麻烦把jq的信息也更新到帖子里,我先看下监控,多谢.

- [“compile sql error”] [conn=1030644] [error=“[parser:1149]syntax error, unexpected ‘?’”] [errorVerbose="[parser:1149]syntax error, unexpected 这种解析的sql报错很多,看下是否可以修改下.
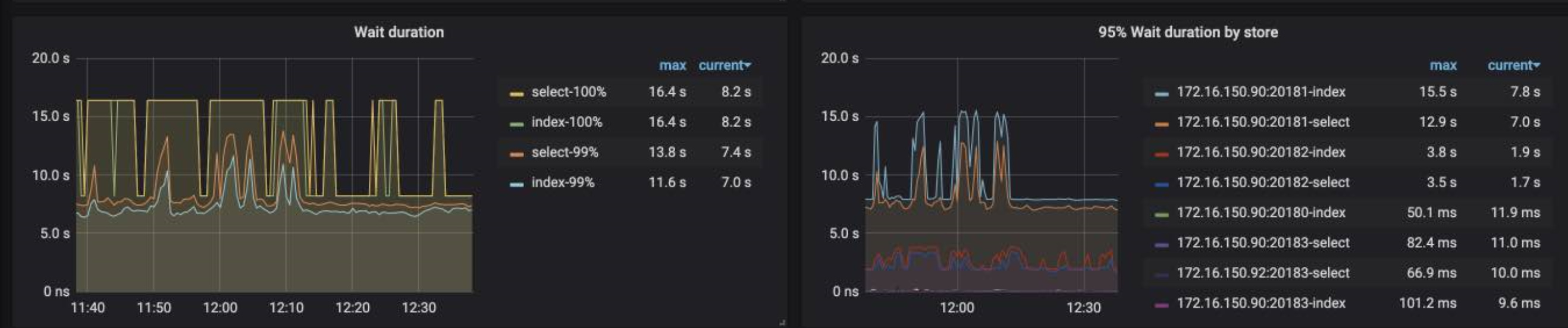
- 从监控信息看,coprocessor慢,主要在wait duration慢
- 查看慢日志都是SELECT
start_time,the_other_typeFROMmongo.mongo_mobile_raw_data_mobile_detailsWHERE ((use_time> ‘xxx’)) AND ((orderid= ‘xxx’)); - 尝试先优化这些sql. 从历史记录看,某些数据的执行时间很长.
Leader Balance 和 Region Balance 100% - #30,来自 lemontree8801 请帮忙上传这个表的表结构,多谢,
- [“compile sql error”] [conn=1030644] [error=“[parser:1149]syntax error, unexpected ‘?’”] [errorVerbose="[parser:1149]syntax error, unexpected 这种解析的sql报错很多,看下是否可以修改下.
SQL解析报错的问题我也很纳闷,一样的 SQL(不同的只有参数值),一会正常,一会报错。报错了的,手工执行也都是正常的。
另外,SQL 本身是优化过的(其实是同样的 SQL在不同的数据上跑),只是它执行不稳定,一会儿快一会慢。
[问题澄清]
数据库版本:V3.0.4
集群拓扑: 1个服务器部署了4个tikv实例 16core,128G
问题描述: tidb集群查询慢,并且会漂移到不同的store
[问题分析]
- 查看监控信息,发现主要慢在了coprocessor wait duration

- 查看90 这个服务器的 coprocessor cpu ,达到了250%,查看配置文件中配置的是3,按理说没有到达瓶颈
