Tidb版本:2.0.rc4
已经合并结束,所以关闭了合并(是否需要一直开启merge?策略设置的是合并空的region),以下是pd的配置
» config show
{
"max-snapshot-count": 3,
"max-pending-peer-count": 0,
"max-merge-region-size": 0,
"max-store-down-time": "30m0s",
"leader-schedule-limit": 32,
"region-schedule-limit": 6,
"replica-schedule-limit": 4,
"merge-schedule-limit": 0,
"tolerant-size-ratio": 2.5,
"schedulers-v2": [
{
"type": "balance-region",
"args": null
},
{
"type": "balance-leader",
"args": null
},
{
"type": "hot-region",
"args": null
},
{
"type": "label",
"args": null
}
]
}
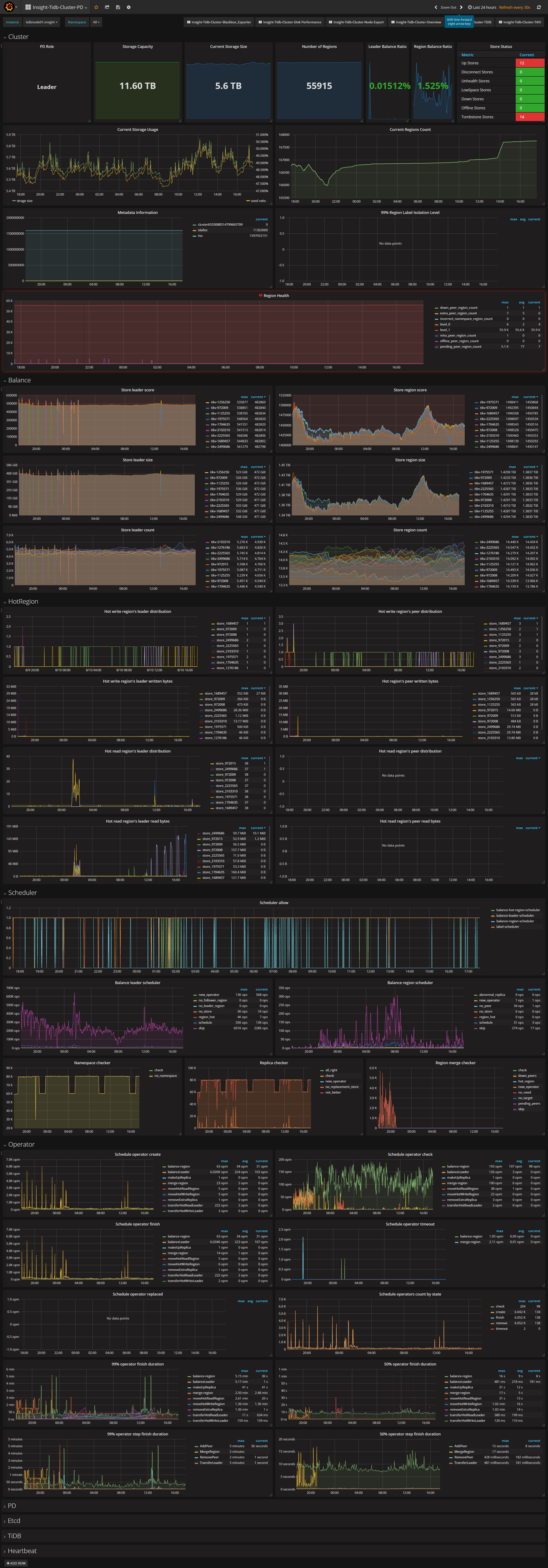
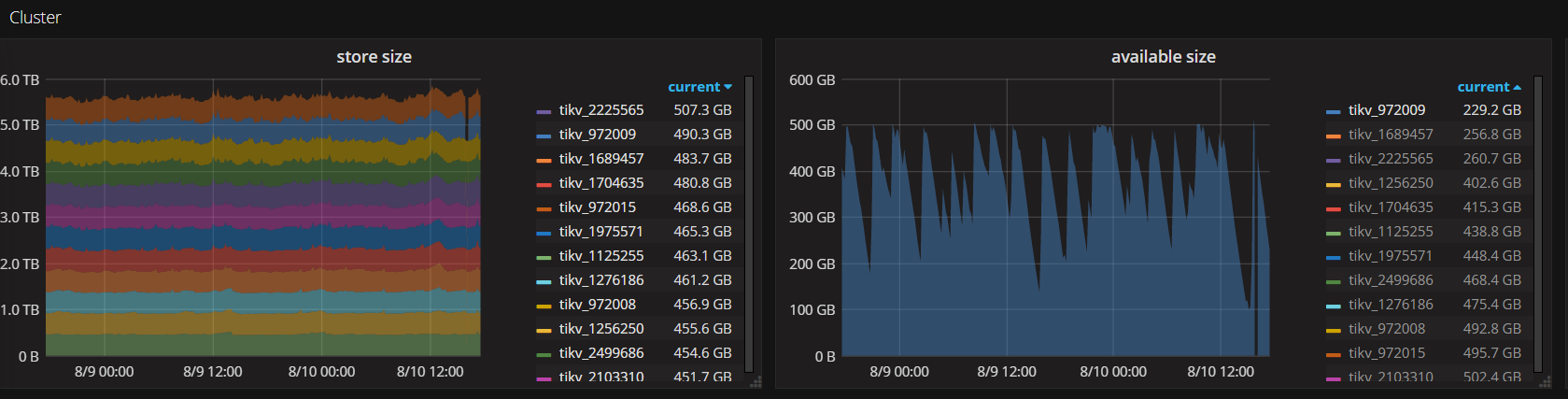
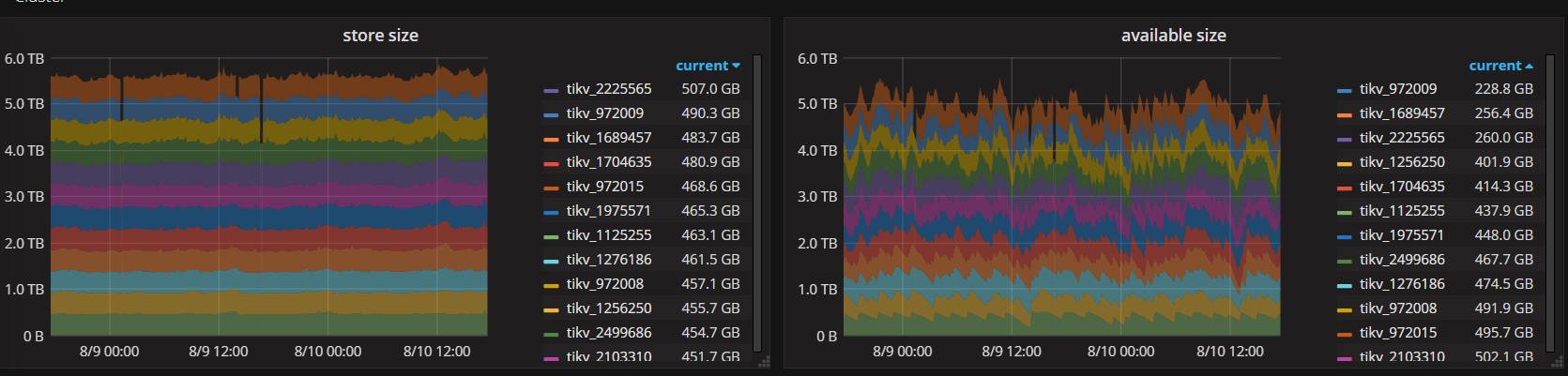
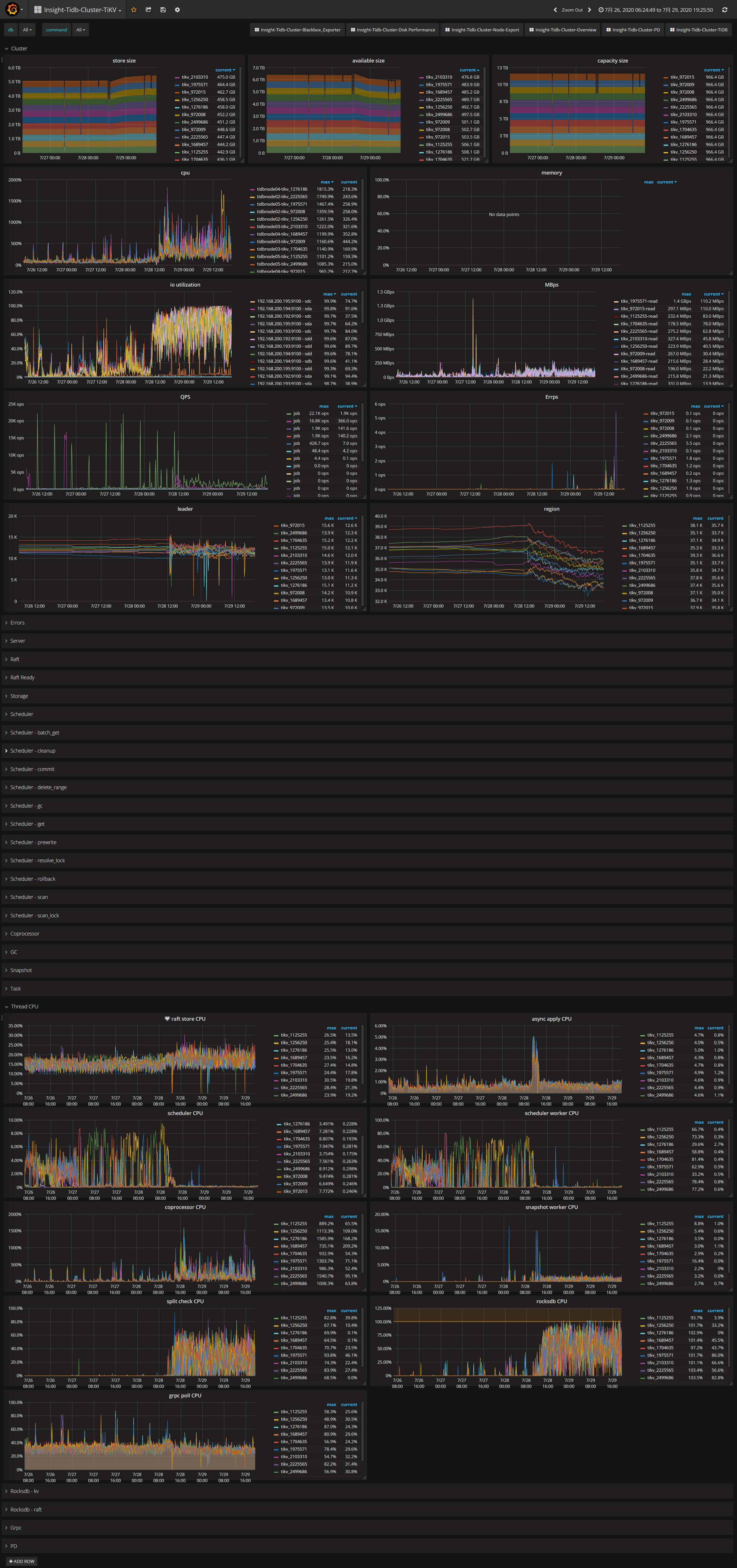
目前发现的问题:
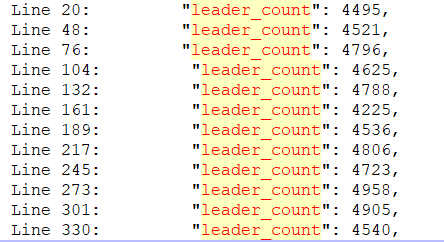
tikv节点的容量,不稳定,升级前容量是平滑得,空间稳定,没有变动,想知道怎么去排查定位问题?
