作者:靳献旗,汽车之家 DBA
1. 集群概述
1.1 引言
汽车之家(NYSE:ATHM)成立于 2005 年,为消费者提供优质的汽车消费和汽车生活服务,助力中国汽车产业蓬勃发展。
汽车之家数据库种类较多,包括 SQL SERVER、MySQL、TiDB、MongoDB、PG。我们从 2018 年 9 月开始调研,测试 TiDB,到目前为止,线上有 4 套 TiDB 集群,服务器 40+ 台。涵盖的业务包括论坛,车主价格,关注关系,爬虫,内容主数据,广告实时报表等。目前我们正在测试 TiFlash,用于列存场景。
在使用 TiDB 的过程中,我们遇到过一些问题,积攒了一些经验。由于篇幅有限,下面主要分享一次读写冲突的解决案例,希望能够对其他 TiDB 用户有所帮助。
1.2 集群信息
| 模块名称 | 版本信息 | 数量 |
|---|---|---|
| tidb | v3.0.9 | 5 |
| pd | v3.0.9 | 3 |
| tikv | v3.0.9 | 12(单机多实例) |
| pump | v3.0.9 | 4 |
| drainer | v3.0.9 | 5 |
本 TiDB 集群主要用于内容主数据项目,内容主数据项目,实现了汽车之家全平台内容的一致化,即所有内容展示数据的一致、所有内容状态及对外显示的统一、所有内容源头的统一。后续项目规划是接入所有之家内容类系统所产生的数据,为内容类数据制定统一标准,并为所有业务前台系统提供中心化的一致性出口。
1.3 集群拓扑
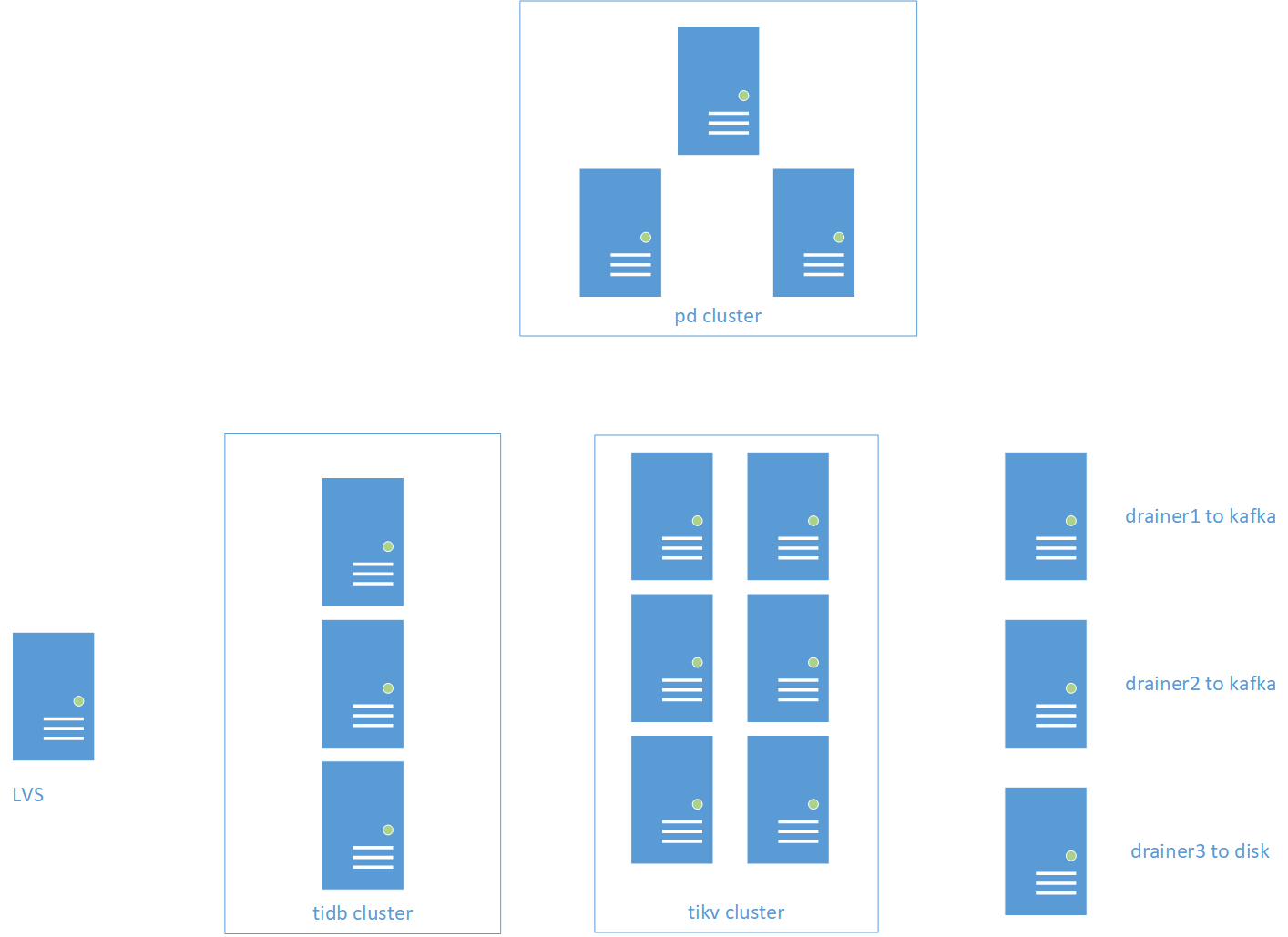
说明: 业务数据通过 Otter 从 MySQL 向 2 个 TiDB 节点同步数据,另外 3 个 TiDB 节点用于业务访问。4 个 Drainer 实时同步 TiDB 数据到下游 Kafka 集群用于获取 TiDB 增量数据,然后汇总成业务数据,1个 Drainer 同步 TiDB 数据到服务器磁盘,用于简单问题分析,比如某个时间段 TPS 特别高,可以利用 reparo 工具解析指定时间段内的 binlog 来分析问题。
1.4 优化后的效果
优化后的效果非常明显,下面是 SQL 99 的影响时间
SQL 999 从 130多ms 到 30ms
SQL 99 从 120多ms 到 16ms
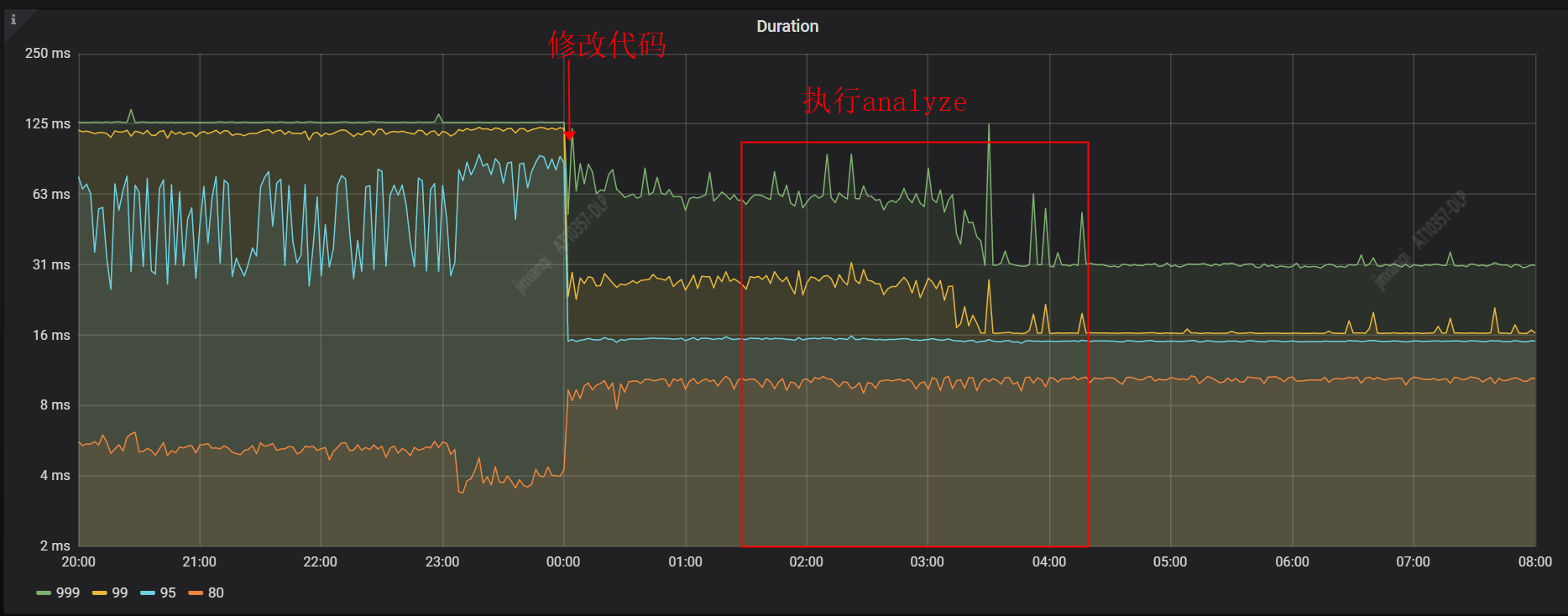
下面是 SQL 响应时间监控图
从监控图可以看到,12 点修改代码上线后,集群响应时间大幅下降,其中 1:30 到 4:30 在更新统计信息。
下面是 QPS 监控图
QPS 也明显提升,从 8K 左右上升到 10K 以上

下面是 tikvFaskLock 监控图
tikvFaskLock 从 300 多几乎变为 0

2. 问题描述及分析
业务方反馈,在刷历史数据时,TiDB 集群响应特别慢。收到反馈后,我们开始分析问题。