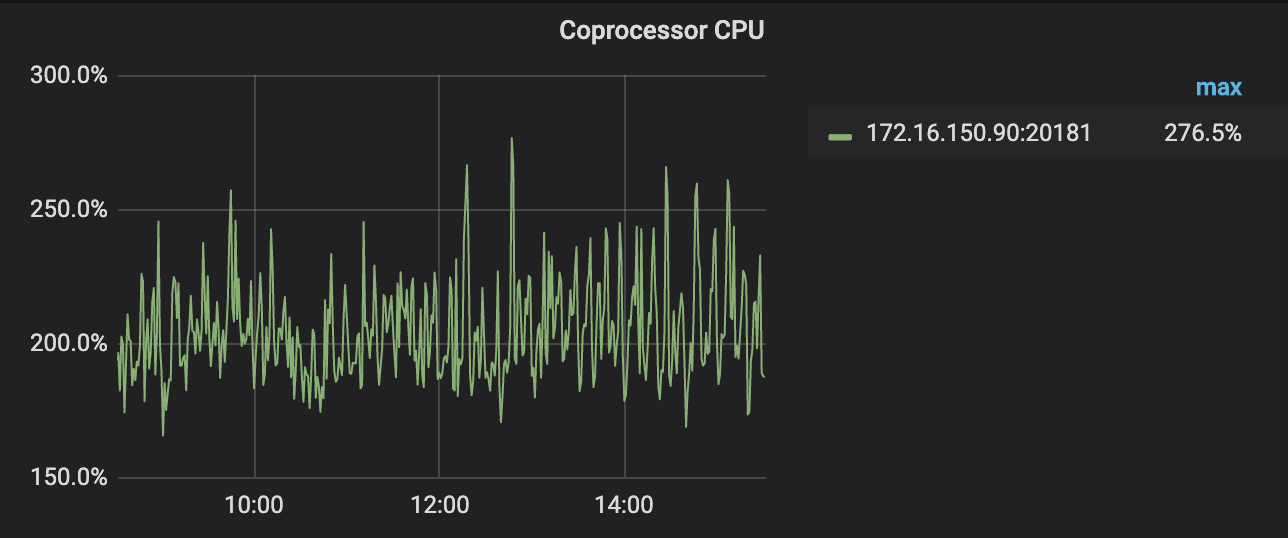
- 查看所有服务器的cpu,发现总的cpu已经打满,导致coprocessor cpu在没有达到最大值时,已经到达瓶颈
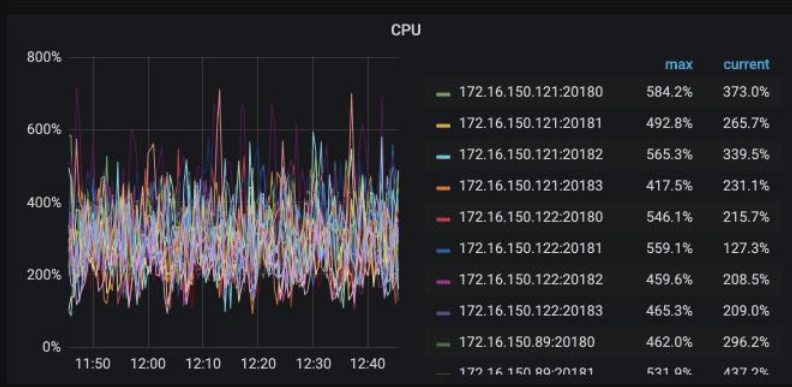
[下步计划]
- 由分析中的1和2可以看出,存在热点情况,请先按照热点问题排查处理
https://github.com/pingcap-incubator/tidb-in-action/blob/master/session4/chapter7/hotspot-resolved.md - 由分析中1,2,3看出集群已经到达瓶颈,这个时候,可以尝试先调整tikv参数配置:
[server]
grpc-concurrency = 2
[raftstore]
store-pool-size = 2
apply-pool-size = 1
raft-base-tick-interval = “2s”
[readpool.storage]
high-concurrency = 1
normal-concurrency = 1
low-concurrency = 1
[storage]
scheduler-worker-pool-size = 1
[readpool.coprocessor] #
high-concurrency = 2
normal-concurrency = 4
low-concurrency = 4
这样调整是希望可以针对整体cpu不足,给coprocessor多一些cpu使用,不具有普遍操作意义。
从每个参数对应的cpu可以看出,当前使用的最大值,可以先这样调整观察
- 如果调整后,还是无法满足要求,请尝试添加CPU,或者扩容机器,分散tikv实例
问题已解决,集群恢复正常。采取了以下措施:
- 相关表添加
SHARD_ROW_ID_BITS(p.s. 相关表没有主键,TiDB会自动产生自增的隐式主键),使写入热点、以及后续高频计算带来的读热点得以分散 - 部署了 @rongyilong-PingCAP 建议的调优参数,CPU消耗得以有效降低,不再成为影响正常吞吐的瓶颈
谢谢!![]()
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。