是的 在prometheus 机器上能通过curl http://ip:9100/metrics获取到所有节点的数据, 我所有机器防火墙都是关闭的
是的 在prometheus 机器上能通过curl http://ip:9100/metrics获取到所有节点的数据, 我所有机器防火墙都是关闭的
从你先前的描述来看,prometheus 数据显示时好时坏,而在 prometheus 机器上能通过curl http://ip:9100/metrics获取到所有节点的数据, 怀疑还是 prometheus 和其他组件之间网络不稳定,有没有网络丢包的现象呢?
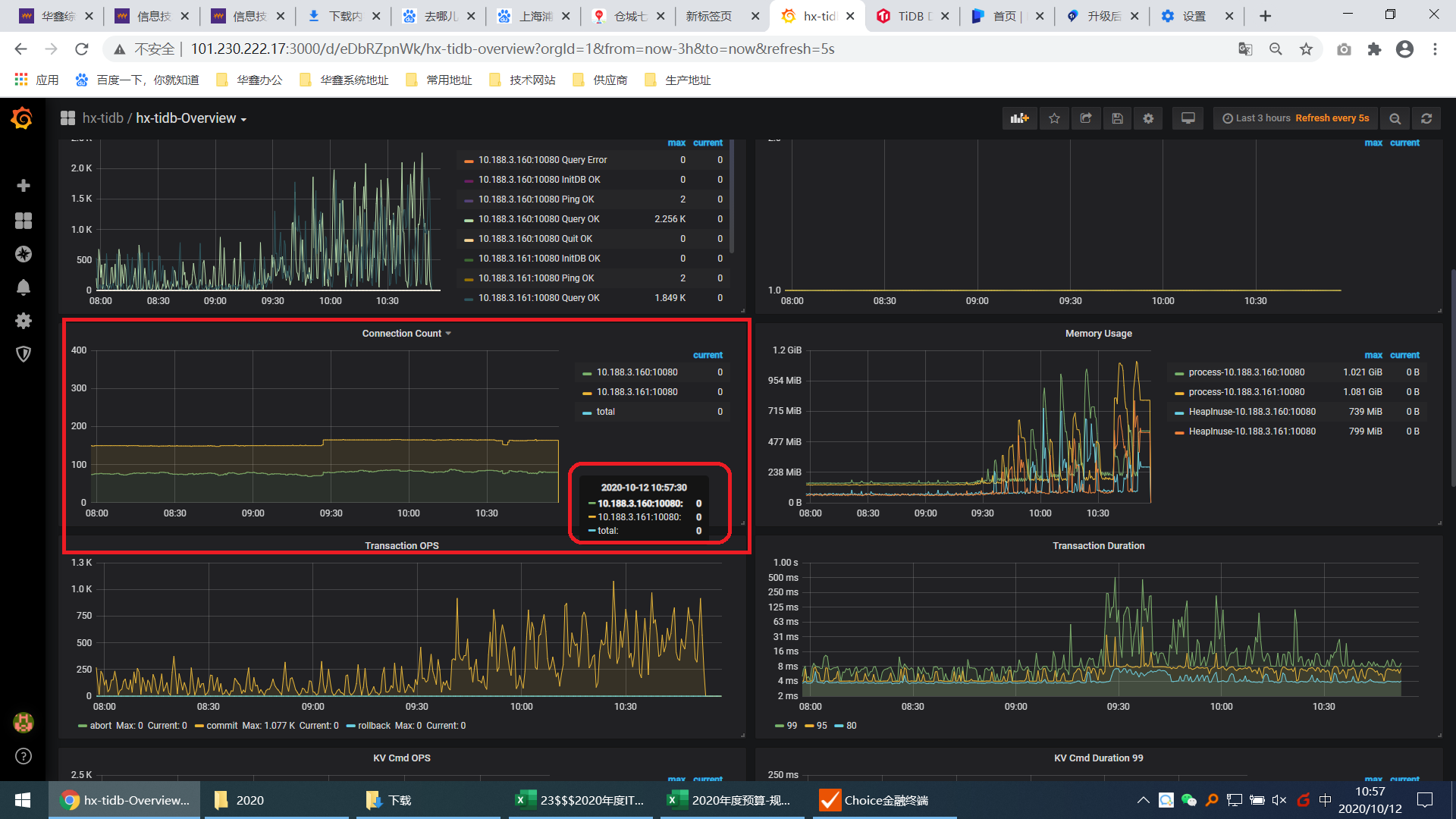
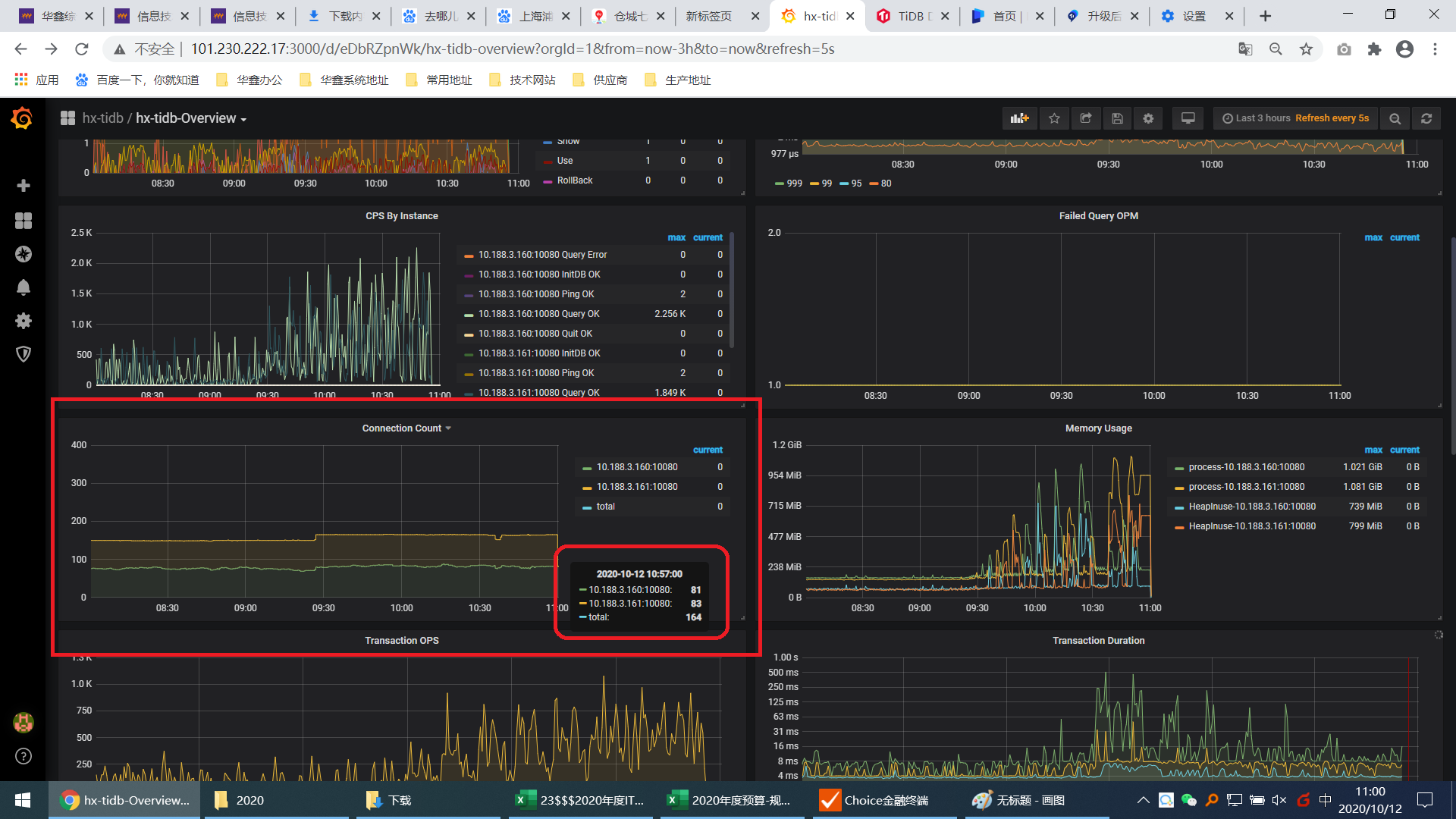
展示图形的目前我观测下来就询current当前时段没有数据,过了这个时间段数据下一次刷新又可以展示上一个刷新周期的数据,证明数据是已经到了promtheus;
网络ping了没有丢包,都是在一个交换机上的
从之前的拓扑结构来看,prometheus 、grafana 和 drainer 都部署在一台主机上,麻烦检查下该台机器负载情况,看下有没有可能是负载太高导致监控数据展示有延时。
负载都不高的 cpu平均利用也就不到10%
你这边是规律性的一个时间周期内看不到最新的监控数据吗?如果是的话时间间隔大概是多少呢?
可以检查一下浏览器本地时间与集群监控服务器的时间是否一致
应该不是时间的问题 是在promtheus里面查询指标的当前数据是空的 而历史数据是存在的
目前集群使用的 tiup 使用的是什么版本?可以使用 tiup --version 查看。
v1.2.0 tiup
go version :go1.3
git branch:release-1.2
githash:la4fbe7
当时扩缩容 prometheus 和 granfa 时用的都是这个版本的 tiup 吗?
是的 我是先用tiup update --all 升级后 在从v4.0.4升级tidb到4.0.7的
prometheus 的部署目录下有一个 conf/prometheus.yml 是否方便提供下?
另外 curl {pd_ip}:{pd_port}/metrics 试试呢
数据都能返回回来
prometheus.yml (7.7 KB) 不好意思最近忙其他事情
我看了下 prometheus.yaml 没问题,这个 curl 命令是在 prometheus 那台机器上执行的吗?要试试所有的 pd 看看是不是通的