2.1 分析慢日志
首先想到的是,集群慢是否是由于慢 SQL 导致的呢?我们使用 pt-query-digest 工具对慢日志进行分析,大部分都是如下慢 SQL,平均耗时 80ms
Update table_name SET value='2' WHERE biz_id=185654 AND type='oaa' AND field='oaa_SerializeEndPage';
SQL 本身很简单,难道是缺少索引或者索引不合理?
查看一下执行计划,执行计划正常,点查
mysql> desc Update table_name SET value='2' WHERE biz_id=185654 AND type='oaa' AND field='oaa_SerializeEndPage';
+-------------+-------+------+------------------------------------------------------------+
| id | count | task | operator info |
+-------------+-------+------+------------------------------------------------------------+
| Point_Get_1 | 1.00 | root | table:table_name, index:main_data_type biz_id field |
+-------------+-------+------+------------------------------------------------------------+
查看表结构, (biz_id,type,field) 是唯一索引,唯一索引,点查,为什么还会这么慢?竟然耗时 80ms。
2.2 查看监控
我们继续分析,看看监控指标是否有异常,从监控看到 tikvLockFast 迅速从 10 以下升高到 300 多将近 400,集群响应时间 (SQL duration 99) 也随之升高。
【 tikvlockfast 】:读写冲突,读请求碰到还未提交的数据,需要等待其提交之后才能读。少量这个错误对业务无影响,大量出现这个错误说明业务读写冲突比较严重,冲突严重则会大幅降低集群整体的效率。
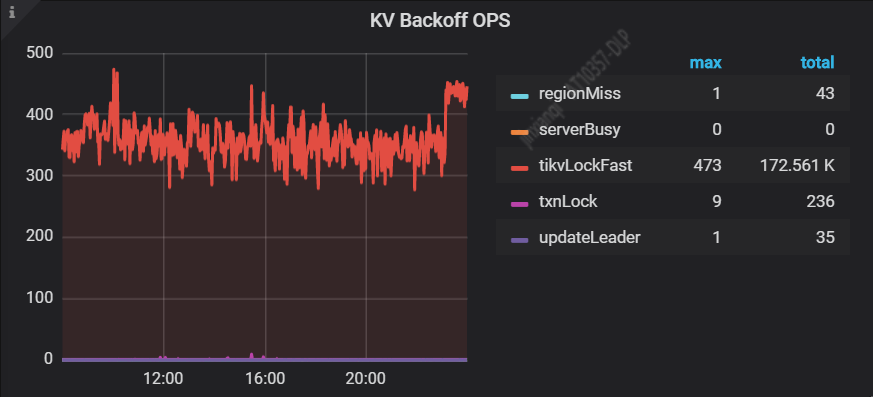

从以上监控可以得知,目前集群的读写冲突很严重。我们知道,对于乐观锁,如果冲突严重,一些事务就需要不断重新执行,这样就会做大量的无效工作,降低整体的效率。
2.3 分析 Binlog
为了进一步了解集群的情况,我们分析一下 Binlog 。之前部署了一个 Drainer ,将所有库的数据同步到服务器磁盘上,便于分析问题。借助 reparo 工具解析了 10 分钟的 Binlog,未发现明显异常。
