- 能否麻烦您反馈下具体的修改过程?
- 反馈下修改了哪些配置文件,多谢。
1.修改了DM master中的inventory.ini文件中dm_worker_servers字段mysql_host的值为新上游数据库地址,并执行了ansible-playbook /home/tidb/dm-ansible/rolling_update.yml。发现DM worker服务器下的/home/tidb/deploy/conf/dm-worker.toml文件内容已经更新为新数据地址。
2.尝试stop-task xxxx,提示没有这个任务;尝试刷新任务列表,提示超时;尝试start-task xxxx,提示"[code=38008:class=dm-master:scope=internal:level=high] grpc request error: rpc error: code = DeadlineExceeded desc = context deadline exceeded"。尝试关闭集群、启动集群,观察DM worker日志,发现task会被自动resume,之后提示无法连接已经失效的数据库地址。进入dmctl中运行query-error,发现任务都是paused状态,尝试resume-task xxxx,提示超时。
3.在dmctl中运行query-status,返回空值。
4.DM master能够通过ansiable-playbook控制DM worker进程启停,但是无法通过query-status获取DM worker任务列表,从而无法刷新并应用新的数据库连接地址。
5.DM master、worker之间能互ping、telnet端口互通、ssh能够免密登录(tidb用户),安全组没有任何限制。
DM worker 中的配置信息没有修改吗?

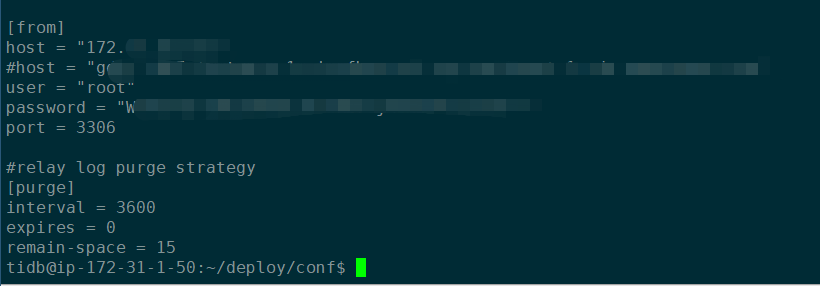
从DM master日志中发现:[2020/09/07 03:29:48.712 +00:00] [ERROR] [server.go:1308] [“create FetchDDLInfo stream”] [worker=172.31.1.50:8262] [error=“[code=38008:class=dm-master:scope=internal:level=high] grpc request error: rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp 172.31.1.50:8262: connect: connection refused"”]
。但是通过从master telnet 172.31.1.50 8262,是正常的。


- 再检查下有没有开启防火墙,可以考虑先关闭
- 可以重新试试生成密码,再重启dm-worker试试
1.DM master、worker ufw防火墙已经确认关闭。
2.使用dmctl -encrypt xxxx重新生成密码,配置到DM worker上,手动使用启停脚本启停DM worker进程,从DM worker日志上看,worker仍然连接已失效的数据库,提示超时。
3.修改DM master上inventory.ini中相关密码字段,使用ansible-playbook /home/tidb/dm-ansible/rolling_update.yml使配置同步,从DM worker日志上看,worker仍然连接已失效的数据库,提示超时。
4.目前通过观察DM master、worker日志,感觉应该是master和worker之间通信产生了问题,master不能控制worker,worker无论如何操作,它都自动读取已经提示超时的错误任务,如果想要应用配置,必须要把worker的task停止下来,不知道有没有什么方法可以直接控制worker而不通过master。
master的任何dmctl操作,均不能在worker的日志上显示(ansible-playbook启停集群除外),说明命令没有发送到worker,所以还请向这个方向提供思路,谢谢!
请问,你是按照步骤修改的吗?停止dm-worker后,task肯定停止了。
- 停止 dm-worker
- 修改 ip
- 启动 dm-worker
- 检查 dm worker 日志里的配置是否是正确的,多谢。
这个我不太确定了,应该是没有停task,直接修改的配置,之后执行的rolling update。我想着rolling update有stop start集群的功能,所以就没有单独stop task。请问想现在这个情况还有补救方法么?谢谢!
这个我不太确定了,应该是没有停task,直接修改的配置,之后执行的rolling update。我想着rolling update有stop start集群的功能,所以就没有单独stop task。请问想现在这个情况还有补救方法么?谢谢!
