【 TiDB 使用环境】
max-merge-region-keys 400000
max-merge-region-size 144
merge-schedule-limit 24
等待一段时间后region和peer个数开始减少,但空间依然未释放,昨天下班前为性能计将merge-schedule-limit调回了8其他参数未变,今日上午发现merge operator在昨日调整后就平静下来了,于是重新修改merge-schedule-limit为24后region peer继续下降,空间依然未释放。
【问题】:
2 个赞
有人吗
基本上这些hash表都只保存了今年1.27号之后的数据,从stats_histograms里也能验证只有少数分区有数据
所有hash分区表都使用to_days(time)做了hash(366)的分区,因此实际上只有mod(to_days(‘2022-01-27 00:00:00’),366)=325,即p325之后的分区有实际数据
通过show table xxx partition(p1) regions可以验证那些无数据的分区确实只有1个region了
“max-replicas”: 3
使用下述语句估算了所有7个业务表中理应merge的region,发现结果基本为空或者不过10.
show table xxx regions where `APPROXIMATE_SIZE(MB)`>50 and APPROXIMATE_KEYS<10000;`
2 个赞
首先,region 是一个逻辑的组织结构,不是一个物理的文件,tikv 中物理文件是指 sst 。调整 region merge 相关的参数,能够达到减少 region 的目的,因为集群中 region 数量过多会带来一些性能问题, 具体见:
https://docs.pingcap.com/zh/tidb/stable/massive-regions-best-practices/#海量-region-集群调优最佳实践
其次,tikv 集群要释放存储空间,那么需要清理集群中的数据,并且在 gc 和 compaction 的配合下降低存储占用。gc 相关的内容见:https://docs.pingcap.com/zh/tidb/stable/garbage-collection-overview/#gc-机制简介
最后,删除数据 / gc / compaction 和 empty region 的关系是:
当 dml 或 ddl 删除数据后,不会立即释放空间
达到 gc 周期后,开始进行 gc 流程
gc 完成后,drop 操作对应的空间会释放,而 dml 操作需要等待 rocksdb compaction 后,才会释放