统计所有表的 update delete insert 的次数
grep -a "schema:" log_16_10.log|awk '{print $NF}'|sort -r|uniq -c 825670 Update
17936 Insert
500 Delete
统计表 table_name 在这段时间内的增删改次数
grep -a "table_name" log_16_10.log|awk '{print $NF}'|sort -r|uniq -c
5692 Update
3892 Insert
这里再推荐一下 reparo 工具,对于习惯 MySQL 的用户来说,解析 Binlog 来分析一些问题比较方便,比如通过分析某段时间内的 Binlog 来了解数据库的 update/insert/delete 情况。但是对于 TiDB 来说,分析 Binlog 没那么方便,我们可以部署一个 Drainer 同步TiDB Binlog 到磁盘,借助 reparo 来分析指定时间段内的 Binlog,非常方便。
vi reparo.toml
将下面 2 行的时间修改为 binlog 起始时间和结束时间
start-datetime = "2020-02-27 09:20:00"
stop-datetime = "2020-02-27 09:21:00"
2.4 分析 TiDB 日志
我们已经知道集群目前存在大量读写冲突,继续分析 TiDB 日志看看有没有什么其它异常,分析 TiDB 日志发现,有不少 “Write conflict” 关键字,说明集群同时存在写写冲突。
【Write conflict】:乐观事务中的写写冲突,同时多个事务对相同的 key 进行修改,只有一个事务会成功,其他事务会自动重取 timestamp 然后进行重试,不影响业务。如果业务冲突很严重可能会导致重试多次之后事务失败,这种情况下建议使用悲观锁。
[2020/03/13 16:33:32.503 +08:00] [WARN] [session.go:435] ["can not retry txn"] [conn=52594] [label=general] [error="[kv:9007]Write conflict, txnStartTS=415259272772845655, conflictStartTS=415259272772845656, conflictCommitTS=415259272772845671, key={tableID=2628, indexID=3, indexValues={1848124051021627392, 3314544528, }} primary={tableID=2628, indexID=3, indexValues={1848124051021627392, 3314544528, }} [try again later]"] [IsBatchInsert=false] [IsPessimistic=false] [InRestrictedSQL=false] [tidb_retry_limit=10] [tidb_disable_txn_auto_retry=true]
