为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】场景+问题概述
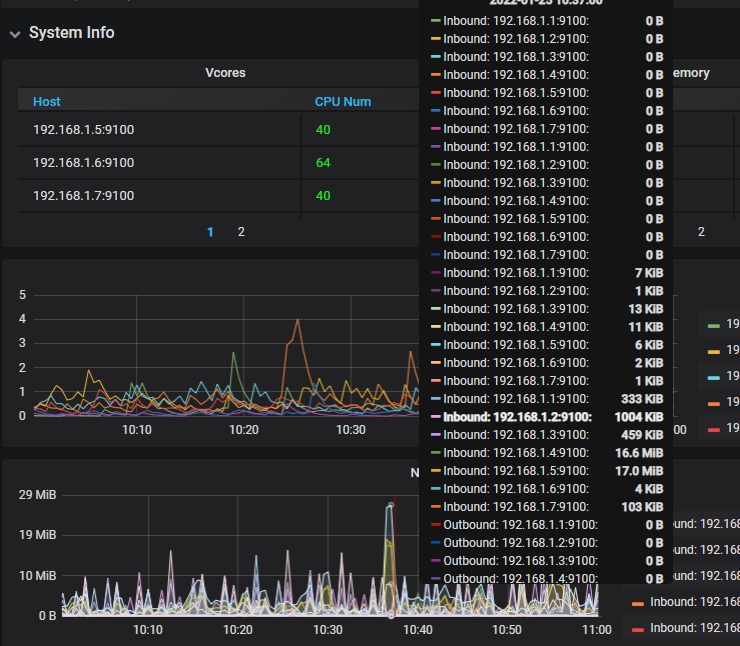
监控显示有几个节点ping延时很大,但手动ping又比较小,请问要怎么排查?谢谢!
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】V5.0.0
【附件】
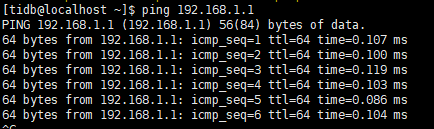
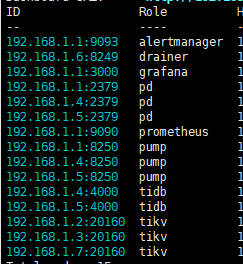
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
1 个赞
qizheng
(qizheng)
2
手动 ping 是对应监控上的两个节点 ip 么,source 是192.168.1.1 的,再查一下 prometheus-ip:9090 页面上的 probe_duration_seconds 记录值是多少
1 个赞
promethus和alertmanager都是部署在1.1,慢的是1.1以外的节点ping1.1
1 个赞
参考了这个,但有个疑问手动ping没见多大延时,也不好贸然去找基础部门的人
1 个赞
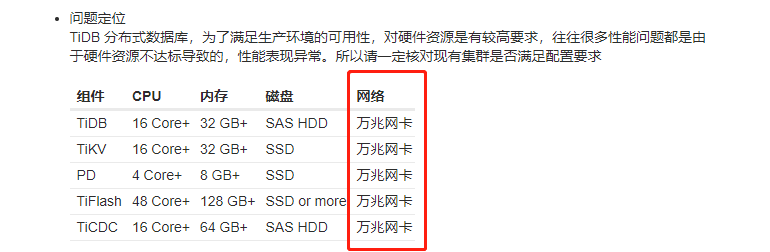
我们网卡是1000M卡,不知道是不是这个原因,但监控显示要4秒多就有点离谱,先查下这个指标是统计的啥
1 个赞
xfworld
(魔幻之翼)
6
千兆的容易被打满,瞬间打满了,就容易延迟了
我自己配的一台机器,有两块网卡,一块是千兆的,另一块是 2.5Gb的,就这样才能凑合用…
估计你也要考虑下这个情况,最好是万兆
1 个赞
有几台机器防火墙没有放开icmp,第一次检查不仔细。
谢谢!
1 个赞
system
(system)
关闭
10
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。