以 drop 操作为例,此时其占用的物理空间已经释放,当对应的 region 上报心跳给 pd 后,pd 发现该 region 已经变成 empty region,开始进行 region merge 调度
集群中空 region 逐步变少
至此,集群中物理空间释放,空 region 数量降低 ~
3 个赞
嗯嗯,谢谢回复。
1 个赞
这个信息统计出来的数据占用量并不准确,会有误差,并且很遗憾,现在 tidb 没有提供一个针对已有数据库对象空间占用的计算方式 ~
如果您那里方便,可以在 github 上提交一个相关的 issue,看下相关老师们针对这个需求的后续计划 ~
3 个赞
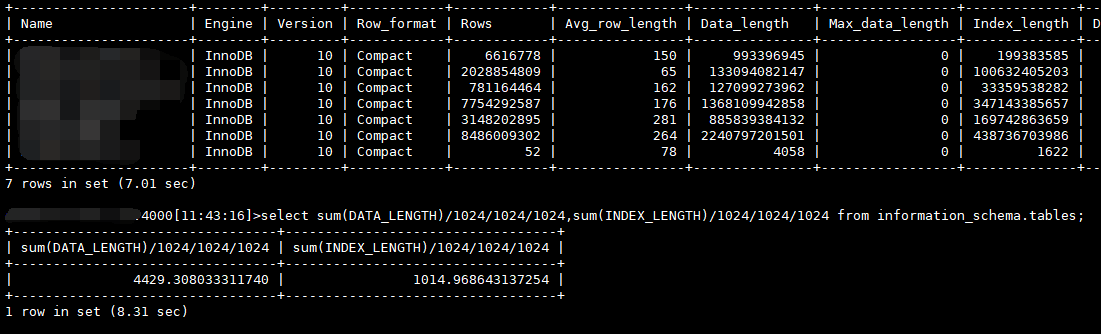
我选择了一个【Data_length+Index_length】值约为2900多GB的表,以下可知有数据的hash分区数约有20个左右,本次我将清理1-27号这个分区(p325),从show stats_histograms where table_name ...;的结果来看此分区数据量确实占整表约1/20,因此预估本次清理后应当释放出140GB*3大小的空间。
>select min(time),max(time) from <table>;
+---------------------+---------------------+
| min(time) | max(time) |
+---------------------+---------------------+
| 2022-01-27 00:00:00 | 2022-02-17 10:04:51 |
+---------------------+---------------------+
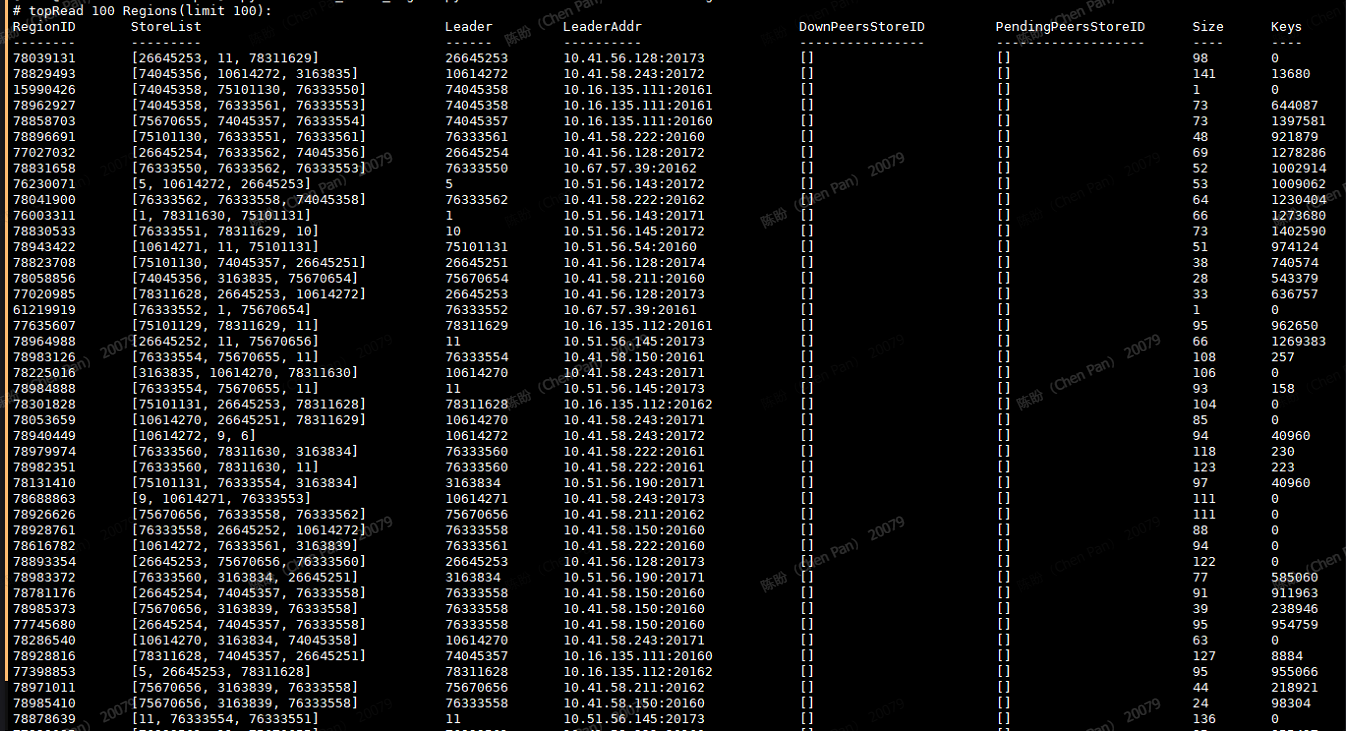
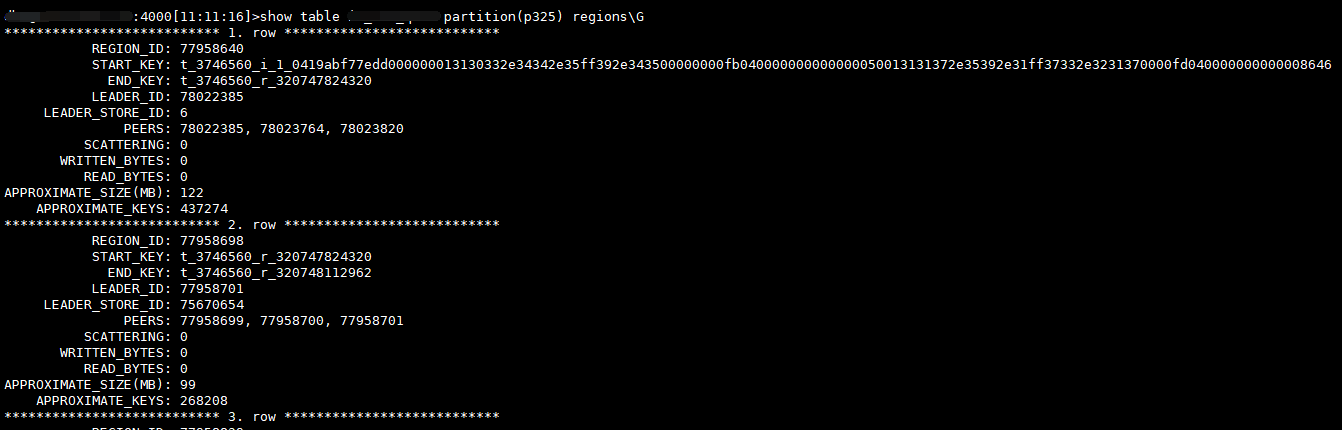
删除之前mysql.tidb和show table … partition(p325) regions部分截图如下:
show partition region显示
2356 rows in set (25.99 sec)
本次计划观察的即上述2个region:77958640,77958698
开始删除数据并验证结果,显示数据已被清理。
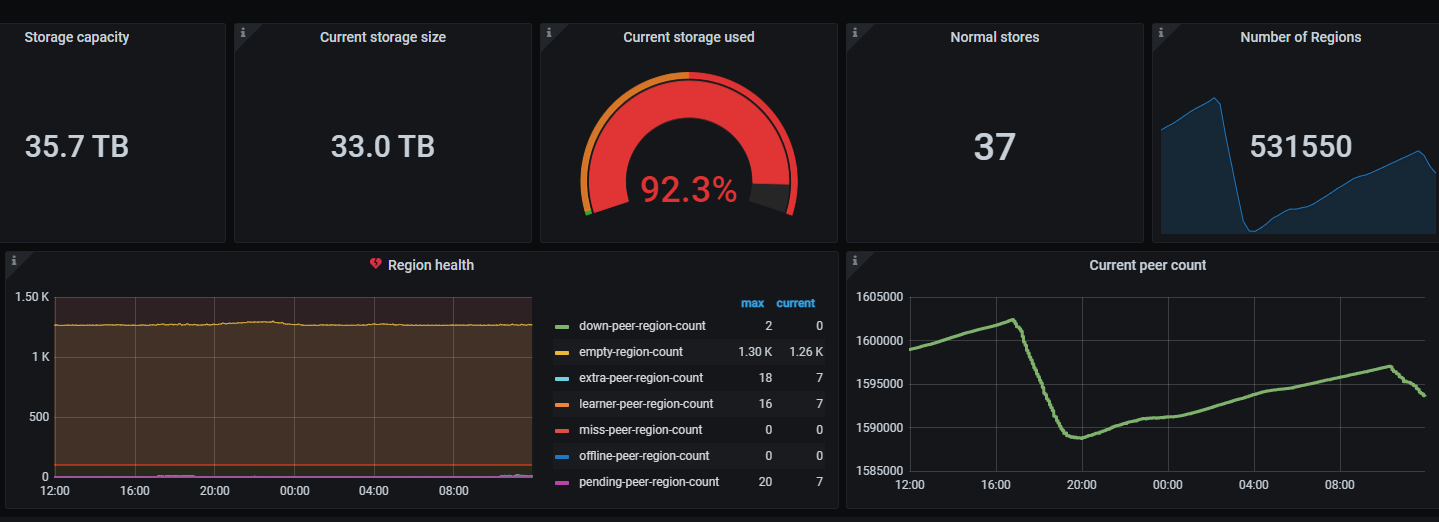
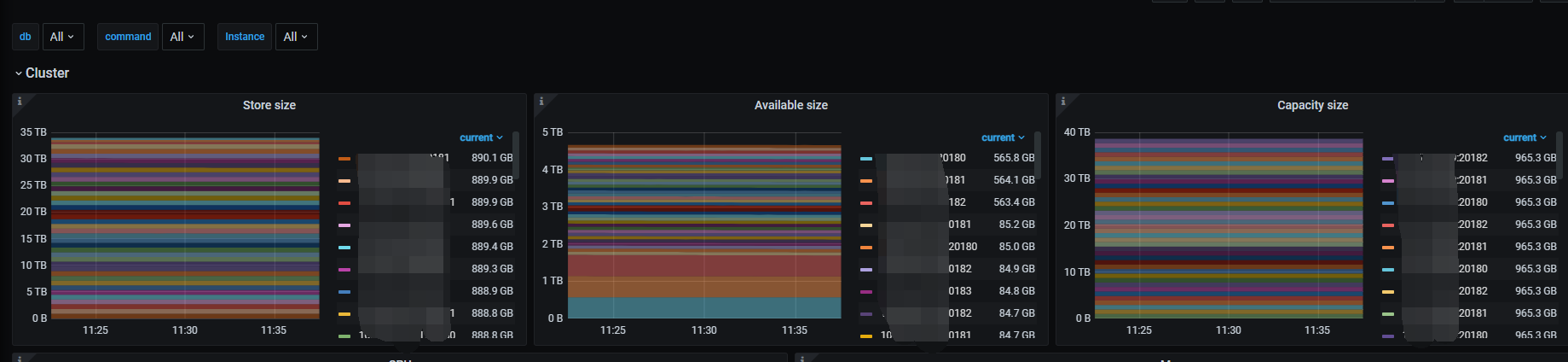
删除后下一次GC大约还有10min到来,等待gc之后查看监控如下:
可以看到容量和region数几乎无变化,依然在正常增长。
孤儿region信息获取:
>select * from information_schema.tikv_region_status where region_id in (77958640,77958698)\G