用下面命令统计一下 Write conflict 的次数
grep "Write conflict" tidb.log|grep tableID|awk -F'key={' '{print $2}'|awk -F',' '{print $1}'|awk -F'=' '{print $2}'|sort -r|uniq -c|sort -k1|head -10
11088 3807
1640 2651
209 2633
42904 2628
9 624
左边一列表示关键字 Write conflict 的次数,右边一列表示 table_id ,可以通过下面命令找出冲突次数最多的表
select * from information_schema.tables where TIDB_TABLE_ID=3807\G
通过上面的命令,我们可以找出冲突最多的表,但是无法知道是哪些 SQL 导致的冲突。
从以上分析可以得知,集群读写冲突和写写冲突都很高,尤其读写冲突,导致了集群响应时间下降,知道原因后,我们接下来看看如何解决这个问题。
3. 问题解决
3.1 开启内存锁
我们先来看下 TiDB 的冲突检测机制,更详细的内容请参考 TiDB 官方文章
乐观事务下,检测底层数据是否存在写写冲突是一个很重要的操作。具体而言,TiKV 在 prewrite 阶段就需要读取数据进行检测。为了优化这一块性能,TiDB 集群会在内存里面进行一次冲突预检测。
作为一个分布式系统,TiDB 在内存中的冲突检测主要在两个模块进行:
- TiDB 层。如果发现 TiDB 实例本身就存在写写冲突,那么第一个写入发出后,后面的写入已经清楚地知道自己冲突了,无需再往下层 TiKV 发送请求去检测冲突。
- TiKV 层。主要发生在 prewrite 阶段。因为 TiDB 集群是一个分布式系统,TiDB 实例本身无状态,实例之间无法感知到彼此的存在,也就无法确认自己的写入与别的 TiDB 实例是否存在冲突,所以会在 TiKV 这一层检测具体的数据是否有冲突。
其中 TiDB 层的冲突检测可以根据场景需要选择打开或关闭,具体配置项如下:
# 事务内存锁相关配置,当本地事务冲突比较多时建议开启。
[txn-local-latches]
# 是否开启内存锁,默认为 false,即不开启。
enabled = false
我们尝试将 TiDB 层的冲突检测关闭,测试一下是否能达到我们的预期:降低冲突,降低集群响应时间。
关闭之后测试,问题依旧。
3.2 缓冲层加锁
是不是并发更新太多,写写冲突太多导致的集群响应慢?
