为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.9
- 【问题描述】:集群突然出现大量慢SQL,查看主要以点查为主,少量UPDATE语句。请问,问题如何排查


若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
查看慢日志,基本都是 以下sql,能否麻烦您单独执行一个sql,返回执行计划。
explain analyze SELECT id,tax_credit_id,company_keywords,data_status,create_date,update_date FROM tax_credit_link_pro WHERE ( ( tax_credit_id in xxxx)
你好,这个表暂时被删了,通过慢日志也可以看到其他的查询也慢了,但是目前执行是基本都秒回,这个问题是事故后的复盘,想尽量避免再次发生,需要什么监控面板来提供一下,多谢
explain analyze SELECT id,data_status,create_date,update_date,key_no,no,company_name,year,province_code,province FROM ?.? WHERE ( ( id in ( ?,?,?,? ) ) );
这是其中一条慢sql的执行计划,
请从下面的方式进行排查:
1、如果该字段存在 index ,那么请看下该表的统计信息的健康度:
https://docs.pingcap.com/zh/tidb/v3.0/statistics#表的健康度信息
2、如果健康度在 100% ,但是执行计划仍然会出现偏差,那么可以提供下该表的建表语句,以及导出该表的统计信息,这里分析复现下:
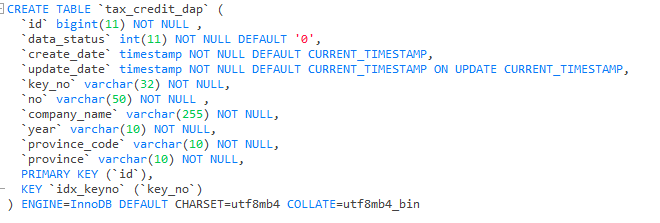
你好,id为主键,SHOW STATS_HEALTHY 查看该表的健康度为100,以下是该表导出的统计信息
{
“database_name”: “manage_enterprise_db”,
“table_name”: “tax_credit_dap”,
“columns”: {
“company_name”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“create_date”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“data_status”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“id”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“key_no”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“no”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“province”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“province_code”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“update_date”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
},
“year”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
