down store 是以前扩容遗留下来的,当时没操作好。那个 store 实际上已经不存在了。
这次有问题的 store 不是那个。
down store 是以前扩容遗留下来的,当时没操作好。那个 store 实际上已经不存在了。
这次有问题的 store 不是那个。
可以再看下那些变成秒级的 SQL 在 slow log 中的记录
嗯,给你看一点我想不明白的东西
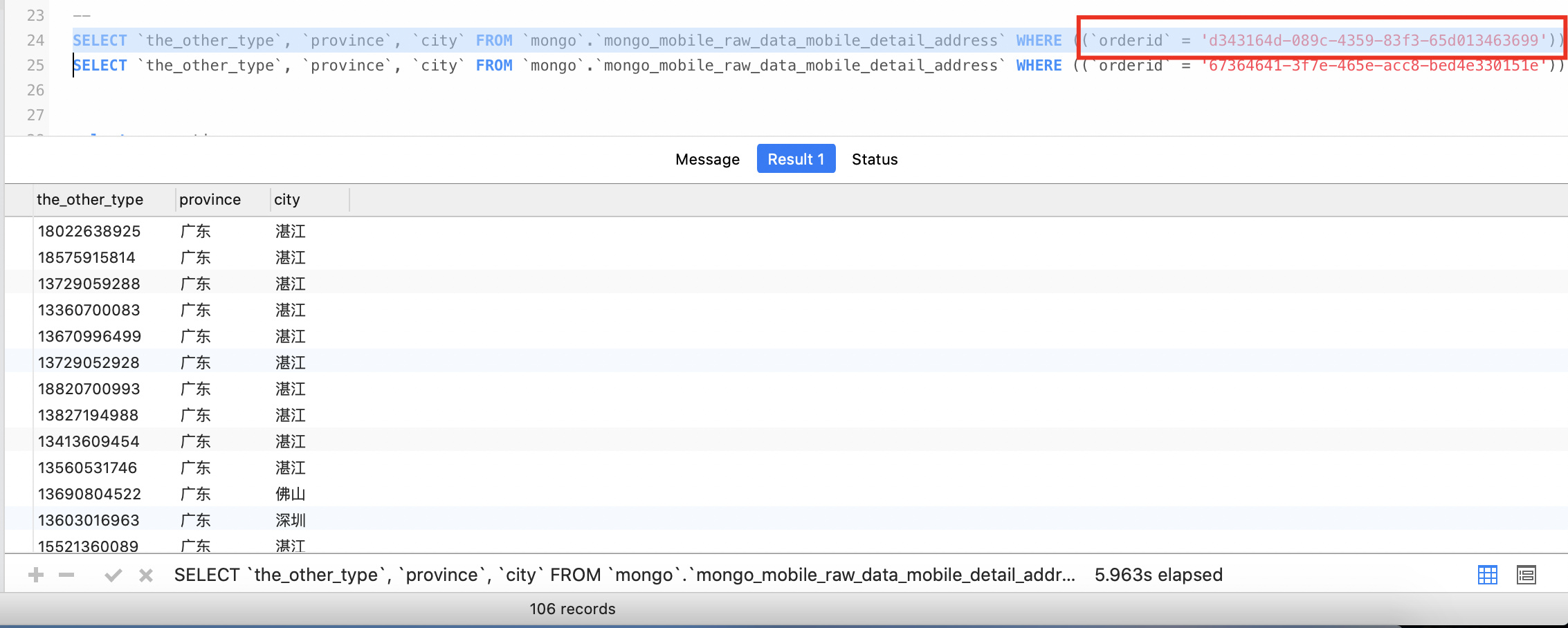
mongo_mobile_raw_data_mobile_detail_address 表的 orderid 是有索引的,查得的记录数也相差不大,但是查询时间相差太大了。
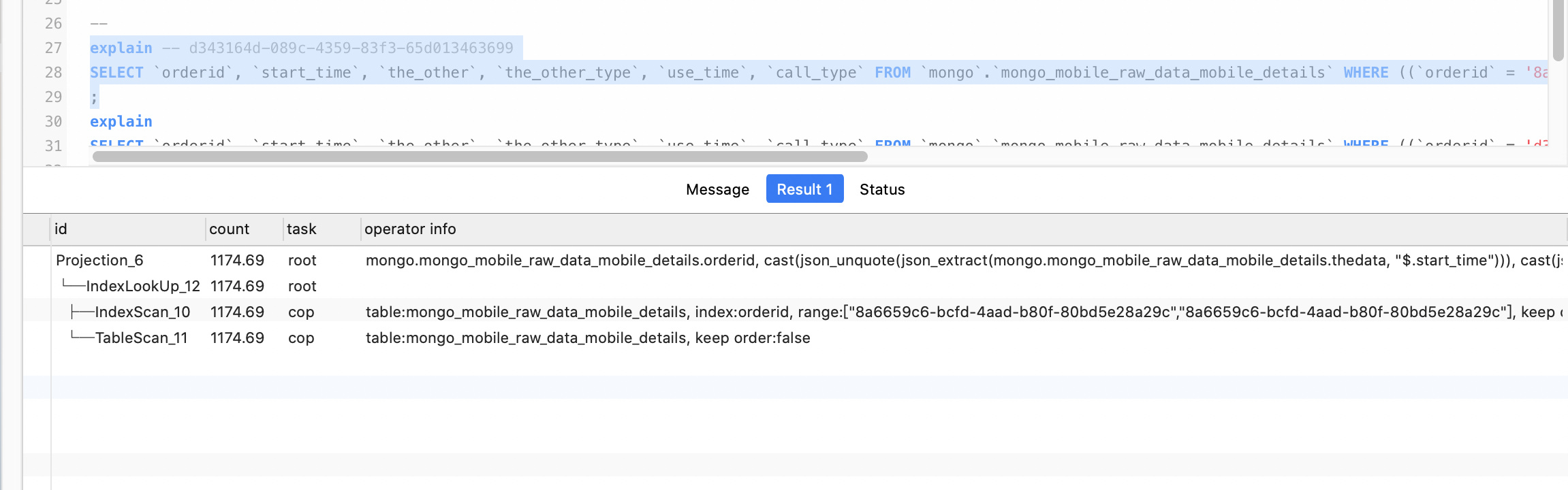