*************************** 1. row ***************************
REGION_ID: 77958698
START_KEY: 748000000000392BFF005F728000004AAEFF0F64C00000000000FA
END_KEY: 748000000000392BFF005F728000004AAEFF13CC420000000000FA
TABLE_ID: NULL
DB_NAME: NULL
TABLE_NAME: NULL
IS_INDEX: NULL
INDEX_ID: NULL
INDEX_NAME: NULL
EPOCH_CONF_VER: 7187
EPOCH_VERSION: 749297
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE: 99
APPROXIMATE_KEYS: 268208
*************************** 2. row ***************************
REGION_ID: 77958640
START_KEY: 748000000000392BFF005F698000000000FF0000010419ABF77EFFDD00000001313033FF2E34342E35FF392EFF343500000000FB04FF0000000000000050FF013131372E35392EFF31FF37332E323137FF0000FD0400000000FF0000864600000000FB
END_KEY: 748000000000392BFF005F728000004AAEFF0F64C00000000000FA
TABLE_ID: NULL
DB_NAME: NULL
TABLE_NAME: NULL
IS_INDEX: NULL
INDEX_ID: NULL
INDEX_NAME: NULL
EPOCH_CONF_VER: 7943
EPOCH_VERSION: 750339
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE: 122
APPROXIMATE_KEYS: 437274
2 rows in set (24.85 sec)
从pdctl可知上述2个region leader目前所在的store,通过tikv-ctl获取properties信息:
$ tiup ctl:v4.0.16 tikv --host=<tikv-ip>:20160 region-properties -r 77958698