和开发沟通后,决定采取加锁的方法:在缓冲层对数据加锁,避免并发更新同一条数据(避免唯一索引冲突),代码上线后,测试,问题依旧,一旦刷数据集群响应时间立刻升高。
伪代码如下
long times = System.currentTimeMillis();
String lockKey = "lock:" + 唯一索引1 + ":" + 唯一索引2;
try {
boolean isResult = false;
while (i < 4) {
boolean lock = RedisHelper.lock(lockKey, times);
if (lock) {
return dbDataHelper.execTSQL("BEGIN; " + String.join(";", tSqlList) + " COMMIT ;");
break;
} else {
i++;
ThreadUtils.sleep(10);
}
}
return isResult;
} catch (SQLException e) {
LogHelper.logError("错误", e, tSqlList.toString());
return false;
} finally {
RedisHelper.unlock(lockKey, times);
}
3.3 开启显示事务
再次和业务沟通,了解刷数逻辑,其实刷数逻辑很简单:数据在表中存在则 ignore 然后更新,数据不存在则插入再更新。刷数据的 SQL 类似如下(部分内容做了脱敏处理)
Insert IGNORE INTO table_name (biz_id,type,field) values(185654,'oaa','oaa_SerializeEndPage') ; Update table_name SET value='2' WHERE biz_id=185654 AND type='oaa' AND field='oaa_SerializeEndPage';
数据刚刚 insert,立刻 update,因为 insert 和 update 不在同一个事务里面,事务之间存在读写冲突,并发量越大,读写冲突越明显。我们将这 2 个 SQL 放在一个事务里来避免读写冲突,再进行测试。
将下面 SQL
Insert IGNORE INTO table_name (biz_id,type,field) values(185654,'oaa','oaa_SerializeEndPage') ; Update table_name SET value='2' WHERE biz_id=185654 AND type='oaa' AND field='oaa_SerializeEndPage';
改为
begin;
Insert IGNORE INTO table_name (biz_id,type,field) values(185654,'oaa','oaa_SerializeEndPage') ; Update table_name SET value='2' WHERE biz_id=185654 AND type='oaa' AND field='oaa_SerializeEndPage';
commit;
修改完毕,上线,测试,观察效果,集群响应时间迅速降低,tikvlockfast 几乎消失,业务方反馈良好
SQL 999 从 130多ms 到 30ms 左右
SQL 99 从 120多ms 到 16ms 左右
到此,基本上解决了我们的问题,集群响应时间大幅降低,业务方反馈良好。
3.4 尝试悲观锁
虽然读写冲突解决了,但是还存在少量(不算太少?)的写写冲突,做技术的都喜欢追求极致,那我们何不尝试一下悲观锁是否能解决这个问题呢?