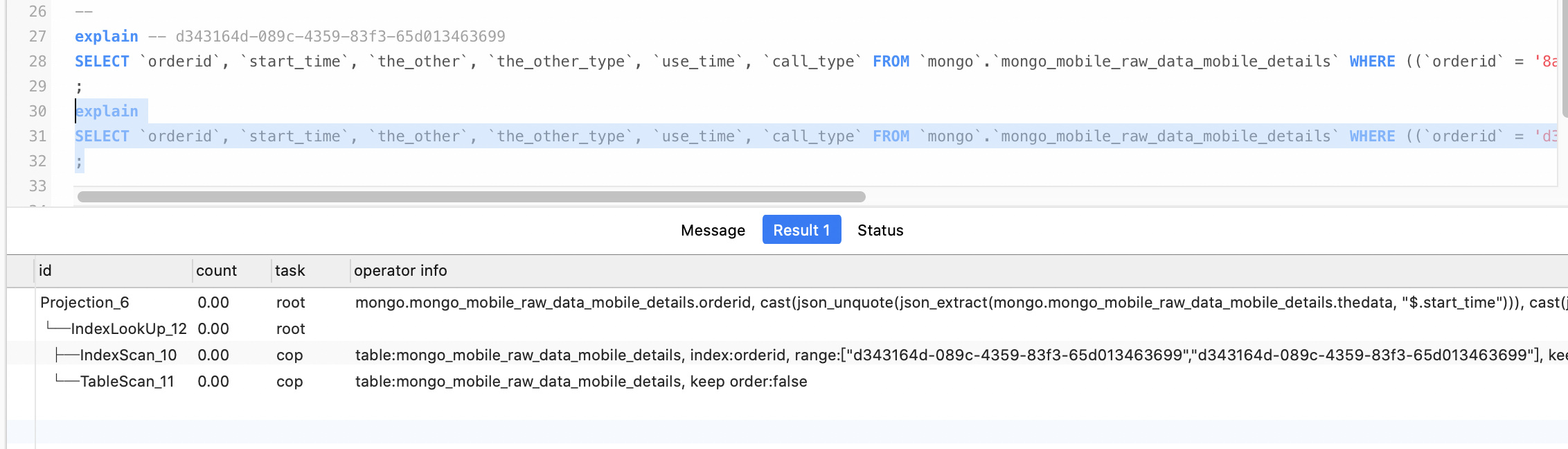
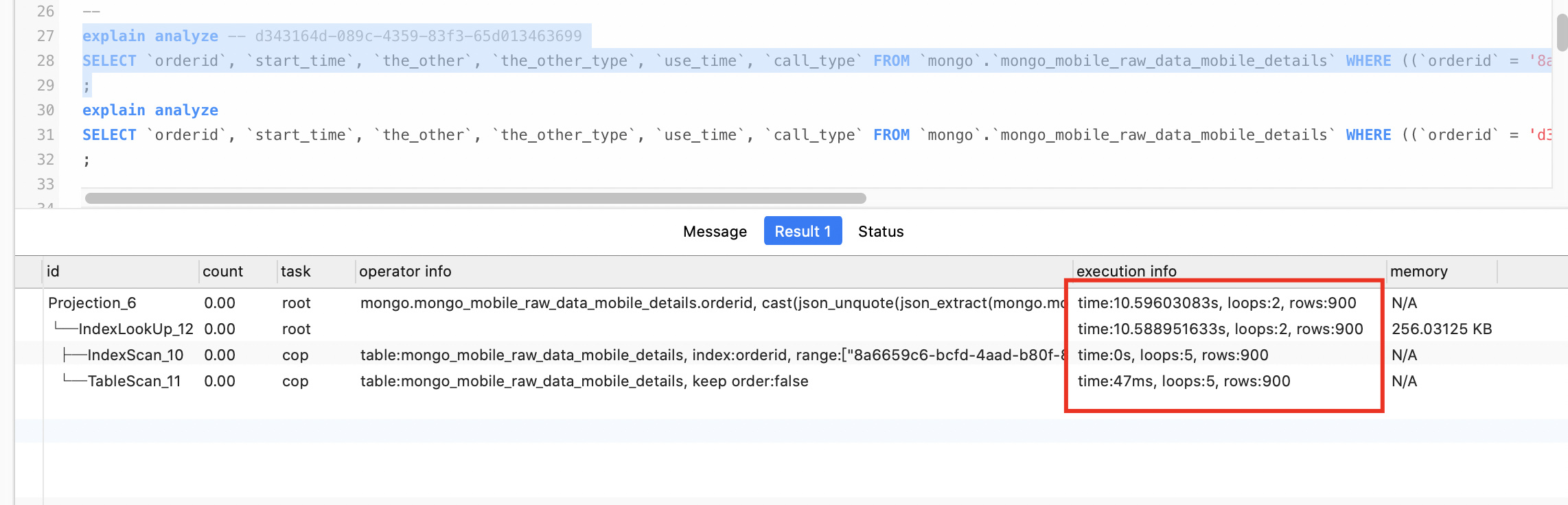
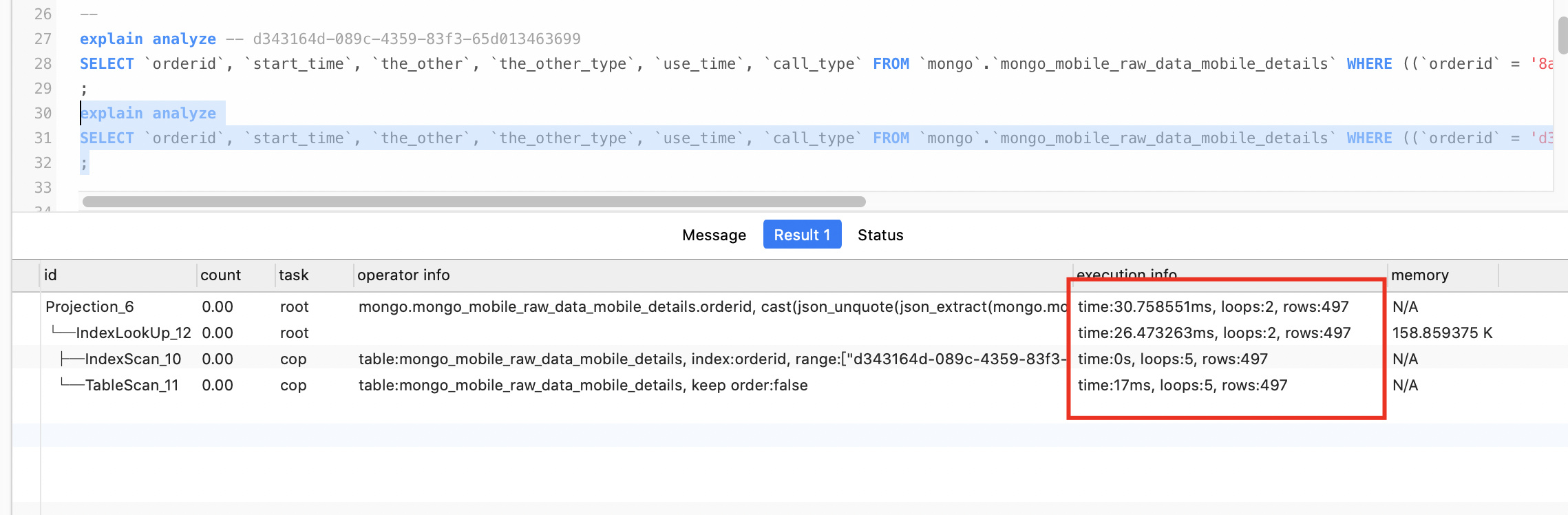
explain analyze 2个查询 看一下执行计划的情况 着重看一下扫了多少行数据