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v4.0.16/ctl tikv --host=<tikv-ip>:20160 region-properties -r 77958698
num_files: 4
num_entries: 2726892
num_deletes: 1360938
mvcc.min_ts: 430752281976373308
mvcc.max_ts: 430819616257998851
mvcc.num_rows: 1365954
mvcc.num_puts: 1364253
mvcc.num_versions: 1365954
mvcc.max_row_versions: 1
middle_key_by_approximate_size: t\200\000\000\000\0009+\000_r\200\000\000J\256\021\336\006
sst_files: 1866563.sst, 1907386.sst, 1760298.sst, 1908190.sst
$ tiup ctl:v4.0.16 tikv --host=<tikv-ip>:20173 region-properties -r 77958640
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v4.0.16/ctl tikv --host=<tikv-ip>:20173 region-properties -r 77958640
num_files: 4
num_entries: 2541070
num_deletes: 424104
mvcc.min_ts: 430762165735784455
mvcc.max_ts: 430800149090664453
mvcc.num_rows: 2115702
mvcc.num_puts: 2115702
mvcc.num_versions: 2116966
mvcc.max_row_versions: 3
middle_key_by_approximate_size: t\200\000\000\000\0009+\000_r\200\000\000J\256\013\302\264
sst_files: 142517823.sst, 142025347.sst, 142516056.sst, 142529362.sst
h5n1
2022 年2 月 17 日 04:01
10
msyql.gc_delete_range是drop truncate后要处理的key范围,tidb会据此删除sst文件,处理完成后会将处理完的范围信息放到gc_delete_range_done,可以检查下truncate后range表是否有内容,GC时间后done表是否有新增的处理内容
