您好,目前看起来 30 上的 pd 认为自己已经从集群中被删除了,集群实际的 PD 是 32 并且正在运行,能否尝试 edit-config 将拓扑中的 PD 结点修改为 32 (改 host: 192.168.30.32 和 name: pd_localhost3),之后再 reload PD 能否成功?

可以在那个路径放一个空文件

迁移 PD leader 出错是可以预期的,因为当前集群的状态不正常,但 PD 的启动脚本应该已经更新了
TIKV监控里只能看到一个
请问这个具体是什么意思?是 Grafana 里面只能看到一个 TiKV 结点吗?还是 tiup cluster display?
PD 能启动的话可以再 reload tikv 的配置试试,在最开始错误的扩容操作时候可能有 TiKV 的配置不正确
另外能否提供一下 curl -s http://192.168.30.32:2379/pd/api/v1/members 的输出?
启动集群,然后reload整个集群。现在看起来是正常了。
[tidb@localhost log]$ curl -s http://192.168.30.32:2379/pd/api/v1/members
{
“header”: {
“cluster_id”: 6775469463473339511
},
“members”: [
{
“name”: “pd_localhost2”,
“member_id”: 7637577539881469637,
“peer_urls”: [
“http://192.168.30.31:2380”
],
“client_urls”: [
“http://192.168.30.31:2379”
],
“deploy_path”: “/data1/pd/bin”,
“binary_version”: “v4.0.2”,
“git_hash”: “0bd6bbd53600b4770e7fa0707d131f8a71be90e4”
},
{
“name”: “pd_localhost3”,
“member_id”: 14901041561631198748,
“peer_urls”: [
“http://192.168.30.32:2380”
],
“client_urls”: [
“http://192.168.30.32:2379”
],
“deploy_path”: “/data1/pd/bin”,
“binary_version”: “v4.0.2”,
“git_hash”: “0bd6bbd53600b4770e7fa0707d131f8a71be90e4”
}
],
“leader”: {
“name”: “pd_localhost2”,
“member_id”: 7637577539881469637,
“peer_urls”: [
“http://192.168.30.31:2380”
],
“client_urls”: [
“http://192.168.30.31:2379”
]
},
“etcd_leader”: {
“name”: “pd_localhost2”,
“member_id”: 7637577539881469637,
“peer_urls”: [
“http://192.168.30.31:2380”
],
“client_urls”: [
“http://192.168.30.31:2379”
],
“deploy_path”: “/data1/pd/bin”,
“binary_version”: “v4.0.2”,
“git_hash”: “0bd6bbd53600b4770e7fa0707d131f8a71be90e4”
}
}
我接下来应该怎么扩容?有点凌乱了
从上面的 PD API 结果看,PD 认为 31 也在集群内,能否确认下 31 上现在是否有 PD 进程存在?
监控只有一个 PD 是因为拓扑里只有一个,监控配置是从拓扑生成的,可以参照和刚才一样的方式,通过 edit-config 把 31 也添加到集群中,再 reload
对于 30 上的 PD 进程,因为 PD 认为它已经从集群中被删除,可以停止该进程,把 data_dir 重命名(备份),然后按正常流程用 scale-out 命令重新扩容一次 30 结点,注意扩容的时候增量拓扑中不要添加 imported: true 参数(这样生成的 deploy_dir 和 data_dir 都会和当前已有结点不通,为单个 instance 独享一个子目录,和 tidb-ansible 中所有 instance 共享目录的行为有所区别)
imported:true,关于instance共享目录,这个是不是只针对一台主机,部署多个,才会存在这个问题?有相关的文档么?我没找到。
我需要把edit-config中,所有PD节点的imported:true去掉么?
另外:十分感谢,强力支援!
imported:true,关于instance共享目录,这个是不是只针对一台主机,部署多个,才会存在这个问题?有相关的文档么?我没找到。
对于从 tidb-ansible 导入的 instance, 会自动添加这个字段,用来在一些操作时做兼容(主要就是目录共用的问题),正常 deploy, scale-out 等操作传入的拓扑文件都不应该添加这个字段,因为不是从 tidb-ansible 导入的
我需要把edit-config中,所有PD节点的imported:true去掉么?
不需要,保持现状即可,后面再扩容新节点不添加 imported: true 即可,会自动处理相关的兼容问题
后续版本我们也会把拓扑文件检查再做进一步完善
ps, 正常情况下 edit-config 不应该做任何涉及到拓扑变化(节点增删改)的修改,这次的例子只是特殊情况,一般地扩缩容操作应该使用 scale-out/scale-in 操作来完成,这些操作的执行逻辑中包括了拓扑和配置的检查,可以避免很多常见的问题


1.请问之后又做了哪些操作吗?
2.麻烦反馈下当前的 tiup cluster display 集群名称 信息
3. tiup ctl pd -u pdip:pdport -i 命令行下 member ,反馈下当前member 信息,多谢。
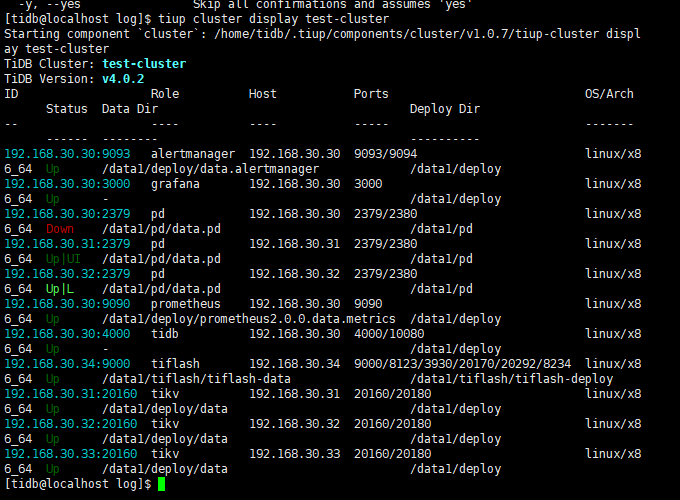

你好,可能是 30 上的 PD 读取到了旧的数据,可以尝试用 scale-in 将 30 缩容,再通过 scale-out 扩容,这样应该会把旧数据删除掉

可以加上 --force 参数来跳过迁移 Leader 的步骤强制执行