}
},
“indices”: {
“idx_keyno”: {
“histogram”: {
“ndv”: 0
},
“cm_sketch”: null,
“null_count”: 0,
“tot_col_size”: 0,
“last_update_version”: 417319098360266773,
“correlation”: 0
}
},
“count”: 0,
“modify_count”: 0,
“partitions”: null
}
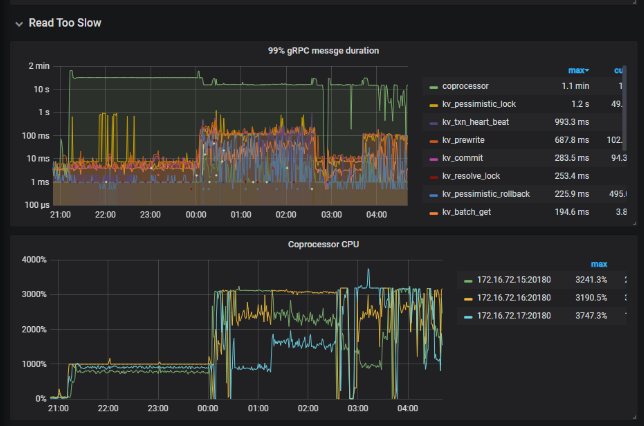
您好, id 字段为主键,执行速度原则上会很快,这条 sql 现在执行不慢,那么还是建议从其他的 slowlog 入手排查:
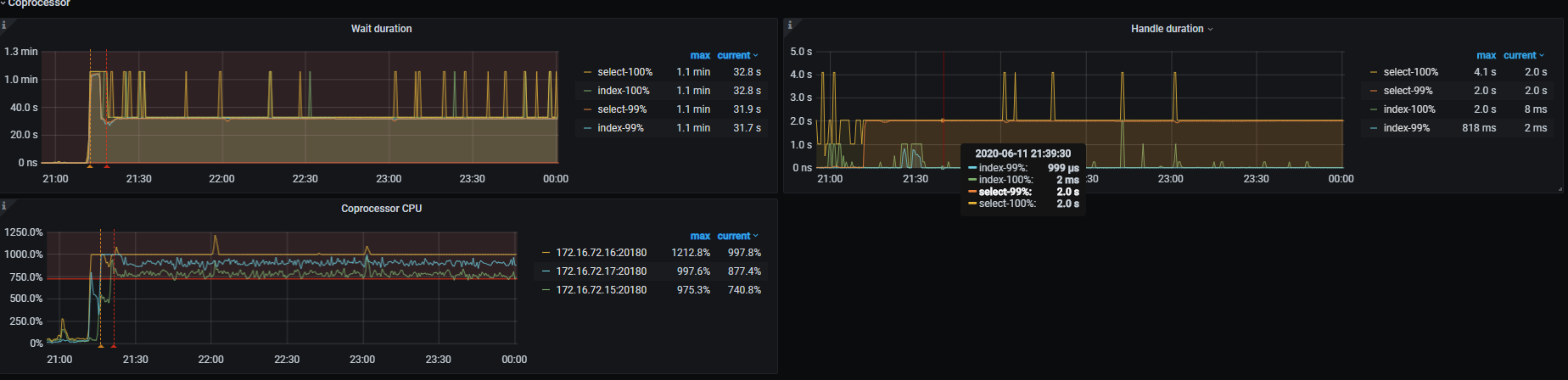
1、slowlog 中这条 sql 执行比较慢可能是当时有其他的大 sql 或者慢查询导致 coprocessor 比较繁忙,进而出现了 coprocessor wait 的情况如下:
2、如果现在是想复盘当时的情况,还是建议看下 slowlog 其他慢 sql 的情况:
1)是否存在统计信息不准确导致执行计划选择错误
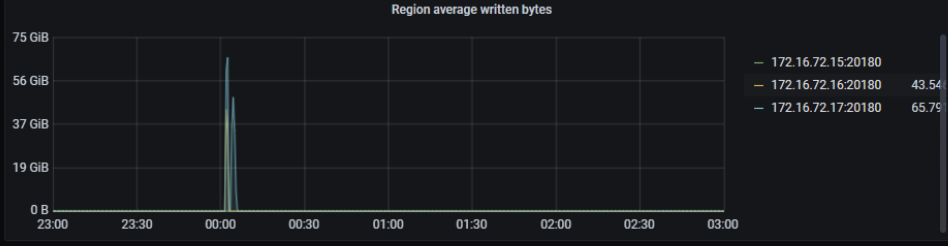
2)看其他的监控项,发现在 0 点后,有大批量的写入操作,量很大
3)请看下 3 个 tikv 节点是否出现过 OOM ,tikv 可能是重启过
4)请将故障发生时 0~3 的 tidb 的监控面板,tikv-details 的监控面板导出上传,这边再看下
收到,这边看下,如有进展,会尽快跟帖回复~~
您好,我们先一起先梳理下时间线:
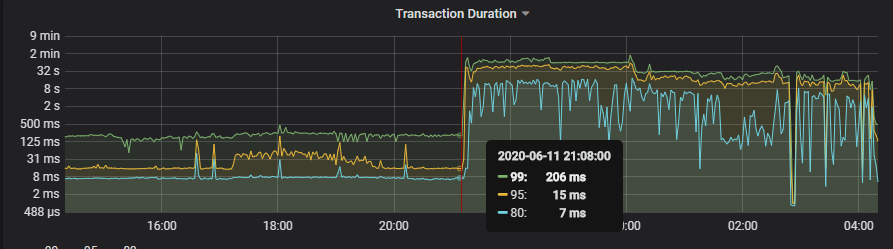
1、11日晚 21 点左右 tidb 集群的 duration 响应时间开始升高。
2、分别在 00:00, 00:20 , 02:40 以及 03:50 左右重启了 tikv 节点。
3、在 00:00 左右第一次重启后,并没有缓解这个现象,当时集群的读和写的耗时并没有缓解。
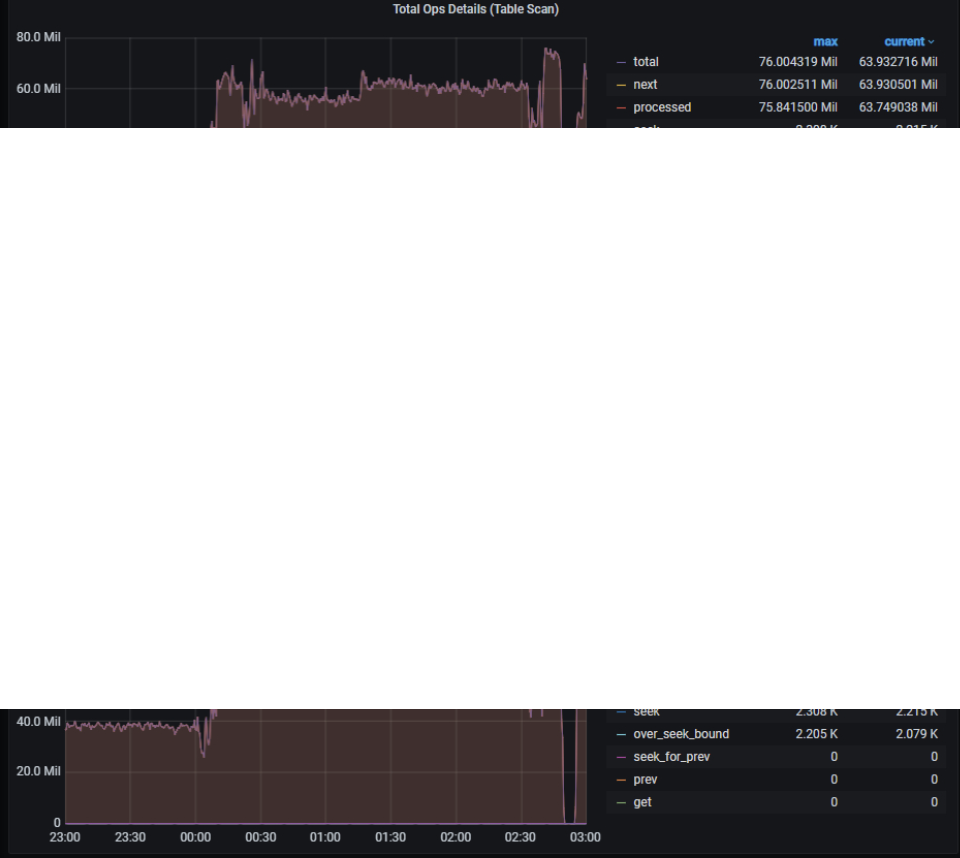
当前 00:00 ~ 03:00 tikv 的监控可以看到:
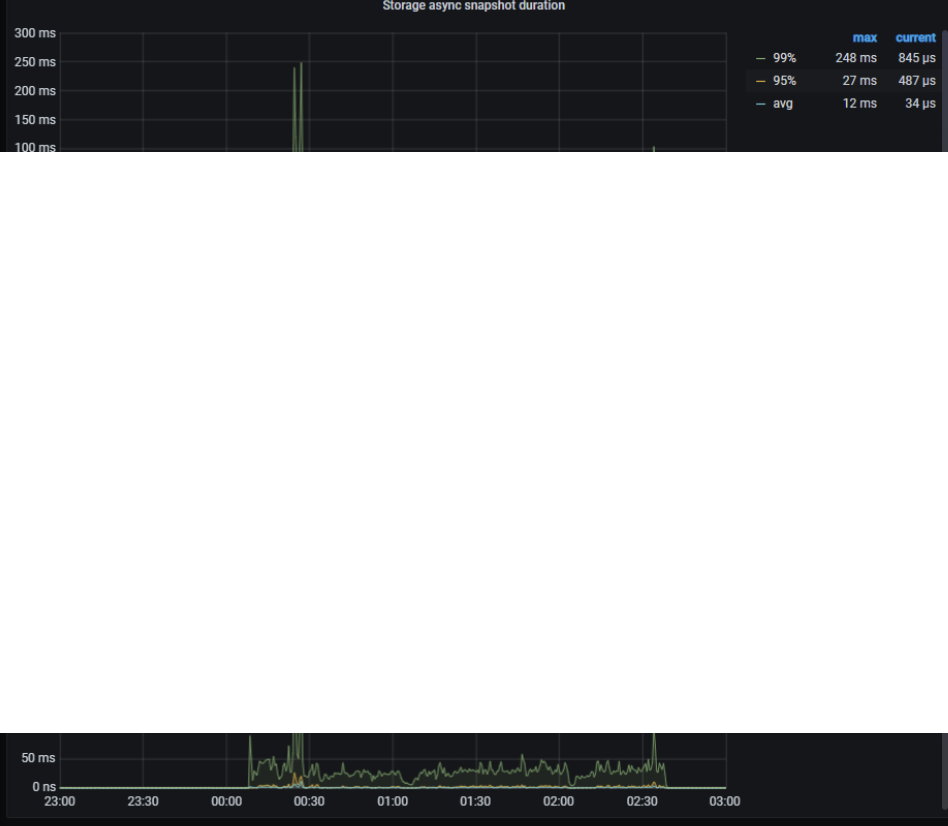
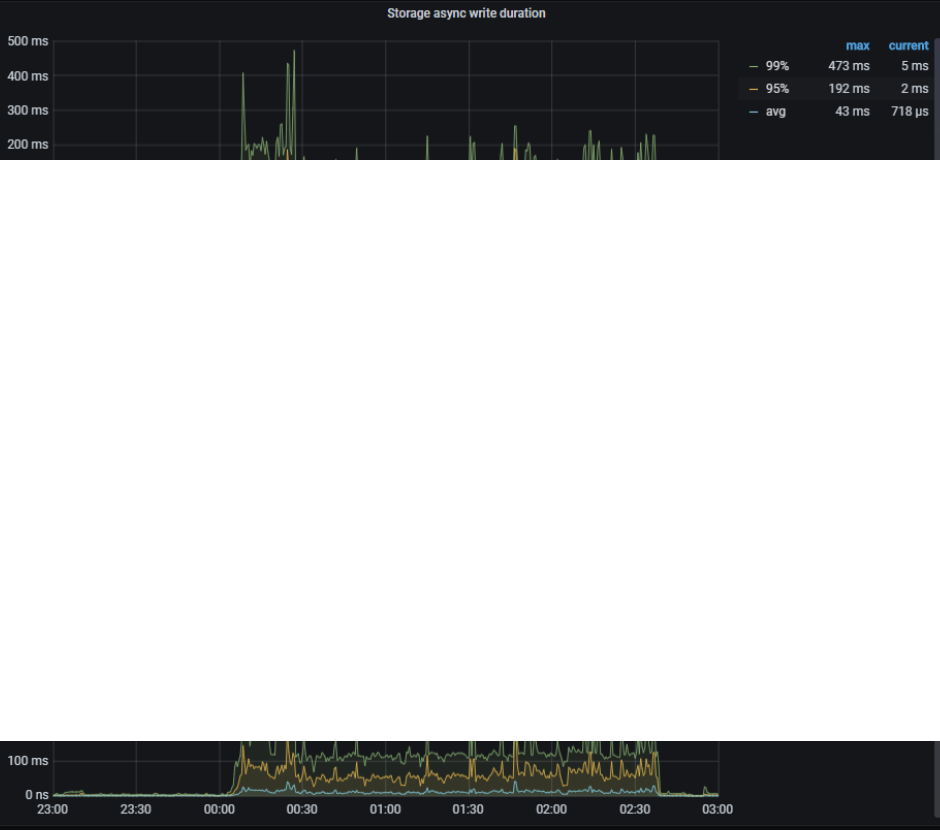
1、00:00 开始整个集群的读写都很明显的变慢了,读获取快照,以及写耗时都升高:
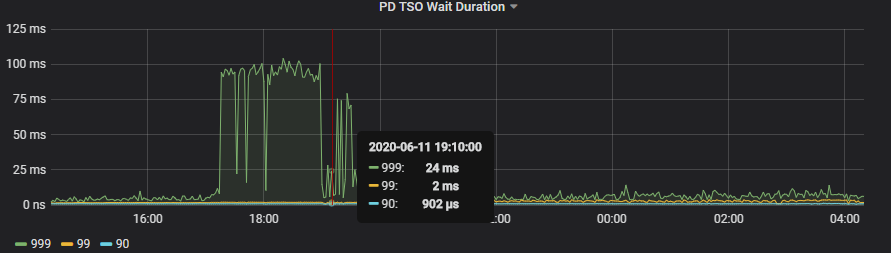
2、关于读耗时
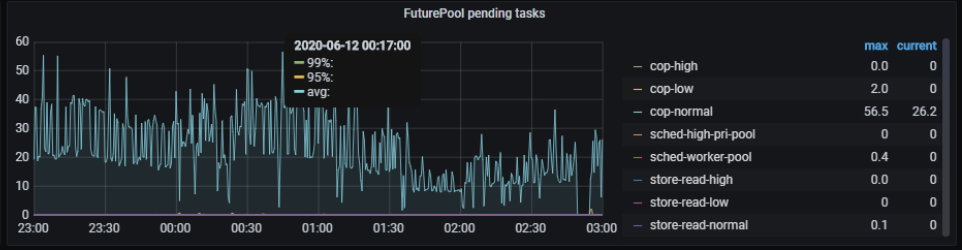
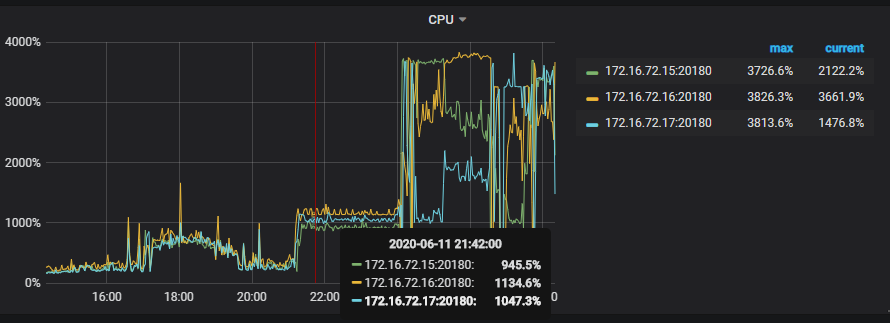
1)coprocessor cpu 在重启后 cpu 的利用率也相当的高,且不均衡
2)coprocessor normal 线程池有大量的任务堆积,很可能是大 sql 查询或者慢 sql ,任务堆积后,也会影响其他 sql 语句的查询效率:
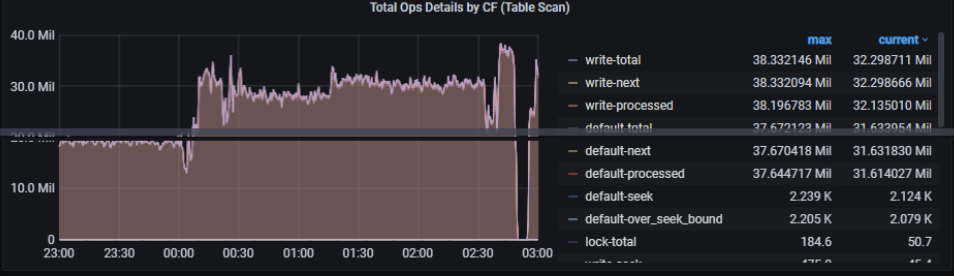
3)当前环境中存在大量表扫描的操作:
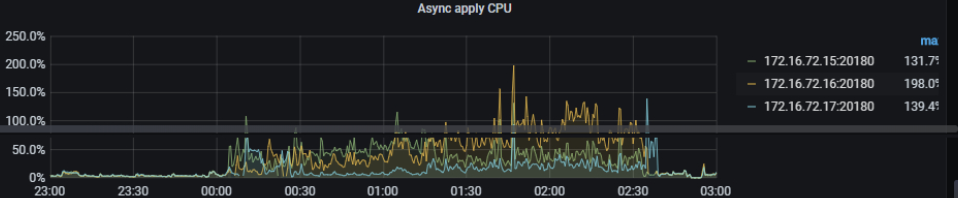
3、关于写耗时
2)raftstore 、apply cpu 利用率较高且不均衡,请确认当前环境 store-pool-size , apply-pool-size 参数设置:
