seiang
2022 年1 月 18 日 02:57
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】场景+问题概述
当时空region比较多,临时调大了merge-schedule-limit、max-merge-region-keys、max-merge-region-size之后恢复正常
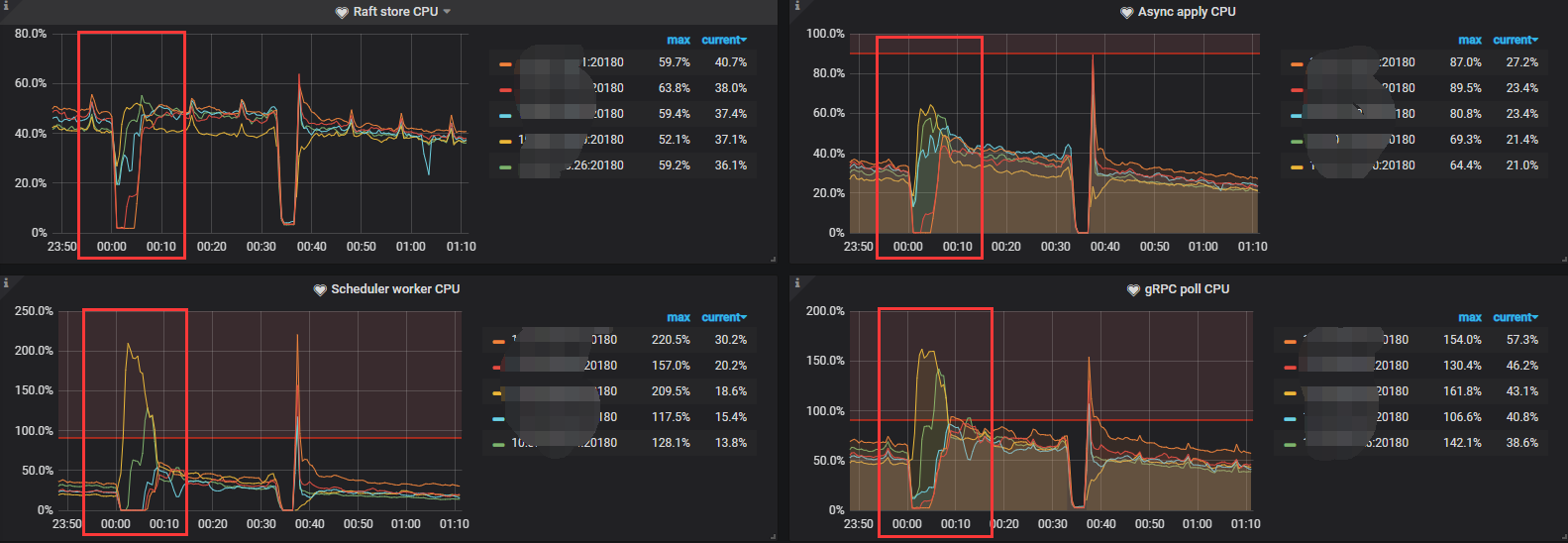
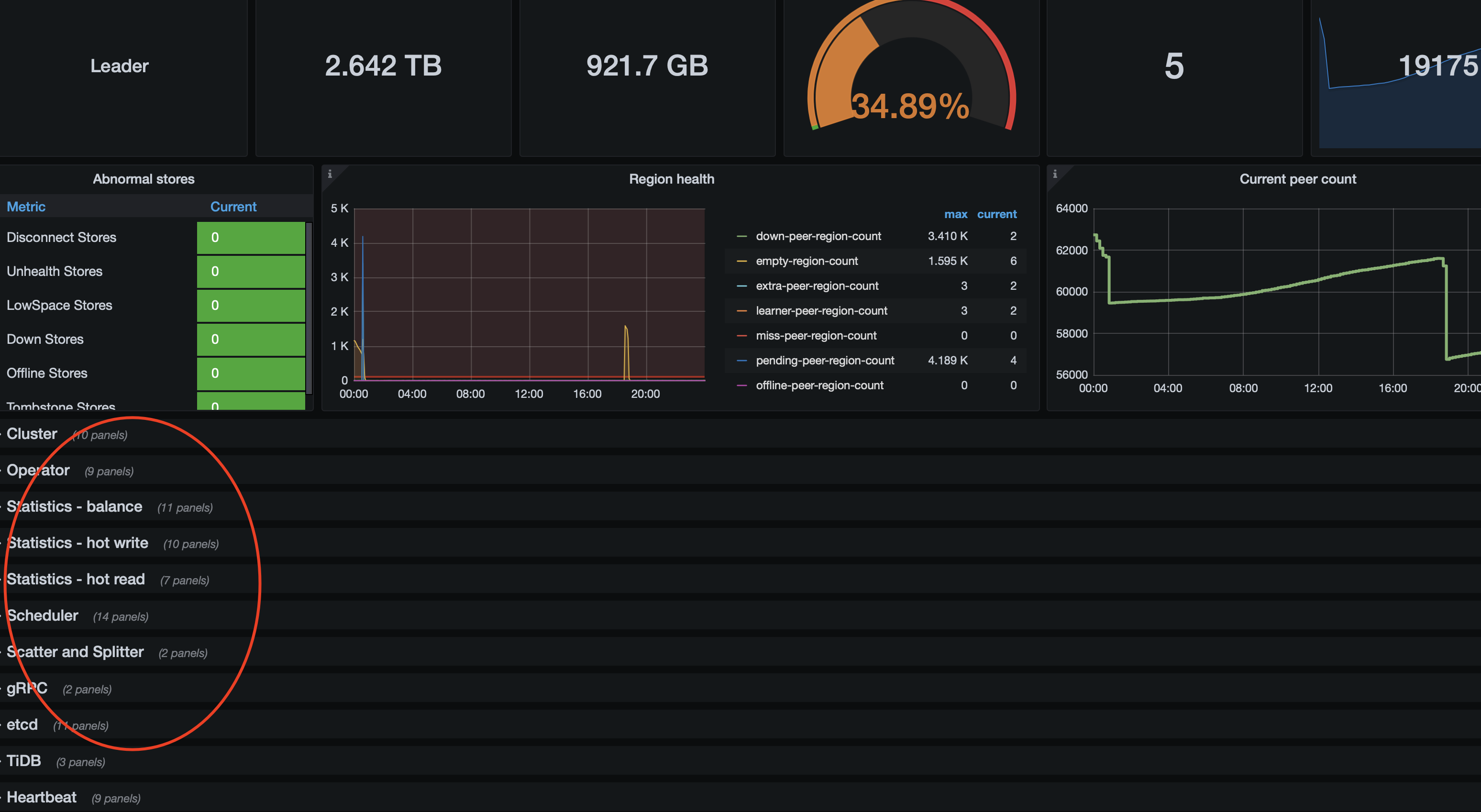
目前已经恢复正常,监控也恢复正常,但是 [Prometheus]中还是有一个节点TiKV_raft_log_lag比较大的问题,感觉Prometheus的数据没有更新过来
【背景】做过哪些操作
报警节点的TiKV日志如下:
TiUP Cluster Display 信息
TiUP Cluster Edit Config 信息
TiDB- Overview 监控
1 个赞
spc_monkey
2022 年1 月 19 日 02:14
2
seiang
2022 年1 月 19 日 04:22
3
spc_monkey:
下面这个帖子有导出监控的方式
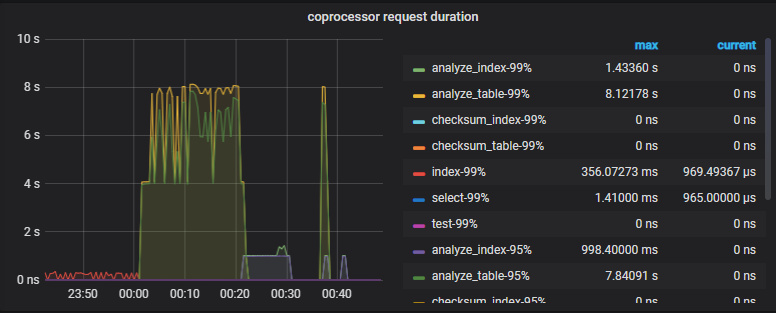
如下是慢查询,正常情况下该insert操作也就3ms左右,现在18s
