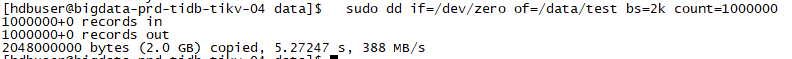建议是按照 https://docs.pingcap.com/zh/tidb/stable/hardware-and-software-requirements 配置文件来,如果您的可以满足业务要求,性能要求不高,或许可以使用
从这些现在是能说明磁盘有瓶颈吗
disk latency 已经说明了,估计是高峰期吧,盘就变慢了
这种情况下,是有限换ssd合适还是增加tikv节点合适?如果是增加tikv节点,现在也不确定需要增加多少节点。
同步慢得无法忍受
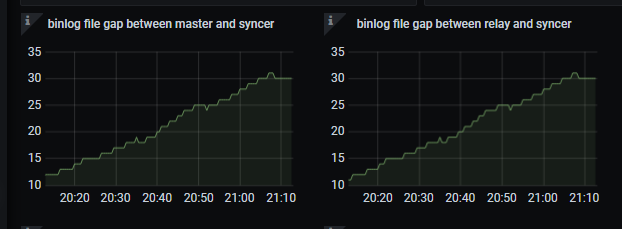
建议先将磁盘换成 SSD 磁盘,目前看磁盘瓶颈比较明显,扩容 TiKV 节点效果可能不明显,因为扩容涉及 region 的迁移调度,这对于磁盘也有一定要求。
周末的时候找同事确认了磁盘的类型,确认磁盘是SSD,只是因为虚拟机化之后在os上分不清是否为ssd,所以昨天想通过扩容tikv来解决这个问题,tikv从6个节点扩容到12个节点,但很明显,同步还是即为缓慢。
