为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:4.0.2;DM版本:1.0.5
- 【问题描述】:因上游mysql有超过4G的大文件,按照官方修复方案https://docs.pingcap.com/zh/tidb-data-migration/v1.0/error-handling进行相关操作,操作过程:
对于 relay 处理单元,可通过以下步骤手动恢复:
- 在上游确认出错时对应的 binlog 文件的大小超出了 4GB。
- 停止 DM-worker。
stop-task hollycas- 将上游对应的 binlog 文件复制到 relay log 目录作为 relay log 文件。
scp mysql-bin.005719 10.100.45.4:/data/dm/deploy/relay_log/89b73e86-22ad-11e9-81b6-70c7f218fe45.000001
scp mysql-bin.005720 10.100.45.4:/data/dm/deploy/relay_log/89b73e86-22ad-11e9-81b6-70c7f218fe45.000001
scp mysql-bin.005721 10.100.45.4:/data/dm/deploy/relay_log/89b73e86-22ad-11e9-81b6-70c7f218fe45.000001
scp mysql-bin.005722 10.100.45.4:/data/dm/deploy/relay_log/89b73e86-22ad-11e9-81b6-70c7f218fe45.000001
scp mysql-bin.005723 10.100.45.4:/data/dm/deploy/relay_log/89b73e86-22ad-11e9-81b6-70c7f218fe45.000001
scp mysql-bin.005724 10.100.45.4:/data/dm/deploy/relay_log/89b73e86-22ad-11e9-81b6-70c7f218fe45.000001- 更新 relay log 目录内对应的
relay.meta文件以从下一个 binlog 开始拉取。如果 DM worker 已开启enable_gtid,那么在修改relay.meta文件时,同样需要修改下一个 binlog 对应的 GTID。如果未开启enable_gtid则无需修改 GTID。例如:报错时有binlog-name = "mysql-bin.004451"与binlog-pos = 2453,则将其分别更新为binlog-name = "mysql-bin.004452"和binlog-pos = 4,同时更新binlog-gtid = "f0e914ef-54cf-11e7-813d-6c92bf2fa791:1-138218058"。
vi relay.meta
binlog-name = “mysql-bin.005725”
binlog-pos = 4
binlog-gtid = “”- 重启 DM-worker。
ansible-playbook start.yml --tags=dm-worker对于 binlog replication 处理单元,可通过以下步骤手动恢复:
- 在上游确认出错时对应的 binlog 文件的大小超出了 4GB。
- 通过
stop-task停止同步任务。
stop-task hollycas- 将下游
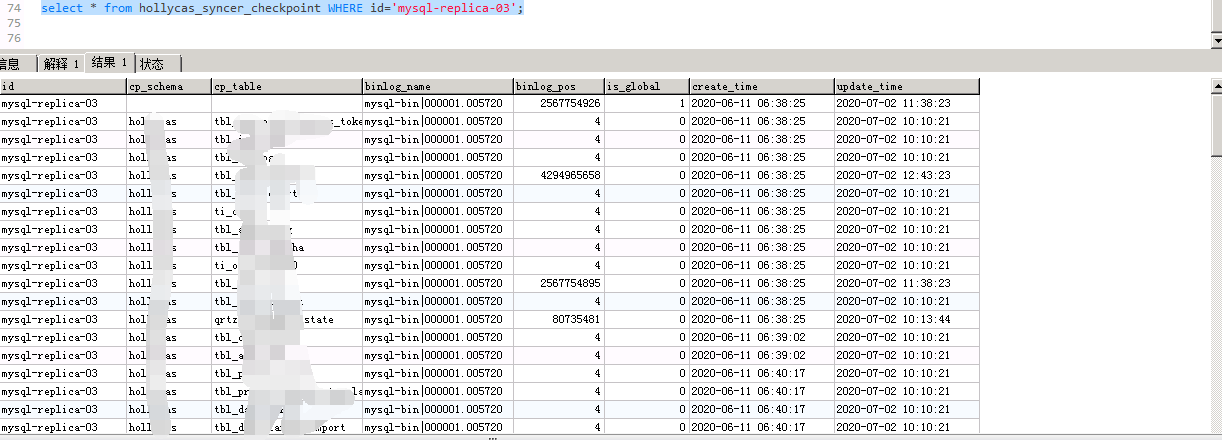
dm_meta数据库中 global checkpoint 与每个 table 的 checkpoint 中的binlog_name更新为出错的 binlog 文件,将binlog_pos更新为已同步过的一个合法的 position 值,比如 4。例如:出错任务名为dm_test,对应的source-id为replica-1,出错时对应的 binlog 文件为mysql-bin|000001.004451,则执行UPDATE dm_test_syncer_checkpoint SET binlog_name='mysql-bin|000001.004451', binlog_pos = 4 WHERE id='replica-1';。
UPDATE hollycas_syncer_checkpoint SET binlog_name=‘mysql-bin|000001.005720’, binlog_pos = 4 WHERE id=‘mysql-replica-03’;- 在同步任务配置中为
syncers部分设置safe-mode: true以保证可重入执行。
vi task_hollycas.yaml
syncers:
global:
worker-count: 16
batch: 100
safe-mode: true- 通过
start-task启动同步任务。
start-task /home/tidb/dm-ansible/conf/task_hollycas.yaml- 通过
query-status观察同步任务状态,当原造成出错的 relay log 文件同步完成后,即可还原safe-mode为原始值并重启同步任务。
操作完运行一段时间后仍然出现如下报错:
[code=36001:class=sync-unit:scope=internal:level=high] panic error: table checkpoint (mysql-bin|000001.005720, 474860631) less than global checkpoint (mysql-bin|000001.005720, 2567754926)(flushed (mysql-bin|000001.005720, 2567754926))
github.com/pingcap/dm/pkg/terror.(*Error).Generate
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/pkg/terror/terror.go:232
github.com/pingcap/dm/syncer.(*Syncer).Run.func5
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:1138
runtime.gopanic
\t/usr/local/go/src/runtime/panic.go:679
github.com/pingcap/dm/syncer.(*RemoteCheckPoint).saveTablePoint
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/checkpoint.go:283
github.com/pingcap/dm/syncer.(*RemoteCheckPoint).SaveTablePoint
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/checkpoint.go:277
github.com/pingcap/dm/syncer.(*Syncer).addJob
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:827
github.com/pingcap/dm/syncer.(*Syncer).commitJob
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:1984
github.com/pingcap/dm/syncer.(*Syncer).handleRowsEvent
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:1580
github.com/pingcap/dm/syncer.(*Syncer).Run
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:1334
github.com/pingcap/dm/syncer.(*Syncer).Process
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:599
github.com/pingcap/dm/syncer.(*Syncer).Resume
\t/home/jenkins/agent/workspace/build_dm_master/go/src/github.com/pingcap/dm/syncer/syncer.go:2361
runtime.goexit
\t/usr/local/go/src/runtime/asm_amd64.s:1357
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。