为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.0-rc.1
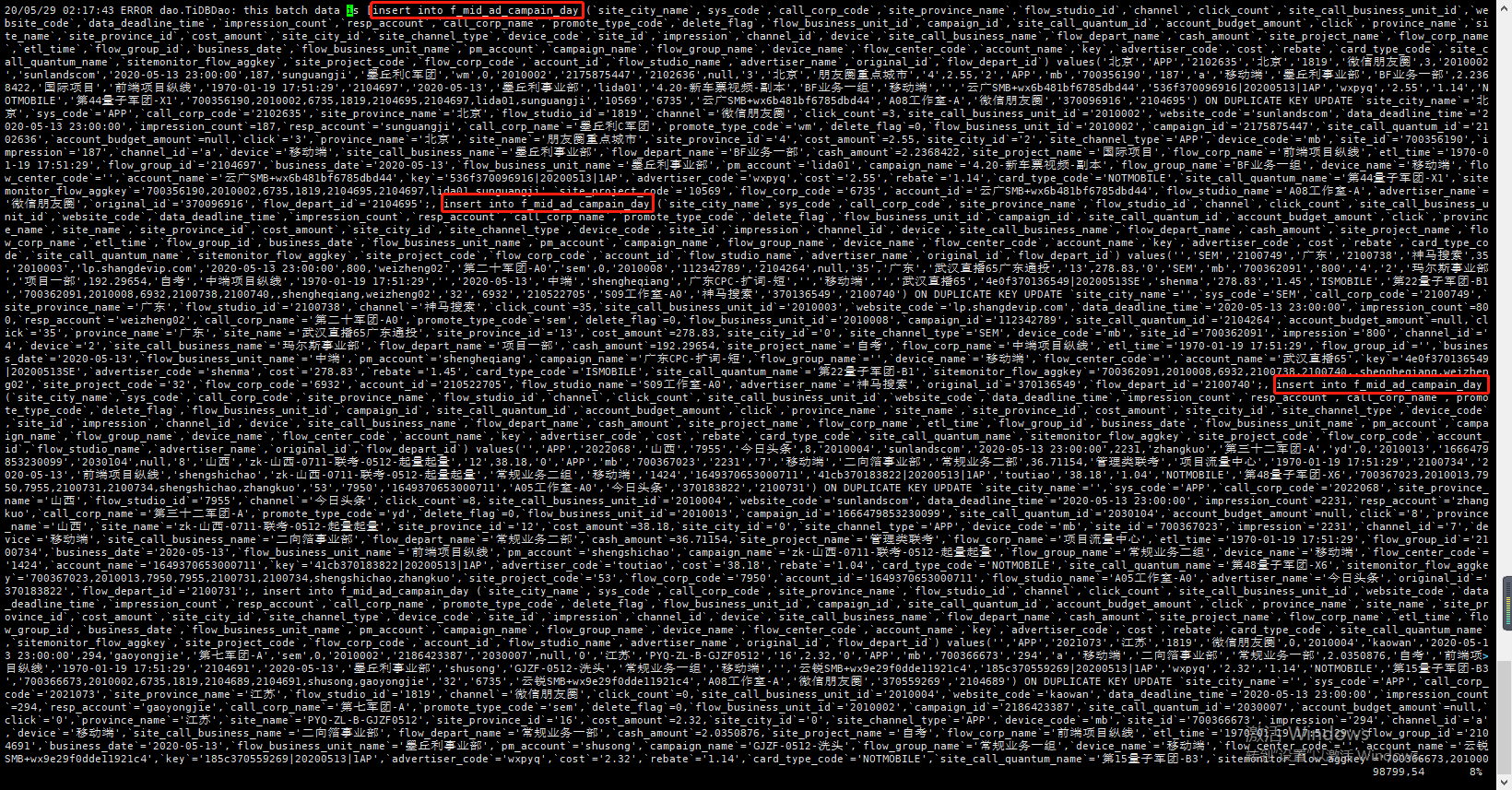
- 【问题描述】:spark任务通过jdbc写入数据,任务没有报错,但是在客户端查询不到更新插入的数据,重置三次kafka位点,都查不到最新数据,最后通过在终端手动写入才成功,实时任务总数据量一直都是对的,实时变化的
这是老数据
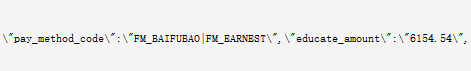
这是最新数据



若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
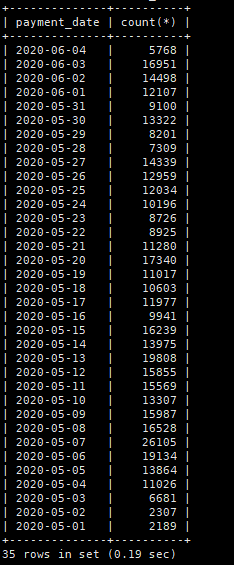
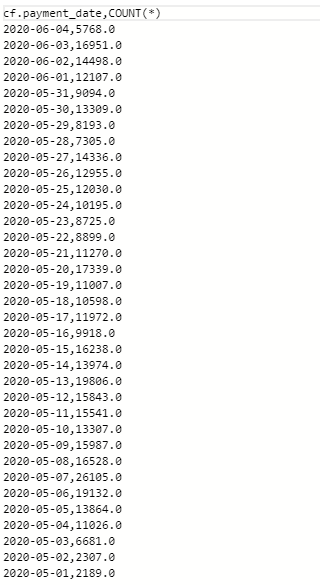
这是老数据
这是最新数据
请问一下 statement.executeUpdate 里面传的参数是什么内容?
能否在 catch else 里面增加 throw e?
statement.executeUpdate里面的参数是一组insert into {0} ({1}) values({2}) ON DUPLICATE KEY UPDATE {3}
如果有异常的话,会这样打出来
batchSqls 的内容能否打印一下看看?
这个 insert into 的sql语句直接复制到mysql client里面执行 能成功吗?
