- 那 over-view的时间只到35分,需要重新采集下,tidb 的没有上传。
- 麻烦执行下 tiup cluster display 集群名称,反馈下拓扑信息,多谢。
- 这个执行计划一直都有psudo,看来统计信息还是有问题,能否麻烦把这个sql中的表,都重新analyze一遍,然后再查看下执行计划,辛苦了,多谢。
重新传了
感谢你的反馈。 还有一些信息需要确认下,
- 请对所有表进行统计信息收集。我看你提供的执行计划中,有一些表的统计信息都是pseudo的,说明该表没有统计信息。 在收集完统计信息后,执行计划可能会有所变化。如果执行计划有变化,请提供下新的执行计划。
- 请问,压测逻辑是怎样的? 在压测过程中,只会运行这一类SQL,还是会有其他的负载同时在运行?
- 请提供一下压测期间的慢日志。通过慢日志,可以具体分析这条 SQL 执行最慢的那几次的具体信息,如执行时间、处理的数据量等等。
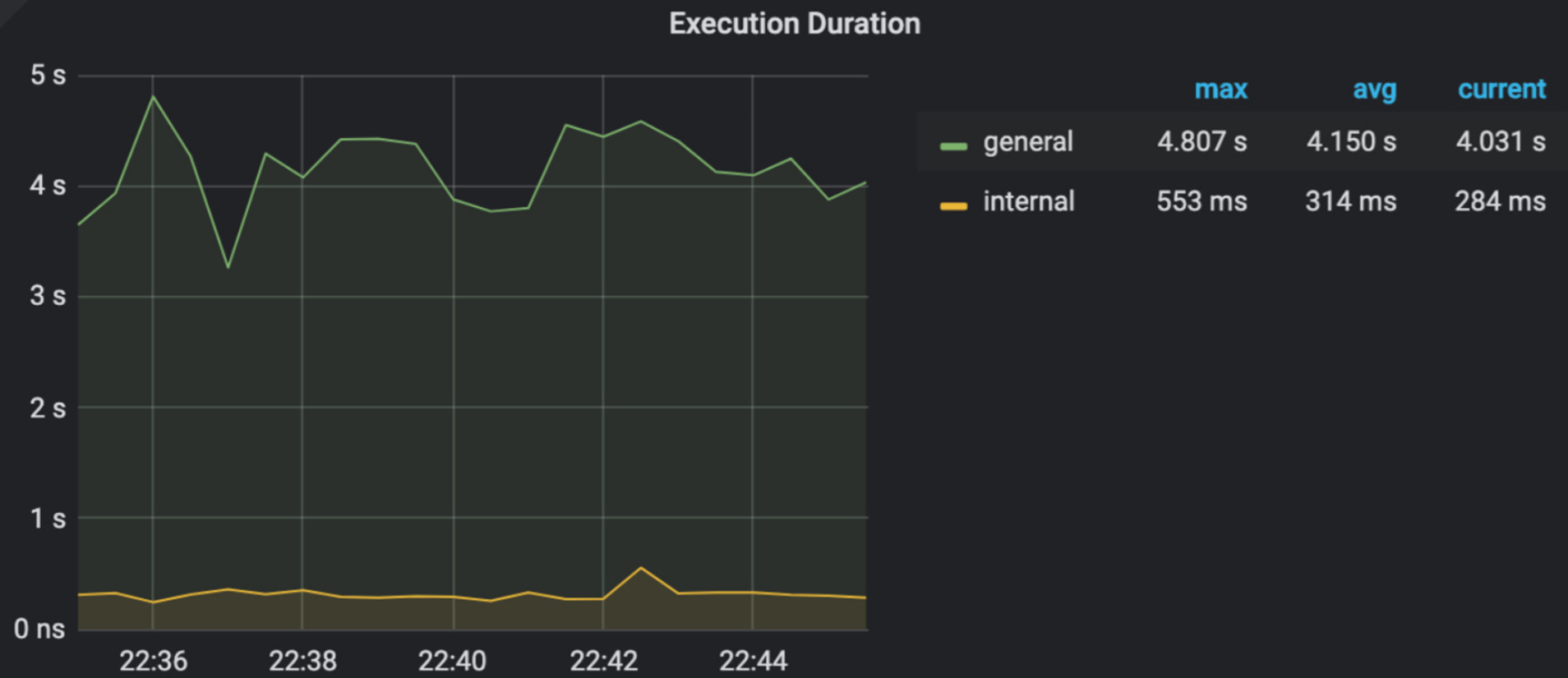
1.有全量收集统计信息的命令吗?只针对这两个表进行了ANALYZE是不会生效的吗?已经对这两个表执行过ANALYZE table xxx,执行后执行计划没有变化。
2.5000个线程无限执行这一条sql。期间没有其他任何sql的执行
3.执行计划没变过,数据量没有变过。只有执行时间变化了。
可能是 TiDB 所在机器的 CPU 到瓶颈了。 TiDB 的 CPU 一直在 1200% ,Goroutine 的数量也保持在较高的 6000-7000。
- 可以尝试降低并发度,从 5000 降到 1000,看看平均延迟是否有下降, 以及 QPS 是否有提升。
- 麻烦帮忙导出一下 TiDB 所在机器的 Node_exporter 的监控信息。
应该不是cpu到瓶颈了,查单表的时候可以去到1500%上下。
1.降低并发度平均延迟有下降,呈线性。在2到30并发的时候达到最低延迟。
2.目前测试机器已经回收了。无法导出这个了。。。
非常抱歉,这个问题没有找到根因,我这边也没有让第一次就返回足够的信息。如果下次还能测试,麻烦帮忙也反馈下node_exporter的监控,多谢。
这边通过恢复重启了之前的集群,我抓取了那段时间的node-exporter,麻烦继续帮忙分析一下,谢谢。
抱歉 回复晚了。上边提供的 Node-exporter 的节点是 10.6.0.15 pd 节点的信息,不是 TiDB 示例的 Node-exporter。 麻烦帮忙拿下 TiDB 的 Node-exporter…
![]() 拿不到了。。。
拿不到了。。。
抱歉,请下次测试时帮忙收集,多谢。