1 个赞
当前gc_delete_range有761行数据,gc_delete_range_done有6条。
感谢反馈,方便导出一个包含 truncate 操作以及 gc 完成前后时间段的 tikv-details 监控吗?辛苦 ~
导出工具如下:
作者:Kennytm Chen 、Rick lee
这个问题,辛苦找几条记录使用 pd-ctl 来解析下 ts ,看下这些数据都集中在哪些时间,确认下是否是 gc 『未正常』执行导致:
gc_delete_range
gc_delete_range_done
解析了下两个表的时间戳列,截取最后10行如下:
2022-02-15 17:45:38
2022-02-15 17:45:49
2022-02-15 17:45:56
2022-02-15 17:47:14
2022-02-15 17:47:25
2022-02-16 10:31:19
2022-02-16 11:12:19
2022-02-16 11:38:06
2022-02-17 11:18:43
2022-02-17 12:20:28
gc_delete_range_done
2021-11-03 23:00:00
2021-11-03 23:08:43
2021-11-03 23:26:05
2021-11-04 00:00:44
2021-11-04 02:02:10
2021-11-04 02:36:49
看起来 gc delete range 这里可能没有正常执行。辛苦提供下下述信息吧 :
导出一个包含 truncate 操作以及 gc 完成前后时间段的 tikv-details 监控
在 tidb 的 dashboard 中,检索下 tikv gc 相关的 log,并上传
以上信息如果不方便帖在帖子中,那么可以私信下啊,辛苦 ~
10-13点之间做过2次分区truncate。监控:TiKV-Details_2022-02-17T07_24_25.944Z.json (69.2 MB)
pd的日志中发现过gc相关的报错:
但是我之前检查过各个节点没有磁盘100%的。
tiup cluster exec xxx --sudo --command=“df -h”
tiup cluster exec xxx --sudo --command=“df -i”
结果显示数据盘基本都有几百GB的剩余空间,系统目录使用率也基本都在30%以下。
tikv的log没有gc关键字的搜索结果。pd的gc关键字直接搜索也没有error级别的,直接到pd leader里找gc关键字如上图所示
h5n1
2022 年2 月 17 日 07:57
19
1 个赞
目前没有,audit看下了历史记录,也没有tiflash的安装记录