查询计划是一样的。现在重现不了了,速度正常了。
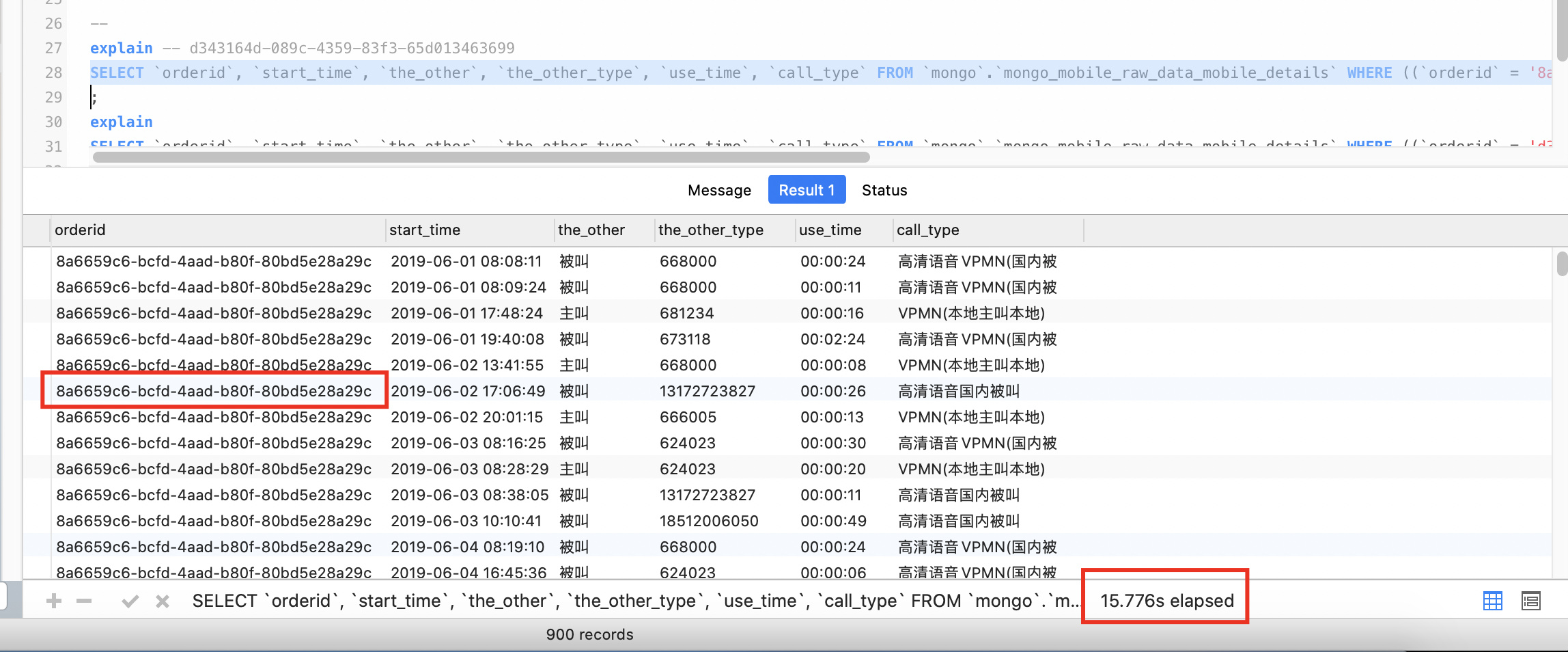
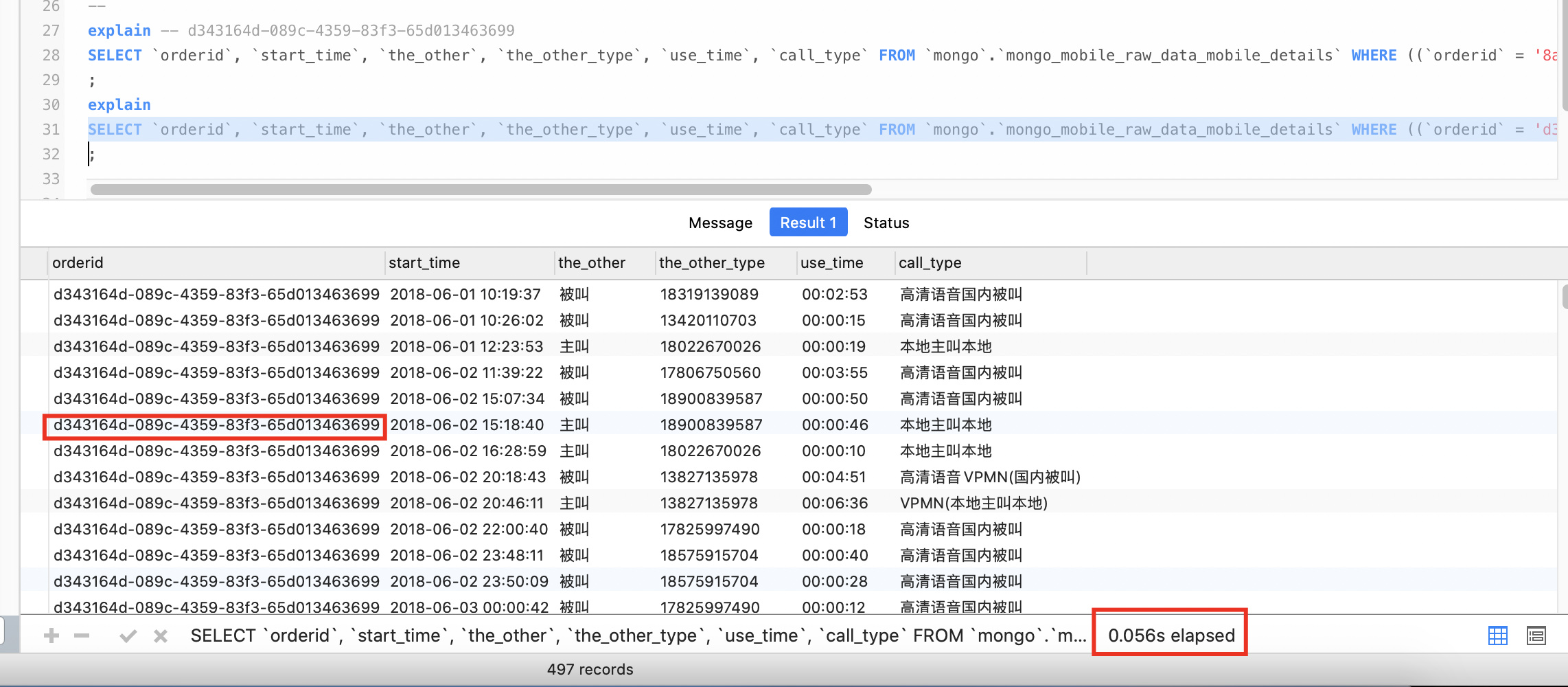
这次涉及的表是 mongo_mobile_raw_data_mobile_details,我挑了两个速度差异明显的截图如下:
慢的那个查询时间及查询计划,
快的那个查询时间及查询计划,
查询计划是一样的,我检查下来找不出差别。
您好:
1. explain sql对于相同的sql语句,执行计划应该是一样的,这里有可能是具体的where条件中代入值不同,导致扫描的key数量级相差比较大. 方便执行explain ananlze看下吗?