这个给我的感觉是写入进去了,因为spark流处理之后,tidb里面的数据总量和es里面的数据总量是一样的,都是动态增加的。只是昨天晚上发现那条数据更新之后,一直查不出来最新值,最后在终端更新了下,就查出来了最新值。会不会是tidb有缓存,还是别的原因导致的。
可以执行成功
tidb没有缓存的
有没有可能是 update 失败(例如拼接后的sql长度太长导致失败)?这样数据总量是对的
update (非insert) 失败的情况下 count(*)的结果是对的 不矛盾
失败了的话,会报错的呀。tidb没有这个表的插入报错记录,spark日志也没有报错,而且一个批次只有100条数据
明确下问题:
你好,
确认下,
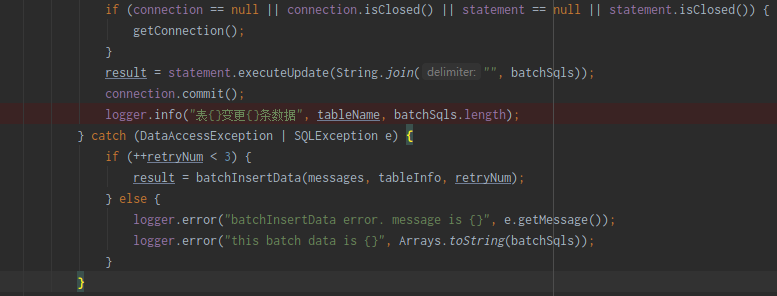
表 xxx 变更两条数据 的逻辑是什么。1.语句是insert into {0} ({1}) values({2}) ON DUPLICATE KEY UPDATE {3}这种insert update
2.这个统计逻辑重置位点之前是用的statement.executeUpdate的返回值,变更位点之后用的是statement.executeUpdate(String.join("", batchSqls));里面batchSqls数组的大小
![]() 关键是程序和tidb都没有报错,就不确定是不是成功了
关键是程序和tidb都没有报错,就不确定是不是成功了
我的理解和你类似,不知道程序是否发起了 sql 语句,或者是否到 tidb 真正执行了,这个还是需要排查的,从目前的信息来看,tidb 手动执行 sql 没有问题,tidb log 中无报错信息,唯独有程序的日志打印,需要核实下。