- 从9.8 的日志来看 tikv 没有 slow-query 表,但是 tidb 中在 15:27 有慢的日志,这个比较奇怪。 确认 tikv 时间是相差12小时吗?这些是正确的tidb和tikv 对应的日志吗?
- 这个集群是 4.0 的集群,和 9.1 号 有大查询导致问题的不是同一个集群吧? 方便发一下监控,我们再查下吗?
over-view,tidb,detail-tikv 在9.8 号这个时间段的监控,多谢。
1:日志是从tidb的dashboard下载的,时间肯定是对的,我看了集群的时间都是一致的
2:生产的是3.0,本地是4.0,但是都出现了同样的问题,监控截图在回帖上面有的,那个时间段也是有这个SQL问题。
- 这个监控是当时查看的 3.0 的正式环境吧,查看到的问题是由于有大 sql 扫描了很多索引导致
- 现在您反馈本地 4.0 环境没有这个大 sql,也会慢,但是查看 tikv log 没有 slow-query,所以请帮忙反馈下 9.8 号 15:27 这个时间段的监控信息,辛苦。
查看 9.8 号 15:27 出问题时间段的监控信息
- 查看 tidb duration 信息
- tikv 99 duration
- 查看 coprocessor duration 信息
- 查看耗时还是在 index 这里
- 感觉和之前分区的差不多,可以找一下,感觉应该还是有大sql在出问题附近。


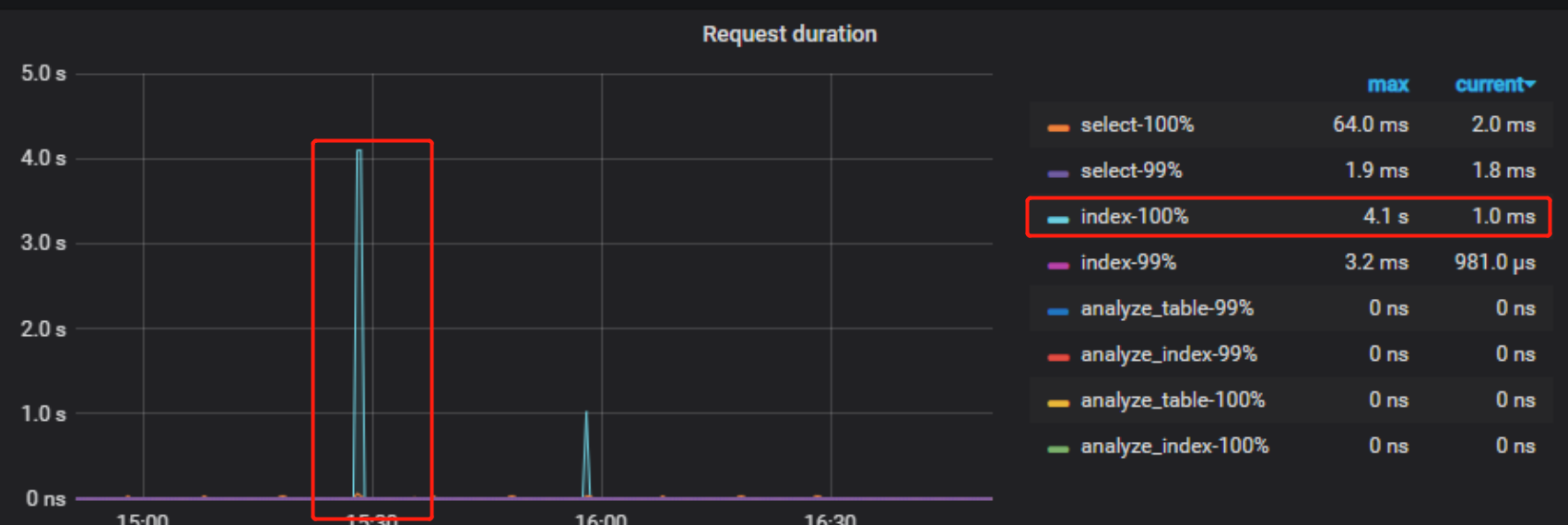
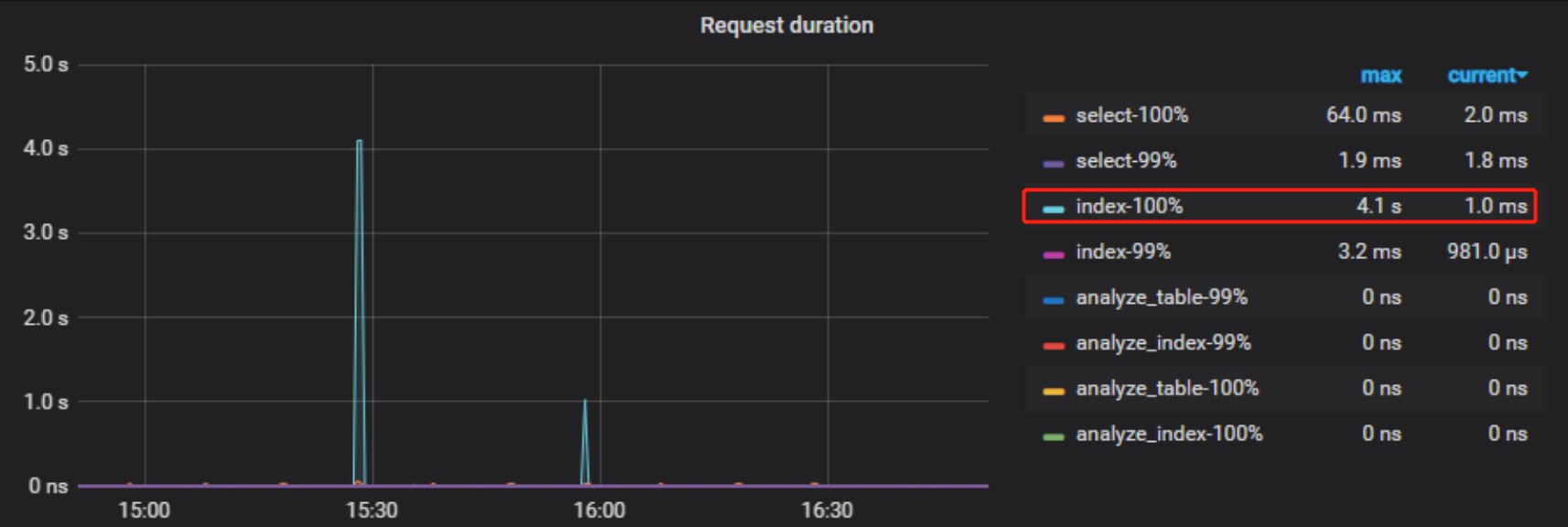