可以按照上面的方法再试一次吗? 重启下dm-worker,之后反馈dm-worker的日志,多谢。
1.使用ansible-playbook stop.yaml停止dm集群。
2.确认worker中dm-worker进程结束后修改/home/tidb/deploy/conf/dm-worker.toml文件中host字段值。
3.通过运行/home/tidb/deploy/scripts/start_dm-worker.sh启动dm-worker进程,日志截图如下:
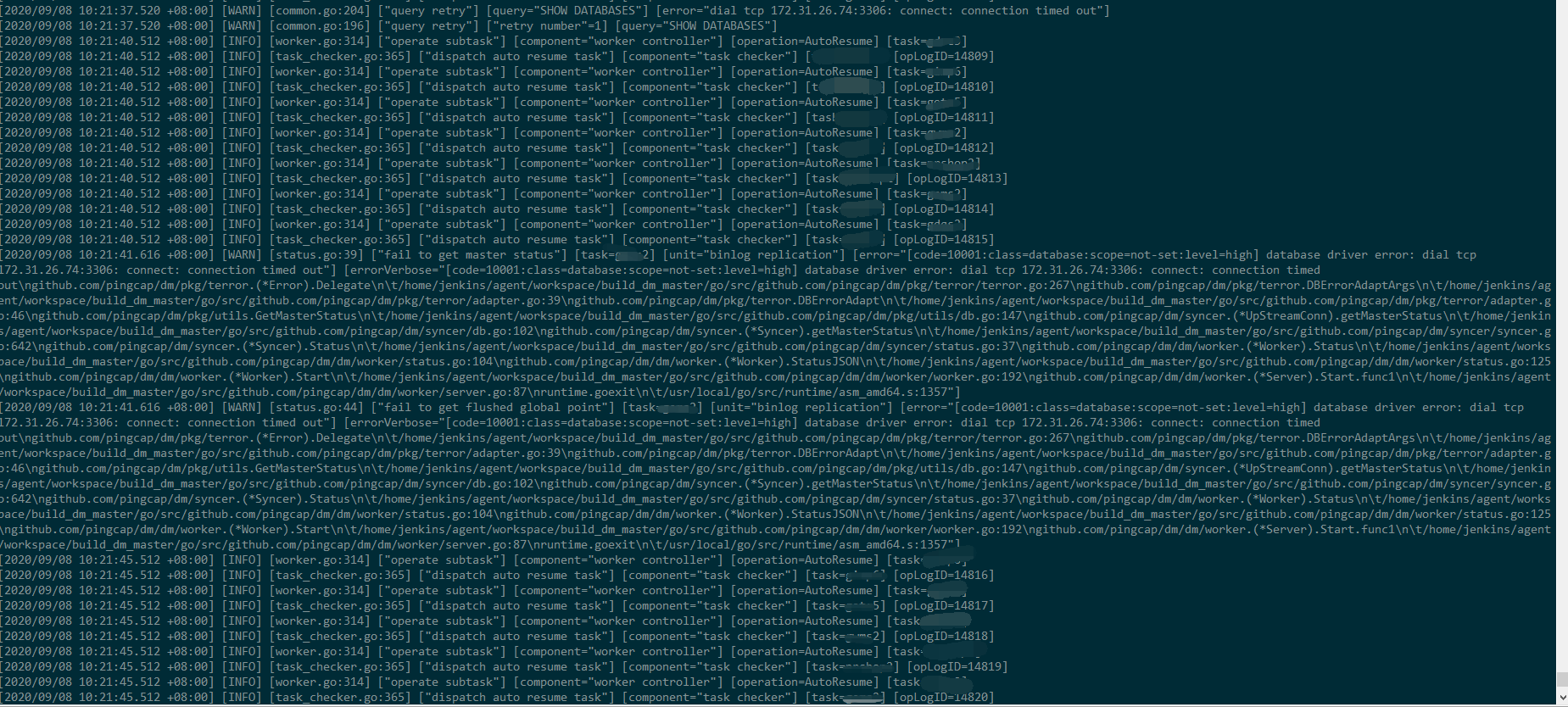
4.日志截图中172.31.26.74为已经失效的上游mysql地址,配置文件中已更新为域名。
您好,我刚才把DM版本从v1.0.5升级至v1.0.6,目前同步已经恢复,DM运行正常。
感谢回复
谢谢您!
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。