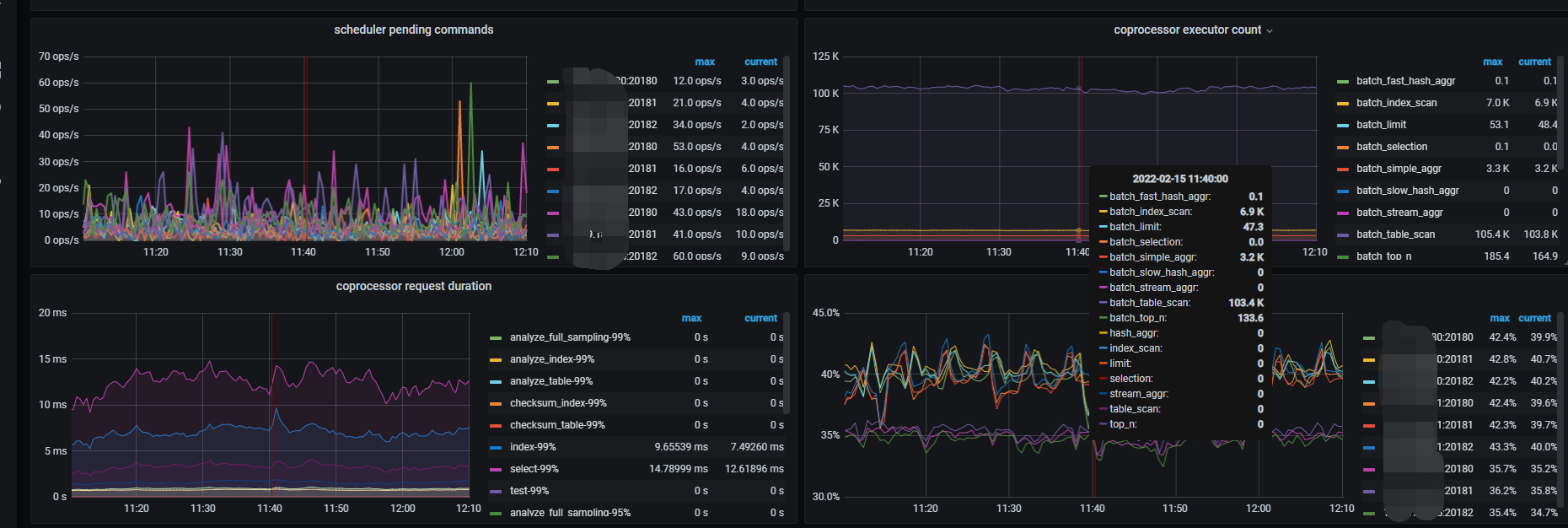
3节点集群某一节点cpu load持续告警:
【背景】
修改cpupower为performance模式,load未降低
【现象】
cpu load过高
【业务影响】
无,响应延迟正常
【TiDB 版本】
v5.2.3
【附件】
集群Overview页面监控导出:
2022-02-15T04_06_47.380Z.json (79.8 KB)
【概述】
3节点集群某一节点cpu load持续告警:
curl http://ip:端口/debug/pprof/goroutine?debug=2 上传一下
debug.log (317.9 KB)
ebug.log: parsing profile: unrecognized profile format debug=2 去掉。在导出一下
/debug/pprof/goroutine吗,生成了二进制文件:
debug.log.new (10.2 KB)
SELECT
`id`,
...
FROM
`table_name`
WHERE
(`uid` = ?)