但是这个时间段的慢SQL也发了,没有其他的大SQL,而且本地就我一个人在做用,没有其他的大SQL了
我今天查看了下,觉得和之前不一样的地方在于,上次的监控里,coprocessor是在问题发生时刻,index 才多的,这次的监控感觉一直很多。 并且问题发生时,不但读流程,写流程也是变慢了。 还有一点是 IO 在问题发生的时间段有一个突增,达到了 50% 多,应该在这个时间段是有一个占用大量 IO 的操作。 猜测一下,不知道是不是这个时间段并发突然增多了呢? 因为日志里确实没有某个大sql
这个时间段一直在做这个SQL的并发测试,所以应该是一直很多,只不过测试到这个时间点了,就发生了慢SQL,之前并没有,但是测试一直没停。另外系统那个时间段只做了那个SQL的并发测试,其他都没运行
好的,我们再看看是否还有其他信息。 另外,这个问题多次出现的话,其他出现的时候,是否能再 tikv.log 日志中找到 slow-query 的信息?
我再测试一次看看有没有,正式的3.0.8好像就没有
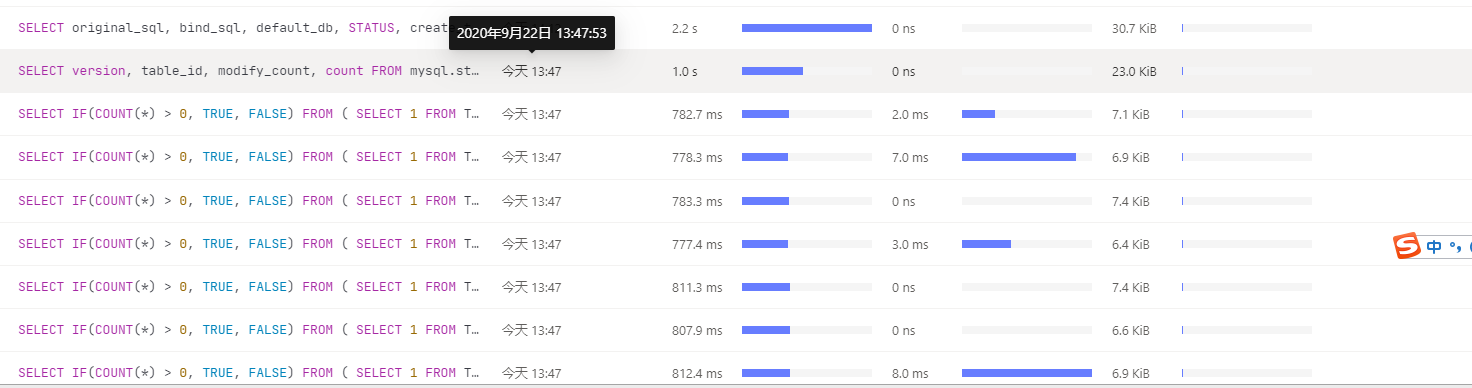
好的,我们分析后会尽快答复
如果你们有tidb的集群,我可以提供测试脚本,这种情况基本都是肯定会出现的,脚本是python测试的
- 从日志看,有可能是压力大,另外日志比较少,没法搜索是否有slow-query 的日志。
- 集群的硬件和软件环境都不一样,不一定可以复现和您一样的内容,如果方便的话,提供可以访问的监控链接,我们查看下,比较方便,也方便其他同事查看,多谢。
收到,感谢