Meditator
(Wendywong020)
1
版本:4.0.11版本测试集群,
背景:
开发同学灌了3T的数据进行测试,TPS 1000左右,QPS几万,有A、B、C三个tikv节点,每个tikv大概有5.5w个region,集群正常,gc_lift_time=48h
1.19号挂了一个tikv B节点,没有处理
1.21号,准备扩了2个tikv节点D、E,让开发同学继续测试
扩完2个tikv节点后,顺手拉起之前挂掉的tikv实例,此时发现挂掉的tikv节点持续2m后oom,多次尝试都是这样。除了挂掉2天的B节点,其他的A\C节点和新扩的D、E节点都是正常。
处理:
1)把gc_lift_time改成720h,重启tikv、tidb-server后,再重启B节点还是oom挂掉,问题依旧
B节点 拉起后,内存直接在2m内飙升到os最大内存,然后oom,即便设置了capacity为4G也没有用。
2)把所有的调度都关掉,拉起B节点 ,问题依旧
并且始终伴随着raftstore pool size=4,每个raftstore线程的 cpu 90%左右,io 100MB/s
扩容期间,开发停止了读写压测。期间pd leader是正常的,没有异常错误。
拉起B节点 tikv负载高,perf查看:
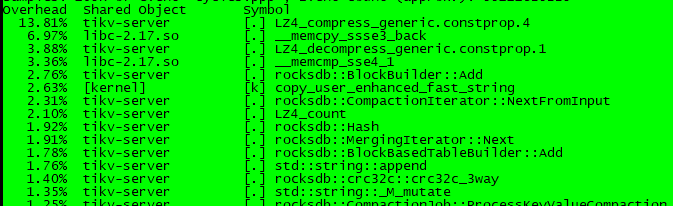
iotop查看:
对应tikv日志:
疑问:
1)tikv B节点只是少同步两天的数据,为什么拉起后会导致cpu io 内存飙升很高,以至于oom
2)关掉调度的情况下,为什么问题依旧?
3)把gc设置的无限大的情况,为什么问题还是依旧?
3 个赞
北京大爷
(北京大爷)
2
理论上超过 30min 的 B 节点上的相关数据已经无意义了。此时加入其实相当于将 region peer 重新进行回迁
更加高效的解决办法
- tiup --force 强制缩容 B node
- 手动在 B Node 进行数据和服务清理,同时检查是否有残留进程 node export、 blackbox 、tikv server
- 将 B 节点重新扩容回集群
1 个赞
Meditator
(Wendywong020)
3
多谢回复!
1)强制缩容也是一个解决办法;
2)目前是把B节点关闭掉,数据正常均衡中;
3)还有现象就是B节点oom的过程,A和C节点状态在disconenected和up两种状态种不断切换,最终在B节点变成down状态后一段时间,A和C才变成up状态。但是新加入的D和E自始始终都是up状态
4)另外,为什么拉启B,会导致raft的cpu io居高不下,并且还oom,但是调度都是关闭的。想知道引起这么高的负载原因是什么?
3 个赞
Meditator
(Wendywong020)
5
2 个赞
Meditator
(Wendywong020)
6
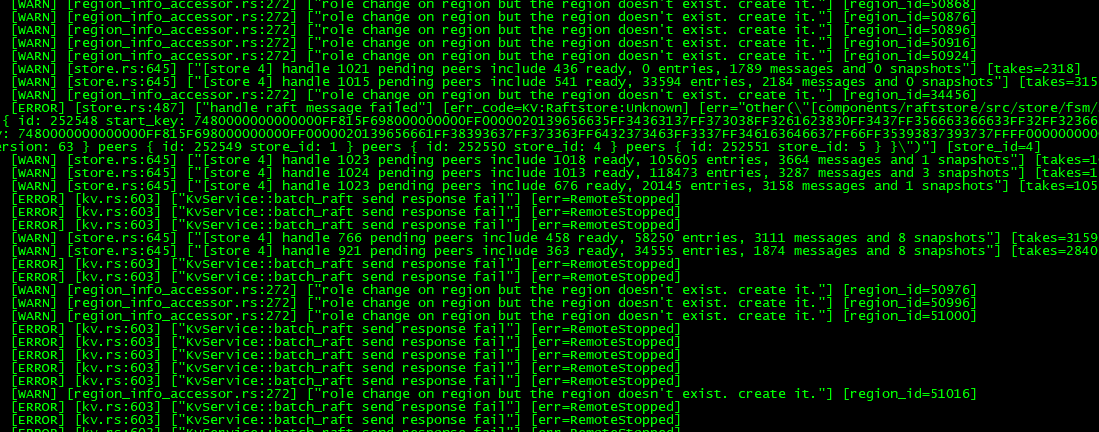
@QBin @北京大爷,帮看看,看似是compact堵塞导致的?
1 个赞
QBin
(Bin)
11
这个能打开了,辛苦也上传一下 OOM 的 tikv instance 的日志。
1 个赞
Meditator
(Wendywong020)
12
1 个赞
Meditator
(Wendywong020)
13
大致想了下,挂掉2天的B节点 突然拉起来后,此时有很多已经落盘(落到A、C节点)的rocksdb raft的log信息需要重新在B上apply吗?pending-peer-region-count值几千,远远大于默认值。
这也说明了apply线程、raftstore线程负载高的原因,但是有几个疑问:
1)已经落盘到A和C tikv节点上raft实例中的log信息是怎么同步给到B呢?
2)B节点OOM,目前看到是B节点上的apply线程、 raftstore线程消耗内存最多,但是scheduler模块有默认100MB的流控,好像这块不起作用
3)改小[raftstore] raft-max-inflight-msgs(流控raft log msg)无用。
1 个赞
Meditator
(Wendywong020)
14
1)感觉这种场景,最佳实践是把长时间挂掉的tikv节点缩容掉,然后再扩容,否则带来的raft log同步冲击,会严重影响整个集群。这种情况下 为什么不用region replica scheduler 来覆盖挂掉tikv上的不完整的region呢?
2)raft 实例上log日志数据保存多久呢?如果这个数据丢失(compact掉),那长时间挂掉的tikv只能通过缩容–》再扩容方式解决。
3 个赞
h5n1
(H5n1)
16
落后一定时间内走raft,超过了会走snapshot方式发送region快照,然后在补log.
3 个赞
Meditator
(Wendywong020)
17
通过火焰图可以发现内存主要消耗在raftstore和rocksdb的low线程(compact)这块。理论上拉起长时间挂的节点,相当于新加入的节点,不会对集群造成冲击才对。
QBin
(Bin)
18
请问下,一开始这台问题的 store 挂掉的也是因为 OOM 是嘛?
Meditator
(Wendywong020)
19
看了下os日志,也是oom被kill,因为是测试库,另外一个同事就没有处理(拉起)。
QBin
(Bin)
20
好的。可以先检查一下看看第一次 crash 的时候的 apply duration 以及 crash 时间的 apply 的量看看是否非常大。导致 apply 堆积引起的 OOM 。后续拉起之后会 apply 之前没 apply 掉的内容,然后由于内容太多,apply 太慢导致持续的 OOM 。类似的内存使用情况在 5.1 后一直在不断进行优化, 建议可以尝试使用较新的版本。目前针对这种情况,要快速恢复的话建议缩容再扩容。
1 个赞
Meditator
(Wendywong020)
关闭
22
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。



{kind=link}
{kind=link}