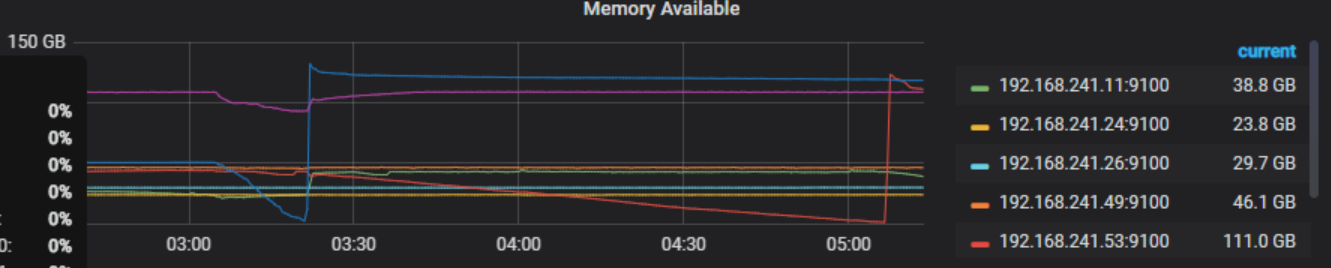
出现这种异常特别是在凌晨的3-5点之间
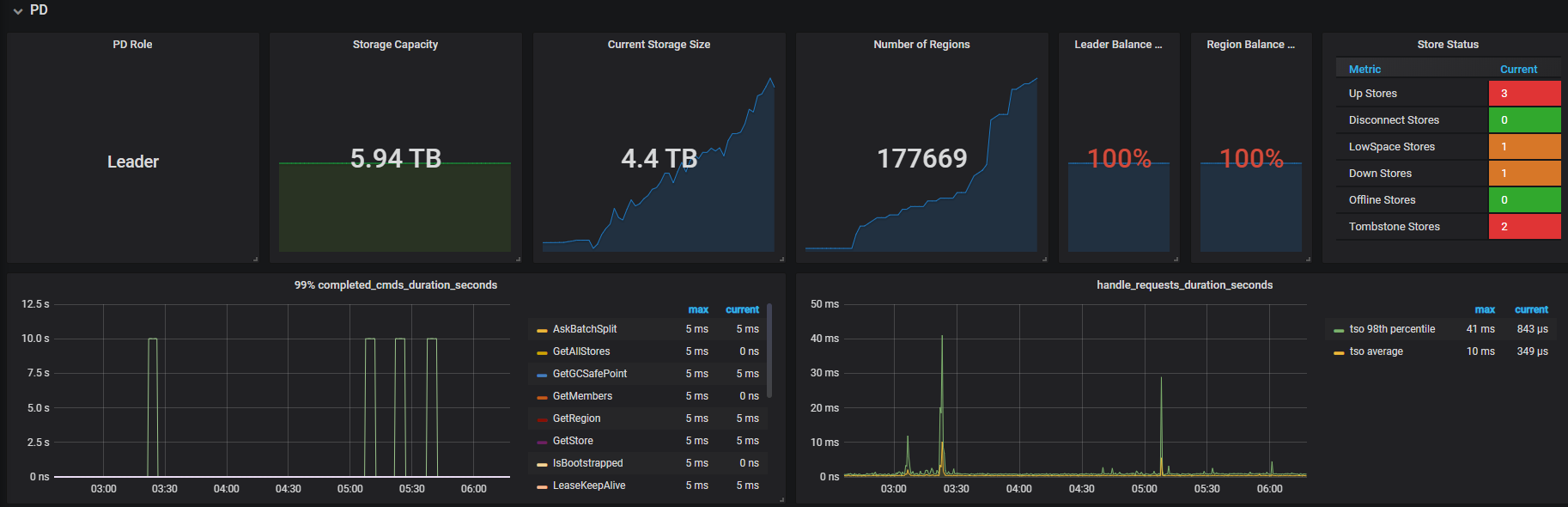
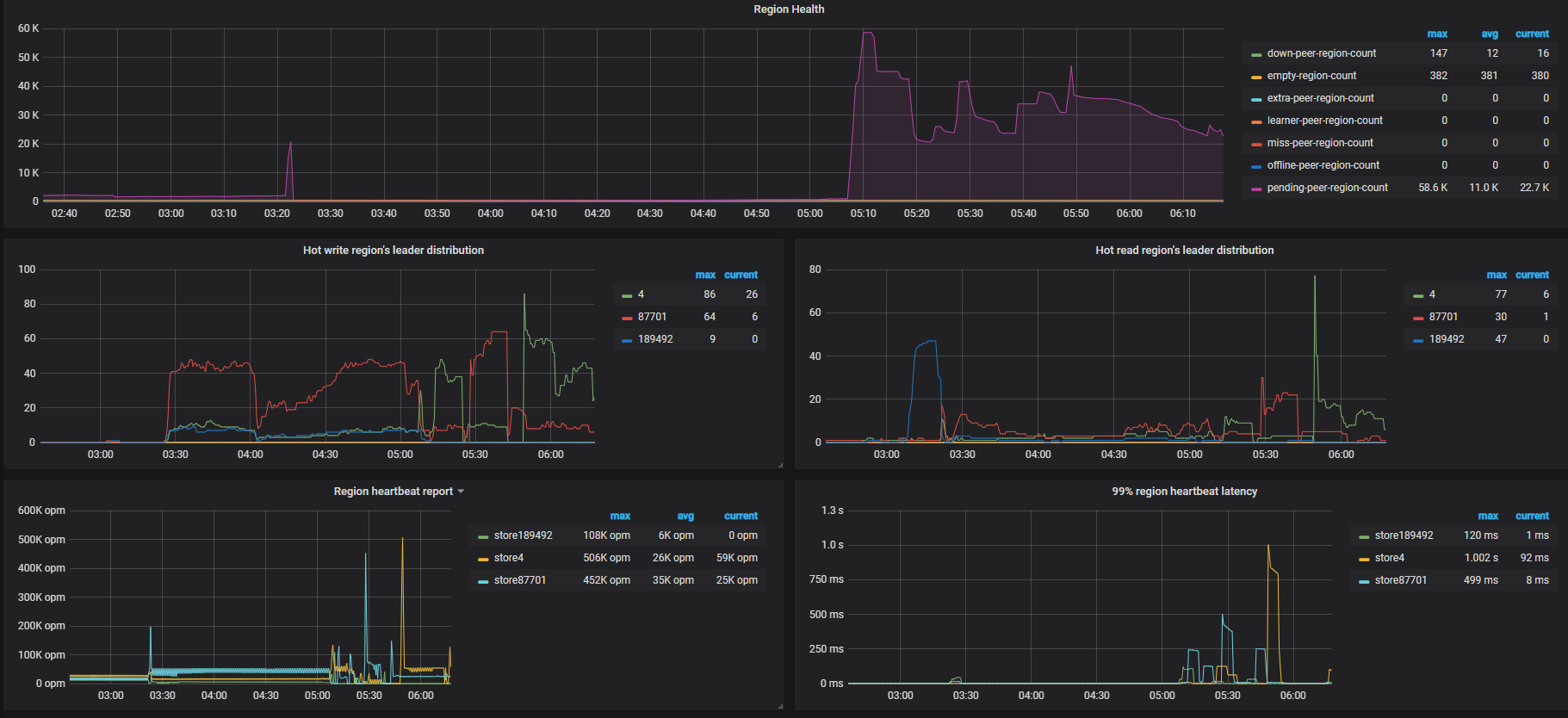