执行计划:
如下是tikv-details监控面板的导出快照tidb–TiKV-Details_2022-01-19T04_15_18.114Z.json (3.0 MB)
spc_monkey
2022 年1 月 19 日 05:50
4
1、你的是在做什么操作吗? 看集群的region 数量在不断的减少
spc_monkey
2022 年1 月 19 日 05:52
5
如果现在问题还存在,可以先调低一些 scheduler limit(pd-ctl 里 config show all 里的 几个 limit ,调小一些)
seiang
2022 年1 月 19 日 06:32
6
问题是发生在1月18日凌晨00:00~00:40,1月17日上午的时候,drop了几张历史大表;所以region数据在减少;
如下是PD/overview/tikv0detail 的监控:tidb–Overview_2022-01-19T06_29_35.029Z.json (792.3 KB) tidb-PD_2022-01-19T06_27_16.048Z.json (208.2 KB) tidb–TiKV-Details_2022-01-19T06_24_58.401Z.json (2.0 MB)
seiang
2022 年1 月 19 日 06:48
7
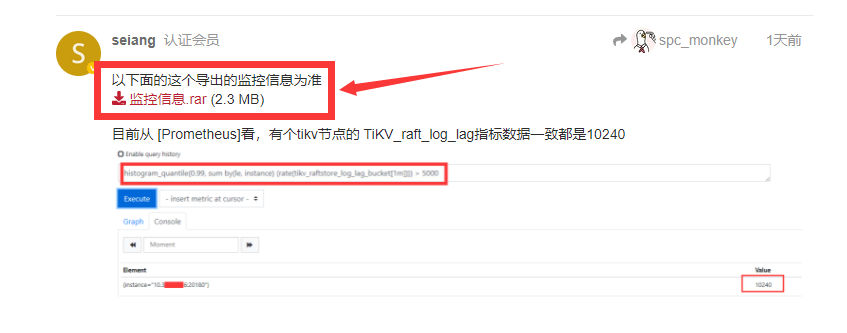
以下面的这个导出的监控信息为准监控信息.rar (2.3 MB)
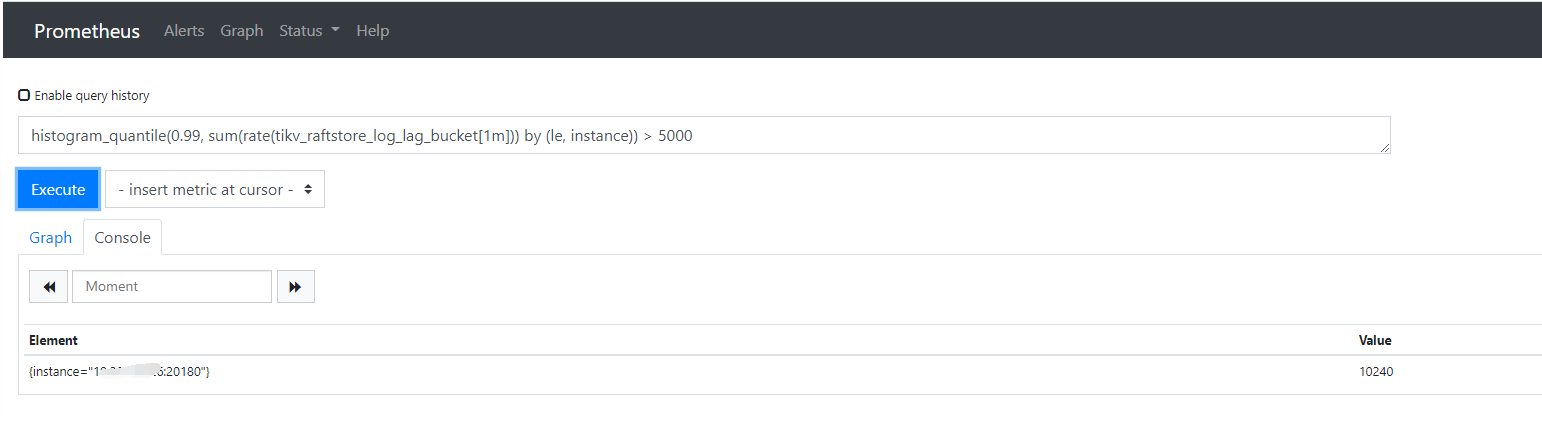
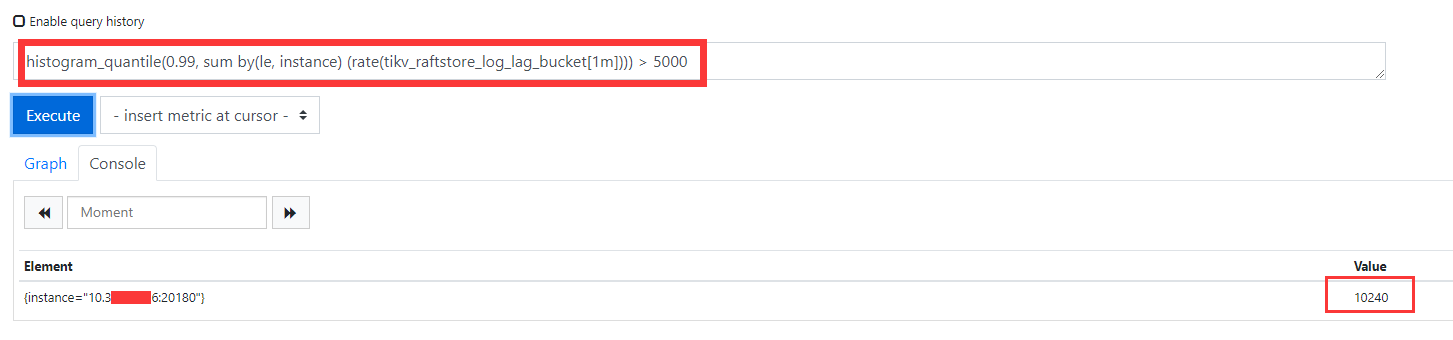
目前从 [Prometheus]看,有个tikv节点的 TiKV_raft_log_lag指标数据一致都是10240
seiang
2022 年1 月 20 日 04:11
8
@spc_monkey 大佬,协助帮忙看看,有分析结果反馈一下,谢谢
着急的话,可以在:我的团队-我的主题-进行加急一下
spc_monkey
2022 年1 月 20 日 07:27
10
你导出的监控都是这样的,我没法看(你需要等他都打开之后,再导出,不然导出的信息都是空的)
seiang
2022 年1 月 20 日 07:36
11
你好,以这个里面的监控为主,这个里面的监控是完整的
spc_monkey
2022 年1 月 20 日 07:48
12
按我理解你有2个问题:1、这次 写入慢的问题 2、raft—log-lag 的问题
spc_monkey
2022 年1 月 20 日 08:06
14
第一个问题,应该是调度导致的 store 4 太忙,导致对应时间的 store 处于了一个不太可用的状态(un reachable):这里说的调度都是 merge 的调度,所以和你说的 drop 操作其实匹配的「我需要你看看 pd-ctl config show all 的结果)
spc_monkey
2022 年1 月 20 日 08:09
15
第二个问题:raft-log 一直是 10240 的问题,嘿嘿,我也不知道,不过,我建议你根据 pd 的日志(或 tikv 的日志)找到对应的 region id,然后 用 pd-ctl region 命令,看一下这个 region 的状态
spc_monkey
2022 年1 月 20 日 08:10
16
或者你提供我一下 这2个 日志,然后告诉我一个 region id(好像不用,tikv 日志里应该有记录)
seiang
2022 年1 月 20 日 08:31
17
tikv.log_26.tar.gz (3.1 MB) tikv.log_tar.gz (10.1 MB)pd配置.txt (5.7 KB)
seiang
2022 年1 月 21 日 06:58
18
@spc_monkey 大佬,分析的咋样,有结果吗
spc_monkey
2022 年1 月 21 日 08:14
19
system
2022 年10 月 31 日 19:25
20
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。