以下是截图,需要日志或者别的信息可以补充,麻烦啦~~
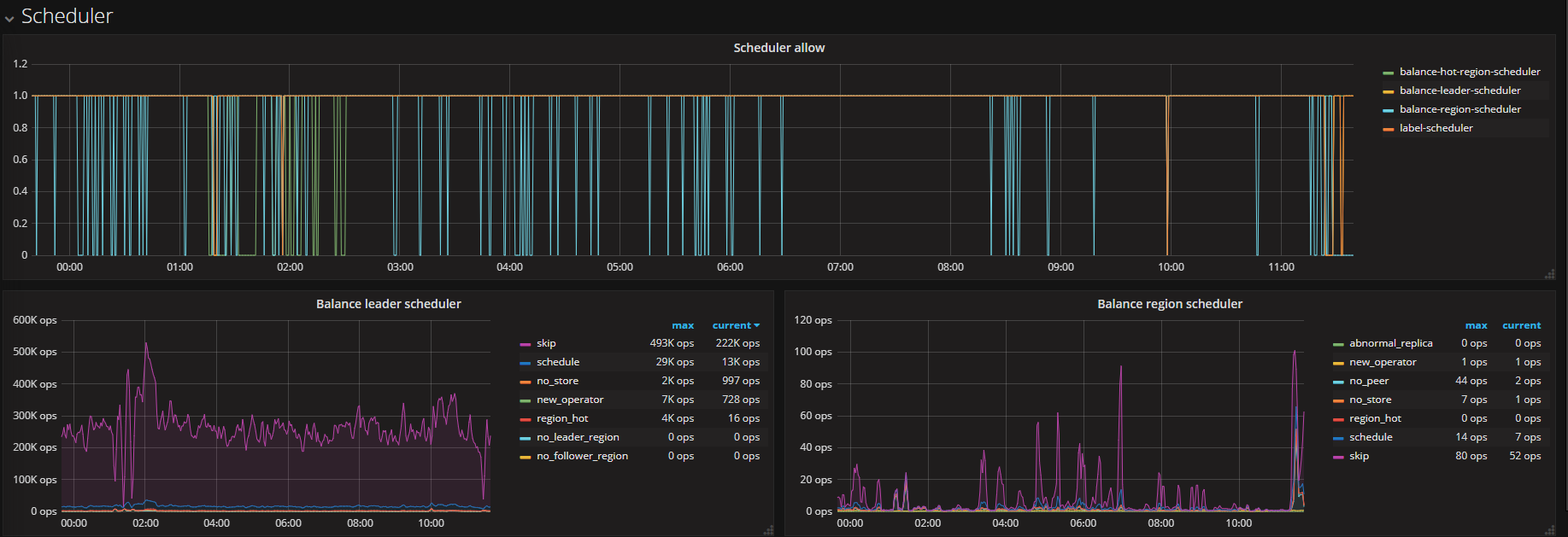
PD截图:
Tikv的截图:
下面是整体12个节点
补充:
这张图包含升级前与后tikv的走向,28号中午12点升级,1点开启merge region
Tidb的小版本,就是2.0 RC4,,,
上传文件,store信息 (9.1 KB)
8月10号,12点没有开启region merge,region merge在 8月9号21:00已经关闭了
请问您说的是 8月10号12点,还是 升级当天(7月28号)12点的监控?