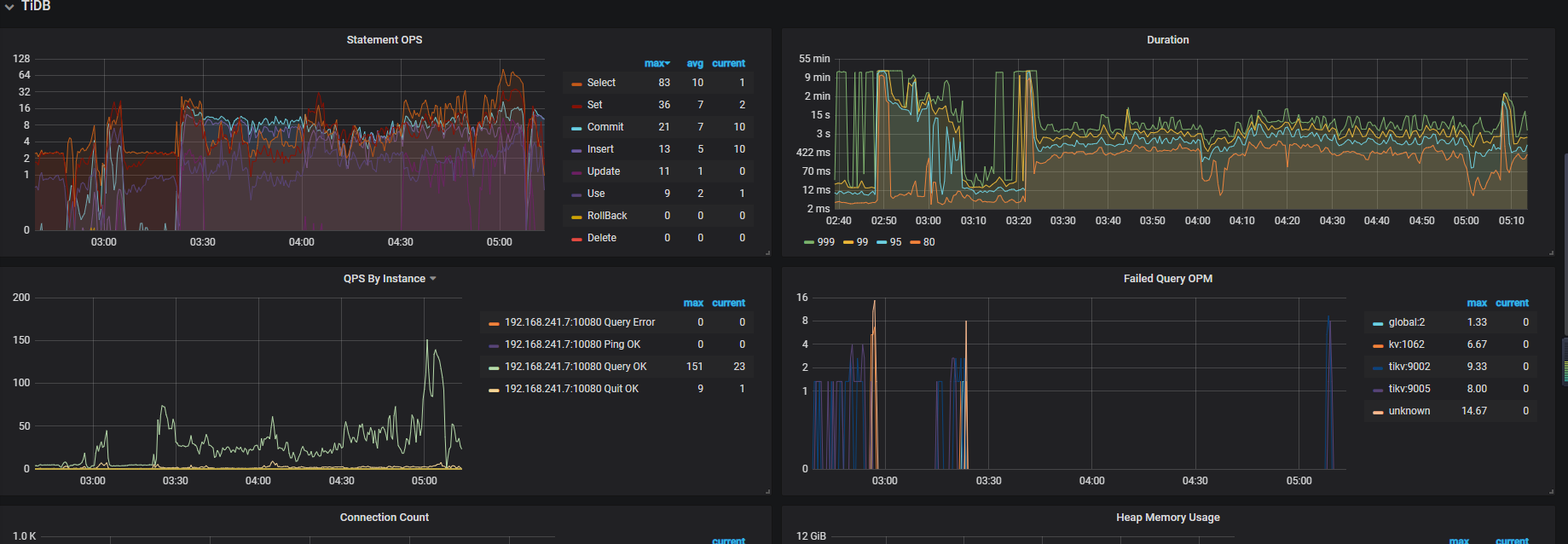
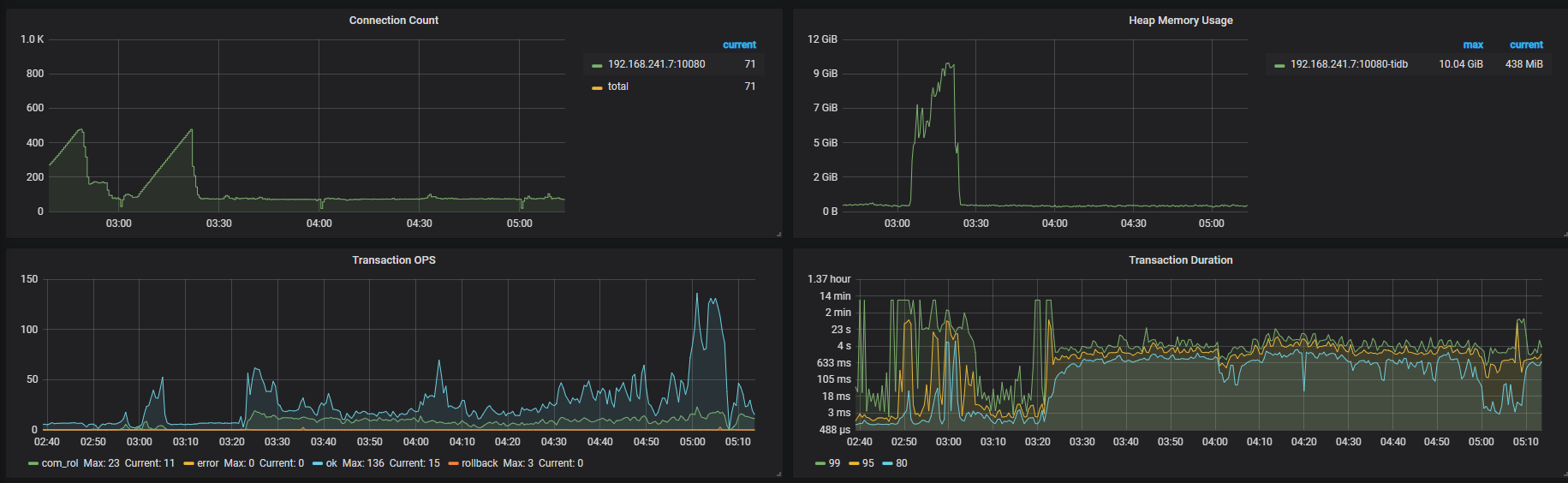
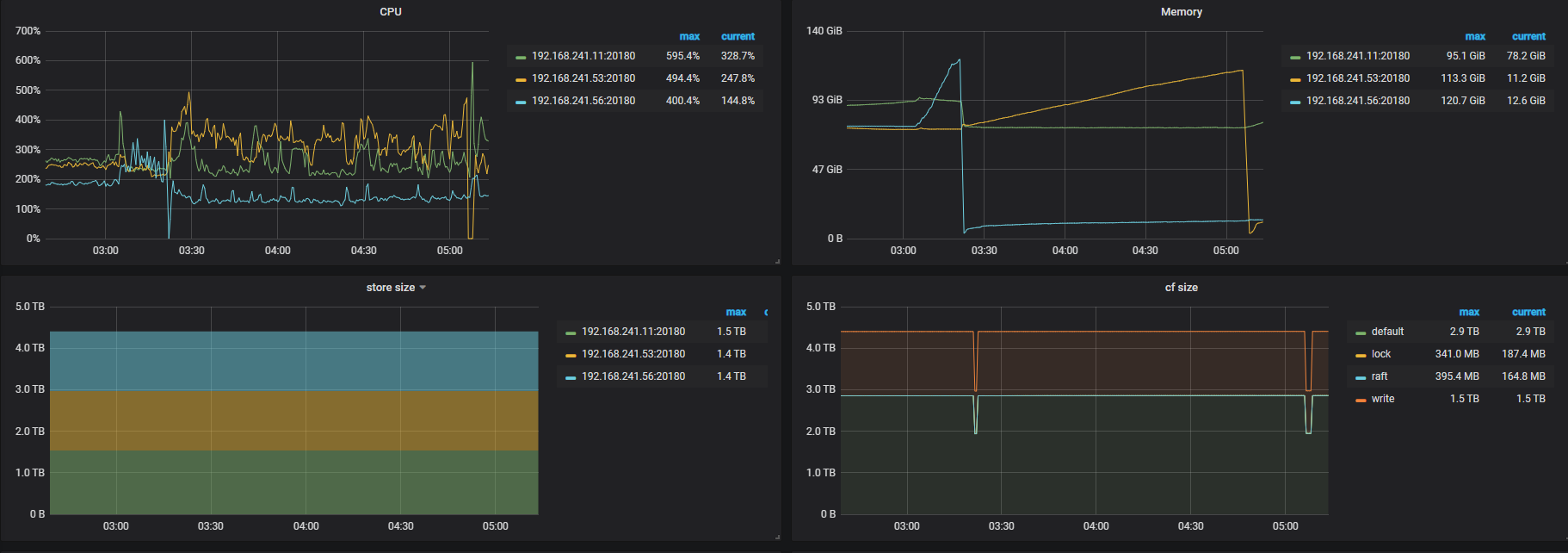
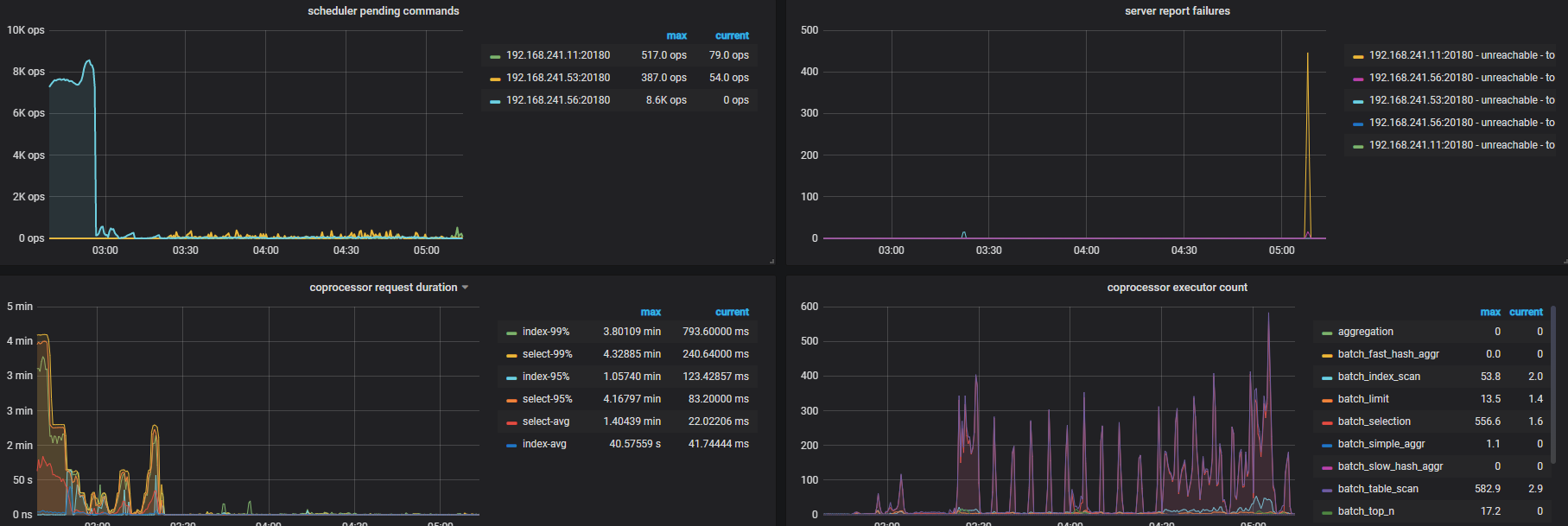