2. 麻烦新的问题创建个新帖子,尽量一个问题在一个帖子里答复,这样方便其他人查看,并且追踪问题也会高效很多,多谢。explain analyze …不是explain 这样后面会有具体的扫描行数。。可能就是楼上大佬说的 因为条件不一样 扫描的key 不同导致
按这个扫描量级 应该不会这么慢啊。。。TIKV的配置都一样吗?
TiKV 的机型、配置完全一样。并且,同一台机器的其他实例也正常啊。
(不过,提醒一下后面看到这个帖子的人,慢的 store 会迁移,最开始在 172.16.150。92:20182,然后是 172.16.150.121:20180,现在是 172.16.150.121:20182)
方便提供一下 PD 监控面板中 Operator 和 Statistics-balance 相关的监控么,我这边看下 region 调度的情况会不会有影响
确认一下目前需要看的实际是两个问题是吧
第一个问题:往 TiDB 导入大量数据之后,查询变慢,从亚秒级变成了秒级的,相同的查询在满日中记录有执行 0 点几秒的,有执行十几秒的,手动执行的时候速度正常
第二个问题:从 95% Wait duration by store 监控看到,有某一个 store 比较慢,且这个 store 随着时间变化,会迁移。
关于第一个问题可以看下慢日志记录的信息,对应 0 点几秒和十几秒执行的 SQL 对应的耗时阶段是哪部分不同,定位到差异部分。v3.0.5 以上版本慢日志中会记录运行 SQL 当时的执行计划,可以判断是否有执行计划不稳定的问题,这边考虑升级集群吗?
关于第二个问题,从提供的 PD 监控看没有 Hot Region 的分布,目前查询慢的情况是一直出现还是导入完数据之后出现了一段时间,后续就正常了?
差不多是这样,慢的情况看起来是在 导入了大量数据 或者 是对要读取的表做了比较大的插入 操作之后比较明显。然后调查原因的时候,发现有一个 store 特别慢,看起来像是等待时间比较长,而且随着时间的变化,这个特别慢的 store 还会迁移。
没有大量数据写入的时候是会恢复的比较正常,查询变快,那个慢的 store 的 wait duration 短了很多。
升级集群的提议我们考虑一下。
导入完数据之后一个 store 特别慢,且随着时间变化,慢 store 会迁移,从现象看比较容易怀疑是 region 调度产生的影响,但是从提供的 PD 监控看是 last 1 hour 的监控信息,这个应该是已经恢复正常了的时候的监控了吧。
可以看下导入数据完成那段时间以及到慢 store 发生迁移到最终恢复正常这段时间的 region 调度情况 另外可以排查一下 TiKV-Detail 监控中慢 store 发生迁移时,除了 wait duration 监控指标外,还有什么指标也对应发生了迁移的
嗯,刚注意到慢 store 又发生了一次迁移。另外,有关 region 调度的历史记录从哪里可以获得?
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
上传这个时间段的tidb日志,
请查看集群中是否存在大的region ,反馈以下信息,多谢. 使用jq查询
./bin/pd-ctl -d region | jq “.regions | map(select(.approximate_size > 96)) | length”
./bin/pd-ctl -d region | jq “.regions | map(select(.approximate_size > 128)) | length”
./bin/pd-ctl -d region | jq “.regions | map(select(.approximate_size > 256)) | length”
./bin/pd-ctl -d region | jq “.regions | map(select(.approximate_size > 512)) | length”