我是lantin-1对lantin-1,上游那个本来就会显示乱码,但是下游的TIDB字符集一样的lantin-1,显示的乱码却不一样。
tidb.log (3.1 MB)
关键字serviceouttable20200320。
先看下当前问题
ok,收到
[2020/07/16 16:11:57.711 +08:00] [WARN] [expensivequery.go:160] [expensive_query] [cost_time=120.072456686s] [process_time=16.342s] [wait_time=16.342s] [backoff_time=0.002s] [request_count=13] [total_keys=4053110] [process_keys=4053097] [num_cop_tasks=13] [process_avg_time=1.257076923s] [process_p90_time=1.759s] [process_max_time=2.469s] [process_max_addr=172.31.169.221:20172] [wait_avg_time=0.000384615s] [wait_p90_time=0.001s] [wait_max_time=0.001s] [wait_max_addr=172.31.169.221:20172] [stats=serviceouttable20200320:418087536021733378] [conn_id=37649] [user=root] [database=tessdsc] [table_ids=“[1505]”] [txn_start_ts=418090057099902991] [mem_max=“968.4514837265015 MB”] [sql=“SELECT *from serviceouttable20200320”]
set @@tidb_expensive_query_time = 800;
在执行,看是否有报错。目前还是限制在 tidb_expensive_query_time 上,虽然不建议这样查全表,会对集群造成影响,但是可以自己测试下

demsg | grep -i oom 看下,tidb-server 是不是重启了
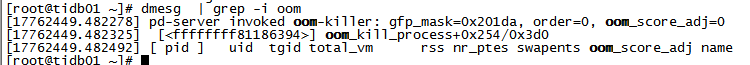
pd-server 被 oom 了。。建议还是分页查询吧
为什么会被oom![]() ,能帮忙查查具体原因吗,之前执行的时候还好好的,感觉配置都都挺高的。谢谢
,能帮忙查查具体原因吗,之前执行的时候还好好的,感觉配置都都挺高的。谢谢![]()
和当时的集群负载有关系,之前没问题不代表现在没问题,oom 时内存使用超限,system 的保护机制,这个还是从使用方式上解决吧,select * ,并不符合开发规范。
请帮忙抓火焰图,我们查一下, curl -G “ip:port/debug/pprof/heap?seconds=30” > heap.profile, ip地址为tidb服务器的ip,端口为tidb_status_port的端口。 最好抓快要OOM时候的,如果不好把握,就在内存快速上涨时,在OOM之前,多抓几个,多谢。


已传,帮忙看一下,谢谢
我猜测是 navicat 执行的,因为那个 out of memory 报错不是 tidb 返回的错误格式
如果是 navicat 的话,我搜了下可能和这个是一个问题 https://blog.csdn.net/qq_43786444/article/details/100014241
果然是navicat的问题,更换了64位的,确实没有报错了,就是执行比较慢。在mysql client端执行没有问题,因为数据量有600多万之前没有执行。谢谢!!
另外有字符集的问题请教一下,因为网络架构的问题,我需要从oracle同步数据到mysql端再到TIDB端,oracle的字符集是gbk的,TIDB并不支持gbk,所以我在mysql端和TIDB端设置的字符集都是latin1,是可以读取gbk串的字节流的,也没有报错。只是显示的中文是乱码,mysql上的乱码是可以正确解码出来的,在TIDB上的乱码和mysql上完全不一样。同样都是latin1的为什么不一样呢?也不知道应该怎么解码。mysql-TIDB同步是用的DM工具。以下图是mysql和TIDB上相同条数的数据。
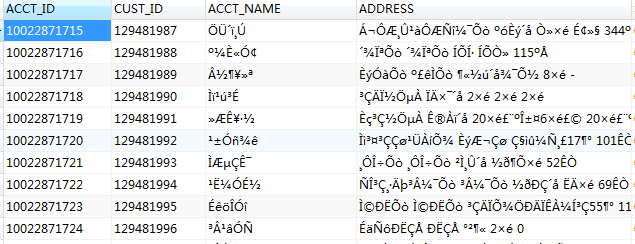

你可以用程序连一下,看是否可以正确解码,或者执行下以下语句上传下反馈结果
Select hex(acct_name), hex(address) 在 mysql 和 tidb 执行对照下,
刚重新更新了应用程序的代码,执行出来和mysql的结果是一样的了,都能正确显示出中文。应该是在原字符编码的显示上两个有区别吧,才显示的不一样。谢谢各位了!
ok,
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。