另外,我们还有另外一张表的同步任务,数据量级和这张表差不多,但是同步还是非常快的,如果是磁盘性能问题,2个任务应该都会很慢吧?
另外一张表的binlog情况:
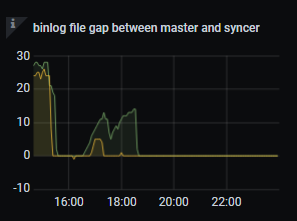
但这个任务在同个时间段还是越来越慢
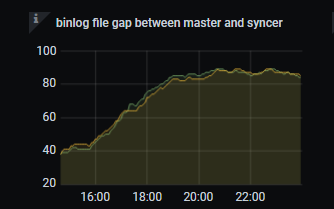
- 您的意思是 DM 不同的 task 任务向同一个 tidb 集群同步数据吗?
- 如果是不同的两个 task 任务,请问 sync 的 count 值相同吗?
- 麻烦先反馈这两个 task 任务的同一时间段的完整监控,多谢。
1、在同个DM集群同个work进程,不同的task任务(任务上游是同个mysql库,分库分表)向同一个tidb同步数据。
2、sync的值默认都是16,有问题的task现在改成64,效果是完全一样的
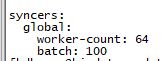
3、如下:
两张表的大小差不多,都是在5000万记录数左右

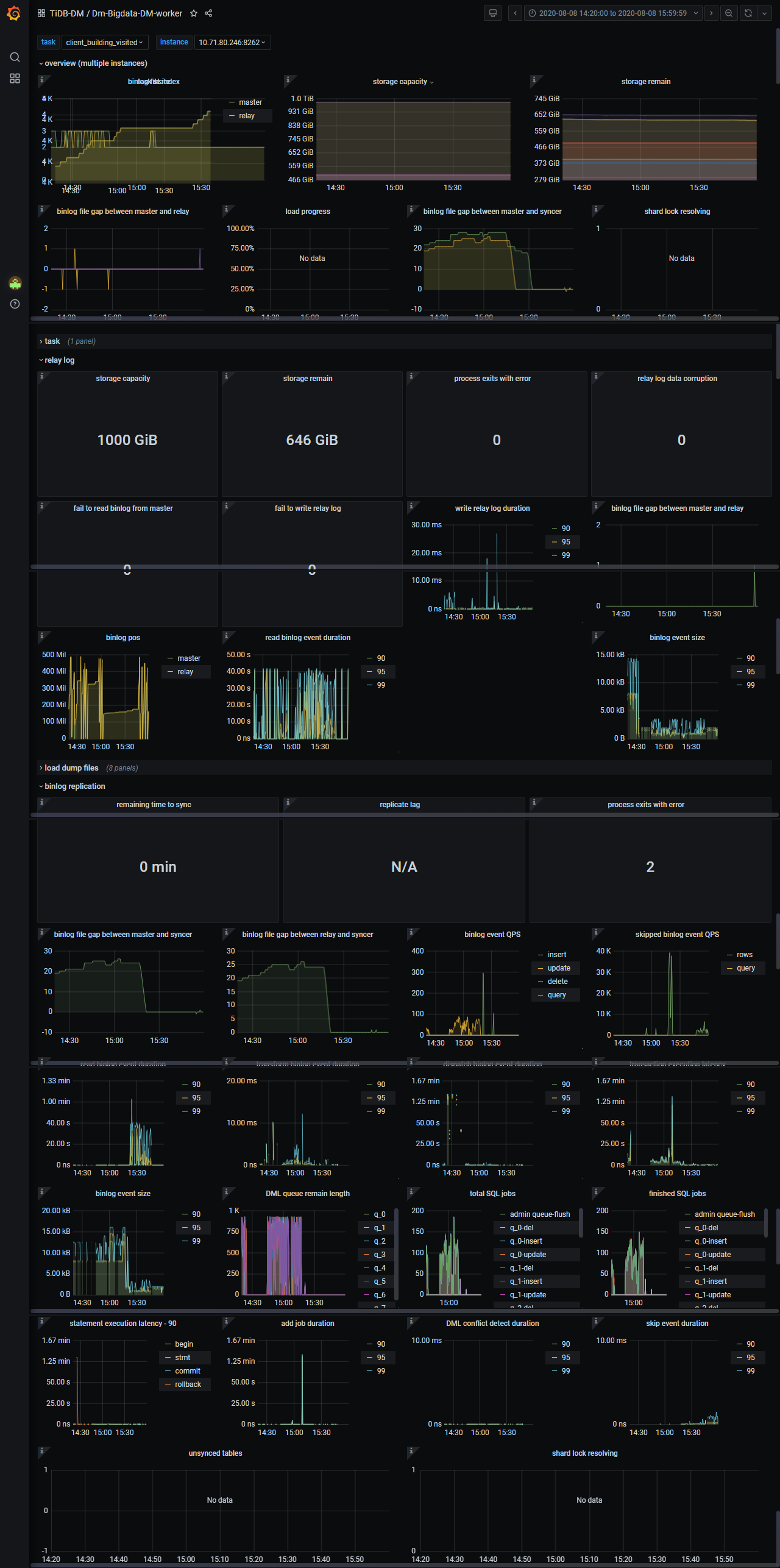
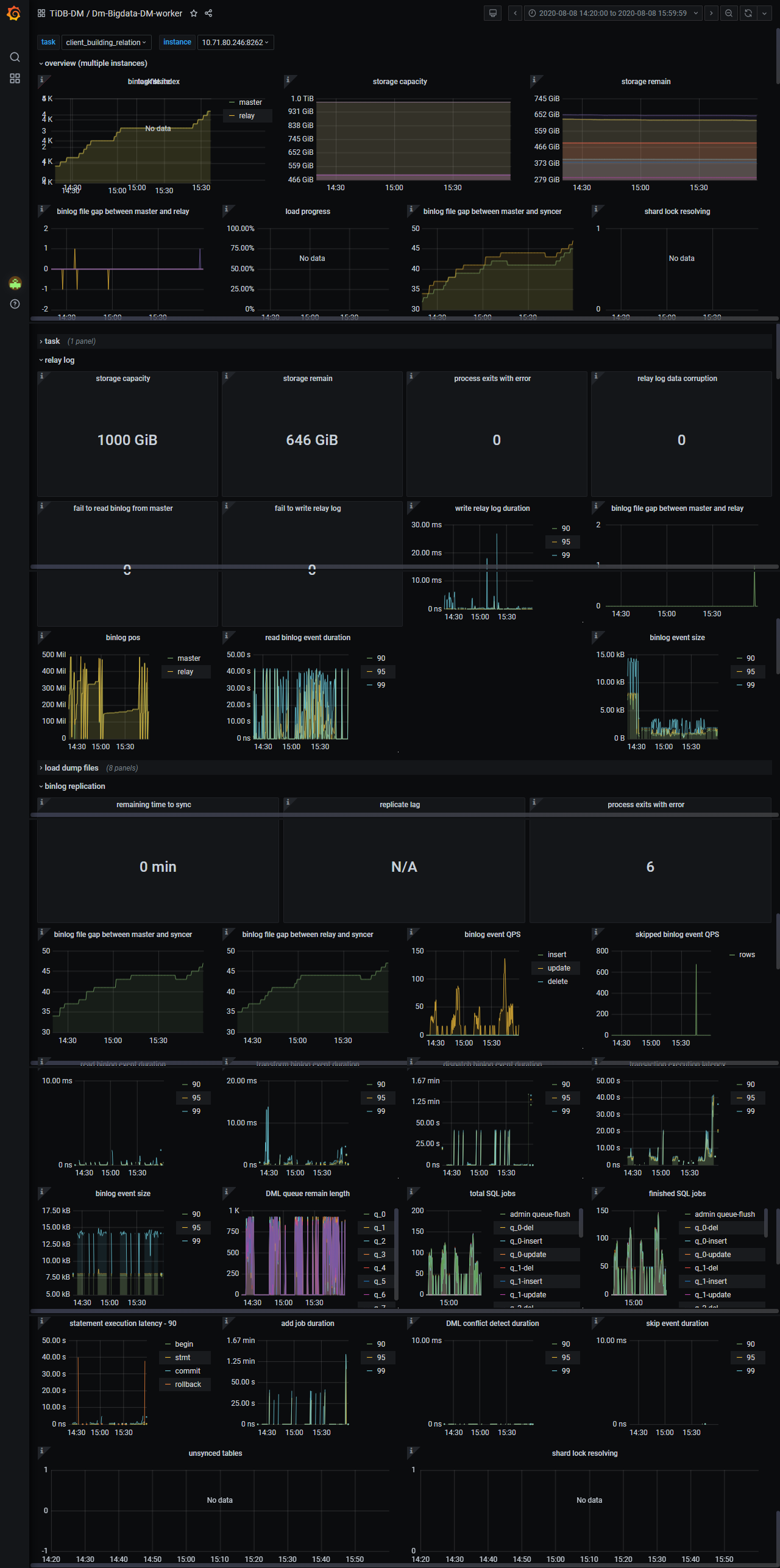
1.两个 task 其实都慢的,只是正常的那个,在 binlog file 15 点多快速追上来的时候,其实差不多都是 skip 掉了,你可以看到监控有很多 skip,应该是这个任务同步的库,有很多表过滤掉了。
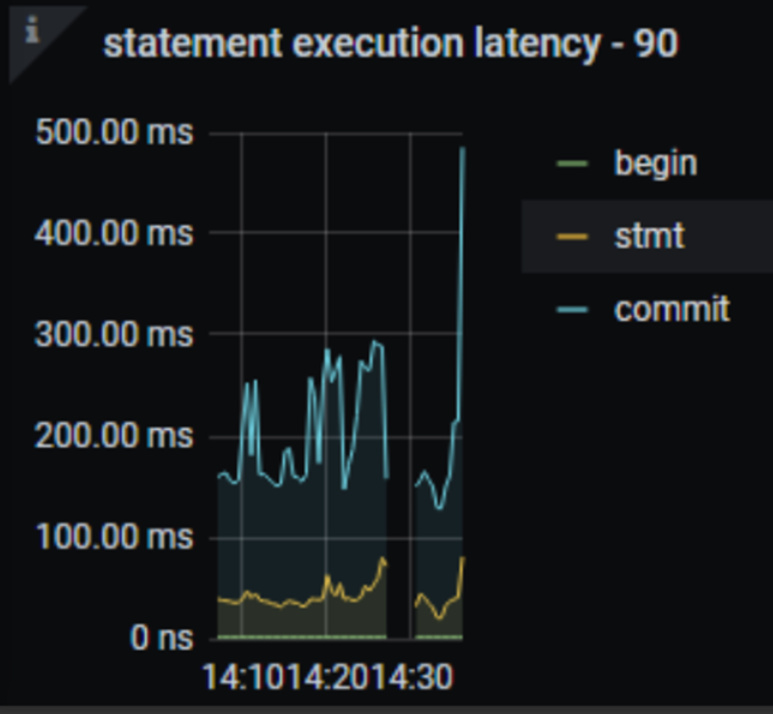
2.两个应该都堵在下游同步上了,DML queue remain length 满的、transaction execution latency 到几十秒了
那这个问题是否还有其他思路?我们的磁盘确定是SSD的了
- 盘如果是 ssd 的,但是虚拟化了,可以看下虚拟化上盘的性能是否有降低。
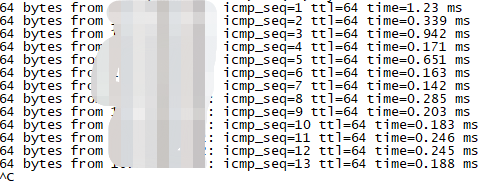
- 可以ping一下 DM 到 tidb 的网络是否有延时,导致同步日志慢。