ORDER BY
`add_time` DESC
LIMIT
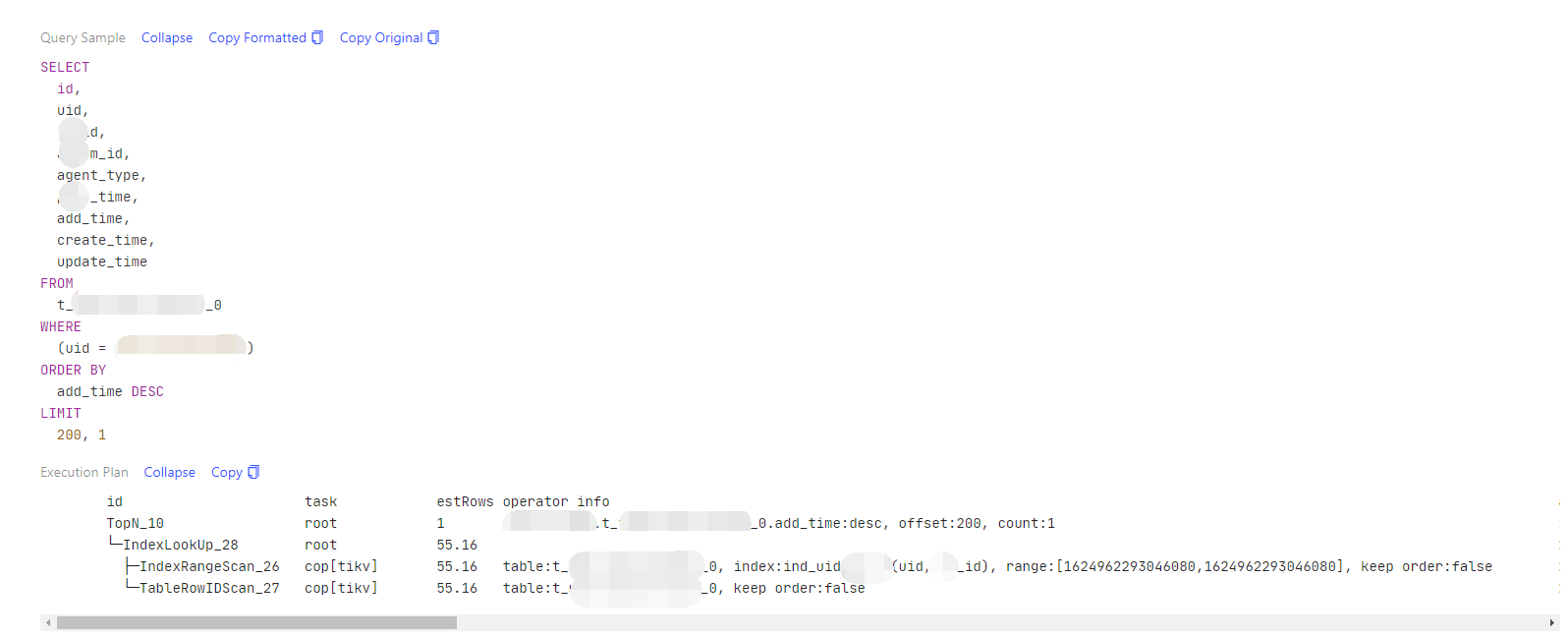
uid是一个双字段unique key的前缀字段,平均响应时间为36ms
执行计划看下
可以查下热点表的相应region分布。
分布还是相对均匀的,我把热点表的show table regions结果导出来之后,用sort uniq -c做了下统计:
# awk '{print $10}' regions|sort|uniq -c
59 1
157 10
101 11
128 12
83 13
90 14
103 15
71 2
62 3
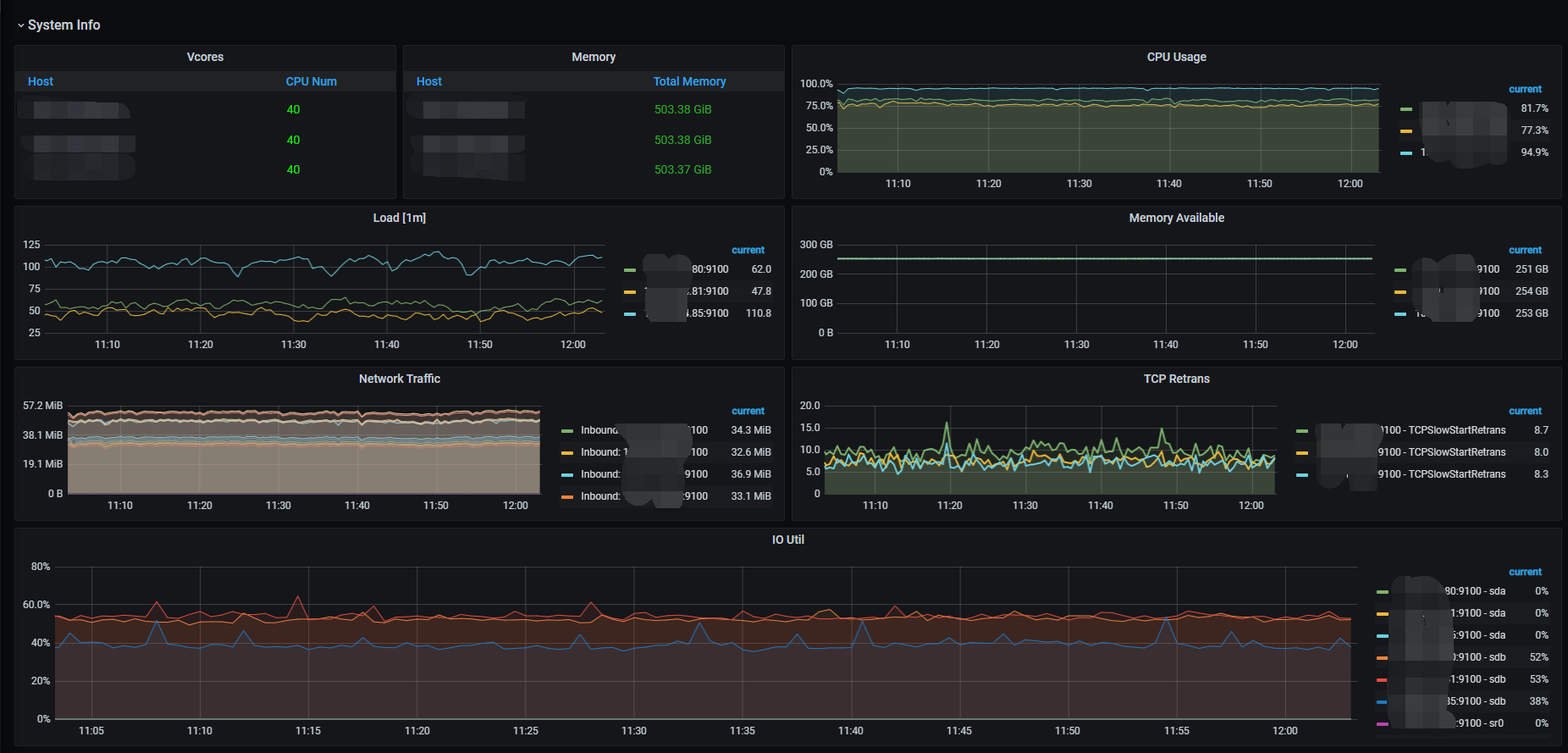
首列为region count,次列为store_id,此集群总计12个store,1,2,3这3个store所在的机器是本次load告警的机器,剩下2台机器cpu反而不告警。
要看热点表对应的region 所在的store
第二列是store_id,和真实地址的对应关系是:
还有就是load告警的这台现在恰好是pd leader,也加重了cpu的负载,我尝试resign下看看load告警是否会转移。
==>没有转移,top看起来应该是tikv-server之间的cpu使用率差异
热点表是重点
![]() 这个集群就一个热点表,top SQL里前几个SQL全是针对此表的操作,也是我上述几层里所描述的表。
这个集群就一个热点表,top SQL里前几个SQL全是针对此表的操作,也是我上述几层里所描述的表。
top 命令显示的是这三台 tikv-server 消耗的 CPU 都很高还是部分很高?可以通过 pd-ctl 中看下是不是存在个别热点的 region ,命令: region topread 和 region topwrite ,如果存在可以考虑针对热点的 region 做下 split ,参考:https://docs.pingcap.com/zh/tidb/v5.1/sql-statement-split-region#split-table-region
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。