最近涉及到数据中心的搬迁,所以打算等搬迁完成后再升级到3.0
这两天查询资料,参阅帖子与这个类似,业务无读写情况下,tikv负载仍然很高,磁盘IO也几乎达到瓶颈 - #2,来自 Kay-PingCAP
"max-merge-region-size": 50
"merge-schedule-limit": 6
"max-merge-region-keys":2000
目前也已经关闭。将"max-merge-region-size": 设置为0
» config show
{
"max-snapshot-count": 3,
"max-pending-peer-count": 0,
"max-merge-region-size": 0,
"max-store-down-time": "30m0s",
"leader-schedule-limit": 6,
"region-schedule-limit": 6,
"replica-schedule-limit": 4,
"merge-schedule-limit": 6,
"tolerant-size-ratio": 2.5,
"schedulers-v2": [
{
"type": "balance-region",
"args": null
},
{
"type": "balance-leader",
"args": null
},
{
"type": "hot-region",
"args": null
},
{
"type": "label",
"args": null
}
]
}
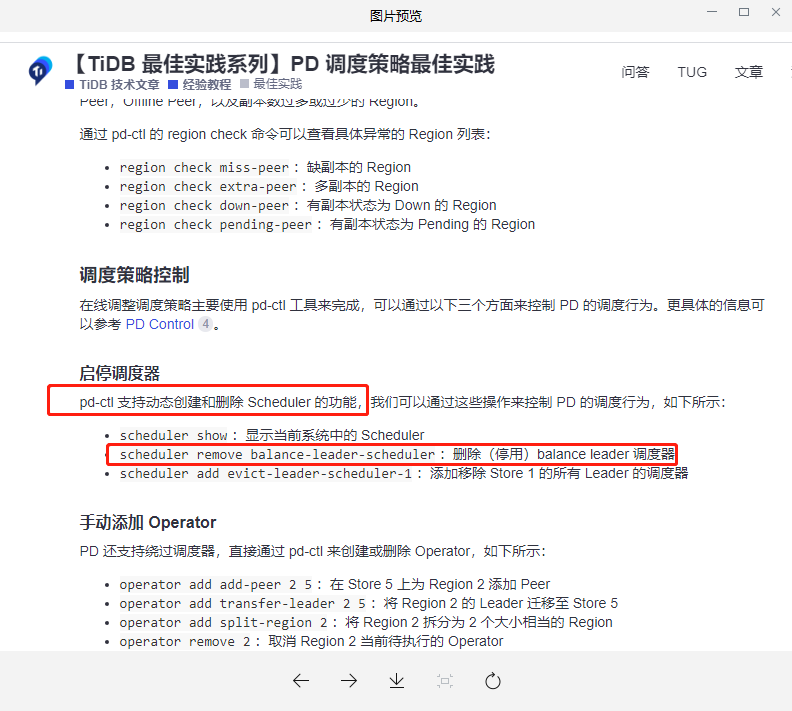
请问一下。。我执行了scheduler remove balance-region-scheduler 后,怎么把调度器添加回来?
按照官方的文档,本意是禁用后观察效果,再添加回来,,结果无法添加了。。
以下的信息,没有这个参数
» scheduler show
[
"balance-hot-region-scheduler",
"label-scheduler"
]
» scheduler add balance-region-scheduler
add a scheduler
Usage:
add [command]
Available Commands:
evict-leader-scheduler add a scheduler to evict leader from a store
grant-leader-scheduler add a scheduler to grant leader to a store
shuffle-leader-scheduler add a scheduler to shuffle leaders between stores
shuffle-region-scheduler add a scheduler to shuffle regions between stores
Additional help topics:
Use "help add [command] " for more information about a command.
»
使用的版本:
[tidb@localhost ~]$ ./tidb-deploy/resources/bin/pd-ctl -V
Release Version: v2.0.0-rc.4
Git Commit Hash: e221ffb59f7b3433ee2e0a617f616dc92b02d007
Git Branch: release-2.0
UTC Build Time: 2018-03-31 06:49:39
是不是因为pd-ctl版本比较老? 看到官方资料。pd-ctl ,3.0的版本支持add,能否用3.0的pd-ctl连接到现有集群进行操作,是否有风险。。。。
嗯,等物理环境稳定了,会逐步升级,然后测试过使用pd-ctl,v3.0.16成功将删除的scheduler添加回来
system
2022 年10 月 31 日 19:16
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。