slowlog 可以看到下面的信息:
建议排查下下述 sql 语句涉及到的表统计信息的准确度,以及目标表是否有 index ,或者是否是执行计划出现了偏差:
1、集中在 tax_credit_link_pro 表的 select 使用了大量的 in (x,x,x…)的形式,该表的数据量可能非常大,并且为全表扫描。
集群参数配置:
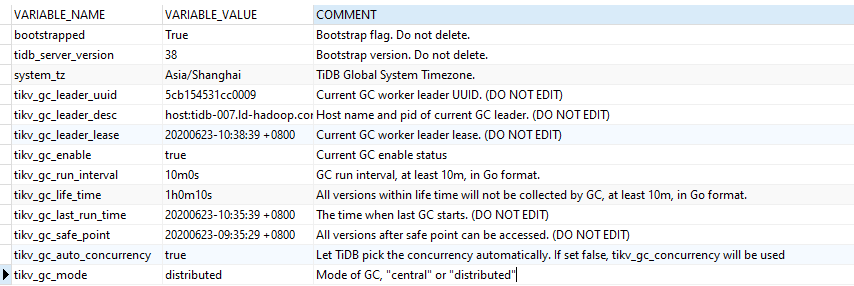
1、这里看到 gc 的设置分别为 4 weeks 以及 10 分钟,是出于特殊的考虑,需要保留 4 weeks 之内的 key 的 mvcc 吗?原则上 mvcc 版本越多,可能 sql 扫描的效率会降低,因为需要扫描的 key 的版本变多了。除此以外,可能会额外的占用空间。
你好,时间线是完全符合的
消费的是kafka的数据(堆积了1200万的数据),通过dpcp连接池使用,会将处理之后的数据落在tidb上,写入并发3000-4000,业务上也有读取的请求,因为代码处理中会query tidb中的数据,并发不详
store-pool-size 和apply-pool-size的配置都是16
执行计划的偏差如何排查?我看到的慢sql上面确实有些不规矩的,类似where (a in (b,b,b,b,b…))这种,tax_credit_link_pro已经被“毁尸灭迹”了,表被删了,可能改业务需求吧,但是目前集群中应该还是有很多全表scan的查询,可能不是导致9点突发卡死的主要原因
GC配置10分钟我理解,4 weeks是mvcc保留时间默认配置,在哪里配置成合理大小,这个配置之前注意到
1、请根据实际情况来配置 store-pool-size 和 apply-pool-size 的值,如果配置的参数过大,会带来线程轮转的开销,具体设置的大小,请根据监控信息中资源使用的高线来设置。
