- 请使用 ps -ef | grep 检查下当前是否有进程已经启动占用这个目录
- lsof | grep /data/tidb/deploy/data_1/data 看下是否有占用,多谢。
- 看报错都是
[root@host-91 ~]# lsof | grep /data/tidb/deploy/data_1/data lsof: no pwd entry for UID 100
-
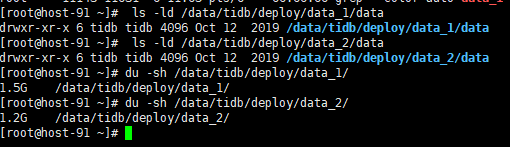
请检查下 ls -ld /data/tidb/deploy/data_1/data ,查看属主是不是有变化,你是否之前删除过所属用户比如tidb,之后重建了用户
-
当前无法启动的集群是否有数据丢失? 能否尝试缩容这些集群重新导入数据。 之后用统一的ansible 或者 tiup 管理。
怎么去缩容呢,是把异常的tikv节点在配置文件中去掉,然后重新启动吗
-
看store,当前已经有5个up的节点,你应该总共只有6个需要up吧,还有哪一个当前需要up的? 先确认下,感觉有些你可能一直启动重复的tikv实例。
"state_name": "Up" "state_name": "Down" "state_name": "Up" "state_name": "Up" "state_name": "Down" "state_name": "Down" "state_name": "Down" "state_name": "Up" "state_name": "Up"

在每个服务器ps -ef 检查下 tikv-server 的进程,确认是不是这5个都启动成功了。再手工启动下90的20161,看看能否启动,多谢。
“id”: 1056, “address”: “10.53.156.91:20161”, “labels”: [ { “key”: “host”, “value”: “tikv3_0” } ], “version”: “2.1.13”, “state_name”: “Up”
“store”: { “id”: 1058, “address”: “10.53.156.89:20162”, “labels”: [ { “key”: “host”, “value”: “tikv1_1” } ], “version”: “2.1.13”, “state_name”: “Up”
“store”: { “id”: 1060, “address”: “10.53.156.91:20162”, “labels”: [ { “key”: “host”, “value”: “tikv3_1” } ], “version”: “2.1.13”, “state_name”: “Up”
“store”: { “id”: 1001, “address”: “10.53.156.89:20161”, “labels”: [ { “key”: “host”, “value”: “tikv1_0” } ], “version”: “2.1.13”, “state_name”: “Up”
“store”: { “id”: 1059, “address”: “10.53.156.90:20162”, “labels”: [ { “key”: “host”, “value”: “tikv2_1” } ], “version”: “2.1.13”, “state_name”: “Up”
由于后面通过ansible的方式重启的,现在store只有 10.53.156.90:20162 10.53.156.89:20162 10.53.156.90:20161 这3个节点是up的
- 麻烦您再重新反馈下pd-ctl里store 的信息,请上传
- 如果只有这3个是up的,尝试启动89:20161。
(1) ps -ef | grep tikv-server 反馈结果
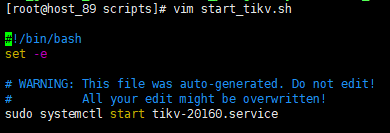
(2)在89的安装目录,找到20161的目录/scripts/start_tikv.sh 文件。执行 : ./start_tikv.sh 看下能否启动成功,
(3)如果启动失败,反馈20161的tikv.log 和 err日志。
- 那你检查下,你之前是怎么修改的呢? 为什么ansible里的脚本都不正确,多谢。
- 比如说如果这里应该是 20161的service,在 /etc/system/systemd/目录下有没有 20161.service文件,看下20161.service文件是什么内容,逐个对比,如果都有,并且每个脚本里的ip 端口都正确,可以尝试修改为20161,试试能否启动。
- 把 start_tikv.sh 里的脚本改正确后,应该就可以使用ansible管理了
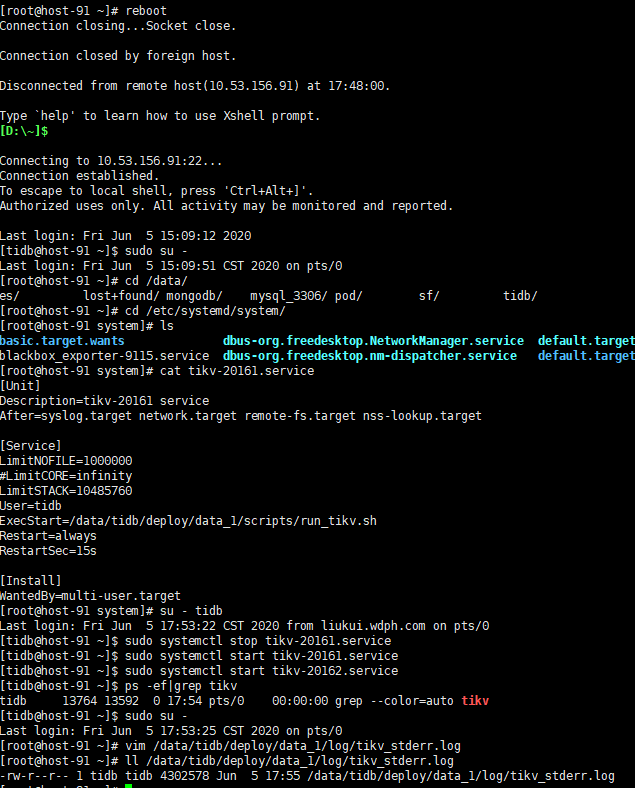
- 91 上也先按照启动 start_tikv.sh 的方法试一下,看看能否都先手工启动成功。
91启动不了,还是提示那个目录已被使用的报错
- 在91执行 ps -ef | grep tilv-server 确认下,是不是没有
- 如果没有,91 能把服务器重启下吗? 是不是有什么进程被hang了,没有释放干净。
好的,谢谢,我试试
请问缩容了吗? 如果还没有,麻烦再重启下tikv,我们再看看是否报错还是一样。多谢。
还没缩容,你说的是通过ansible重启还是 systemctl重启呢