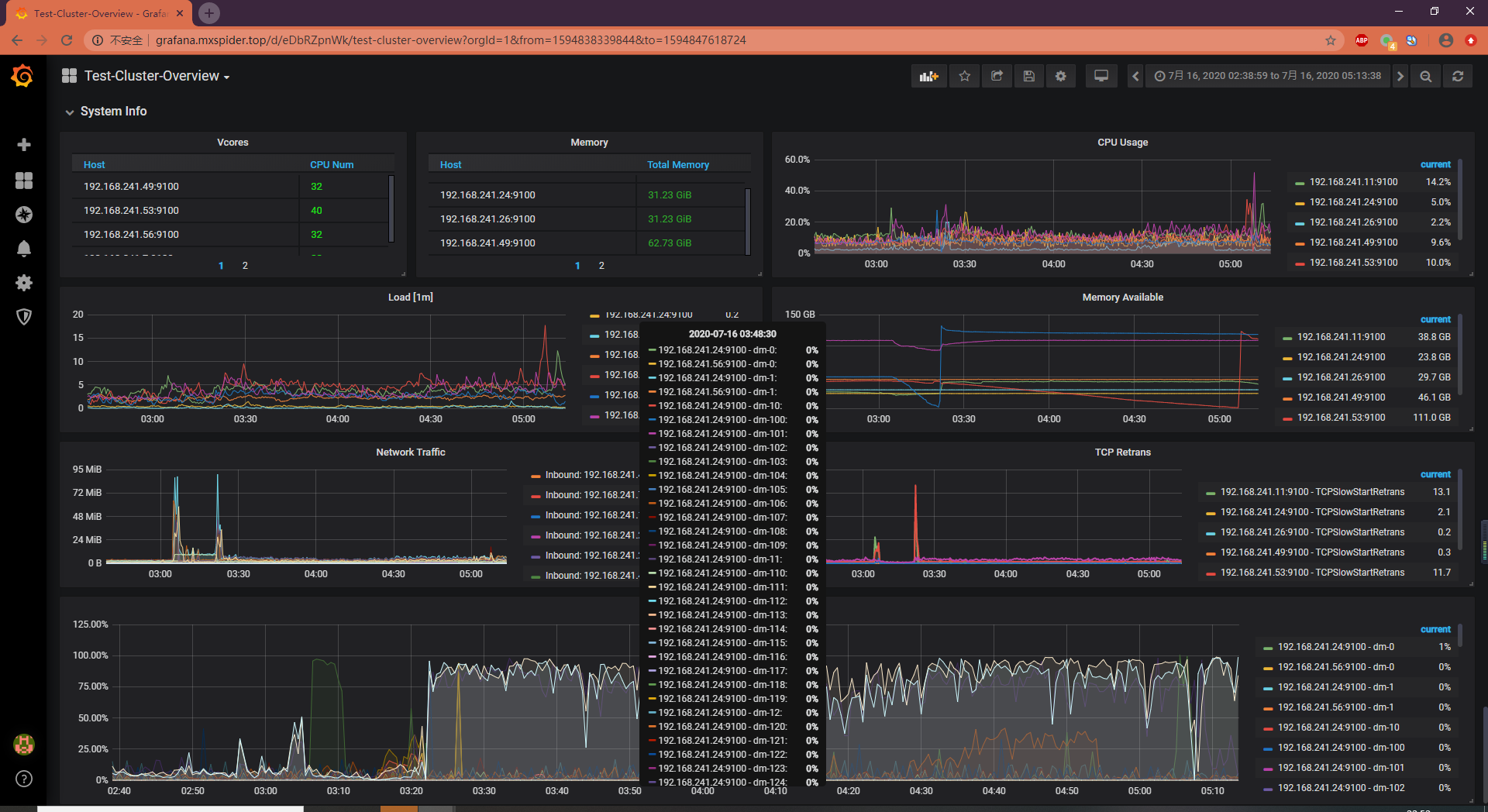
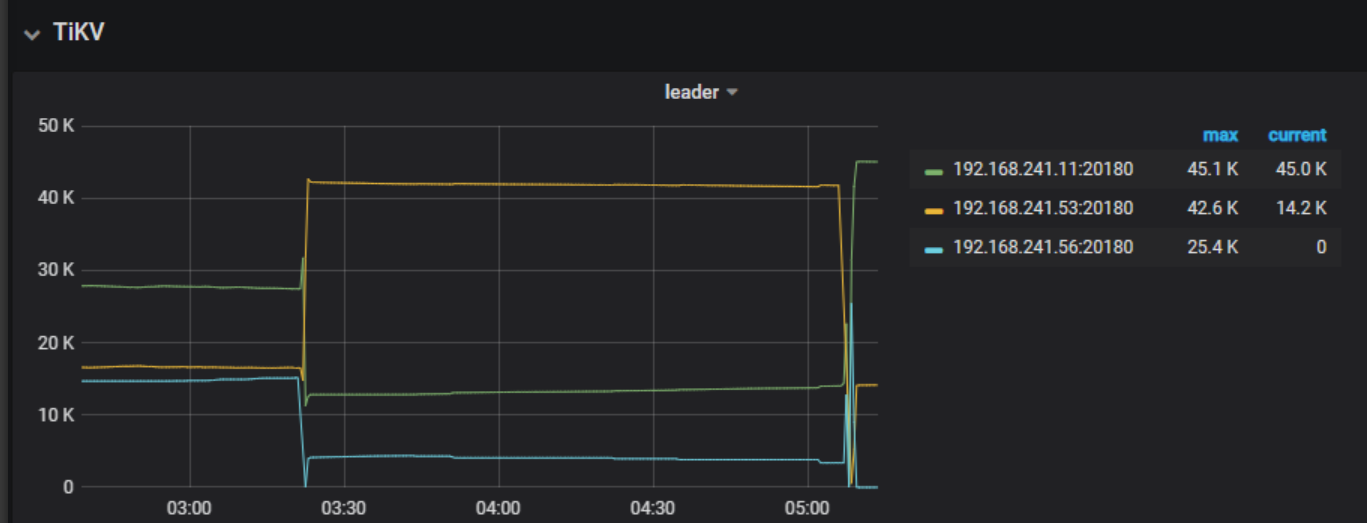
tidb时不时出现堵塞,期间各种类型的query都变慢。然后几小时自己会恢复。在堵塞期间,通过dashboard观察,发现以下情况:
1,所有的kv server(一共三个)的io utility降到非常低,几乎为0,而同期的cpu使用很高。
2,同期update leader和tikvrpc都上涨,pd的pending也都上涨。
3,slow query log里包括各种查询,即使很小的表的查询也会达到1700s,但实际process时间不到1s,wait time几秒,不知道时间花在哪里。
4,tidb server 的log里频繁的报三个:1)、switch region leader to specific leader due to kv return NotLeader
2)、invalidate current region, because others failed on same store
3)、[2020/07/15 06:30:11.820 +08:00] [WARN] [client_batch.go:590] [“wait response is cancelled”] [to=192.168.241.11:20160] [cause=“context canceled”]。