2、GC 相关的配置 ,如果 interval time 设置为 4 weeks ,那么表示保留的数据 mvcc 版本的时限为 4 weeks ,如果对 mvcc 版本没有这么长的时限,那么建议,调小 interval time ,具体的时间请参照当前环境中的业务需求,如果设置的过小,可能会出现 GC life time is shorter than transaction duration 的报错。
3、关于执行计划的偏差,在 3.0.8 版本后提供了 statement 功能,详情如下:
https://docs.pingcap.com/zh/tidb/v3.0/statement-summary-tables#statement-summary-tables
4、另外,建议根据 slowlog 以及从业务的角度排查下,是否存在大批量的扫描数据,但是缺失索引的表对象。
5、如果是表对象的统计信息不准确,并且自动收集统计信息不能满足需求的情况下,建议对经常访问的核心业务表定期的收集统计信息,或者使用 hint 固定其执行计划,避免执行计划偏差。
你好,
监控数据是在 6-11 - 6-12 时间段内,gc life time 设置为 4 week,请看下当前监控中 gc 部分是否符合预期。
可以根据以下命令重新设置下 :
update mysql.tidb set VARIABLE_VALUE=“10m0s” where VARIABLE_NAME=“tikv_gc_life_time”;
update mysql.tidb set VARIABLE_VALUE=“10m0s” where VARIABLE_NAME=“tikv_gc_run_interval”;