接着,我们开启了【悲观锁+显示事务】,继续测试,观察集群状态,查看 TiDB 日志。
开启悲观锁的命令如下
set @@global.tidb_txn_mode = 'pessimistic';
下面是【悲观锁+显示事务】和【乐观锁+显示事务】的性能对比
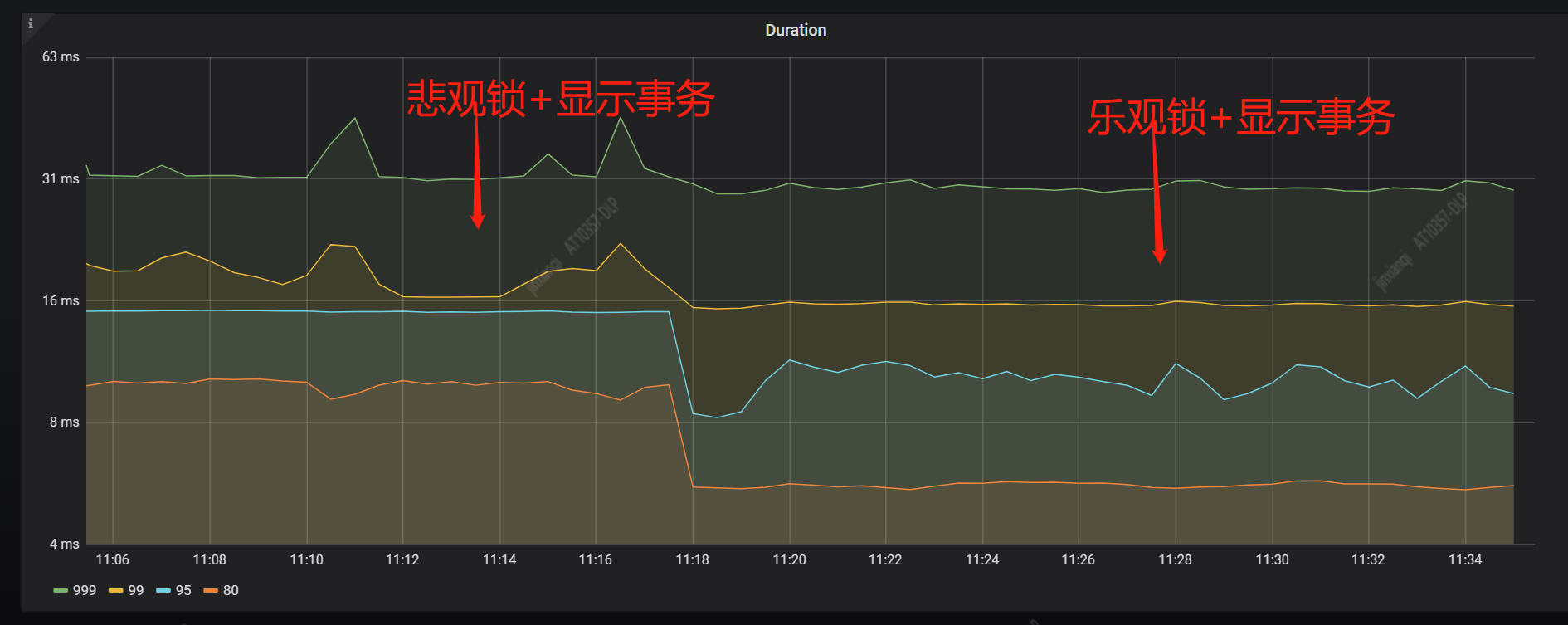
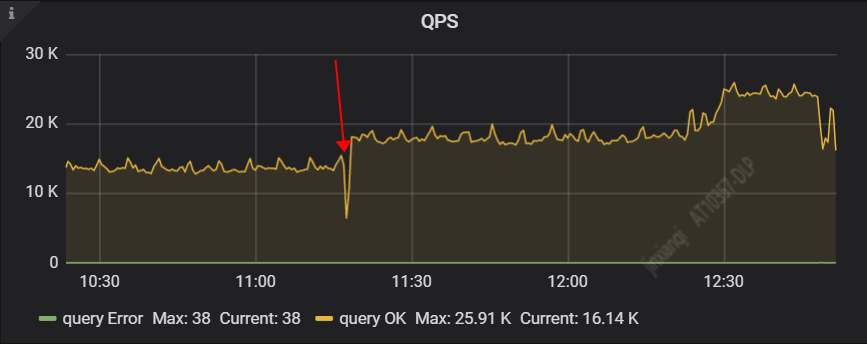
从上面监控图上的响应时间和 QPS 可以看到,针对我们这个刷数据的场景,【乐观锁+显示事务】的性能要略好于【悲观锁+显示事务】的性能。
原因可能是因为:
目前集群中的主要矛盾(读写冲突)已解决,只是存在部分写写冲突,此时由乐观锁改为悲观锁后,悲观锁执行时加锁,慢,耗时长,乐观锁在验证时加锁,快,耗时短。悲观锁在 TiDB 中有等待锁的逻辑,所以增加了执行事务的排队等待时间,所以导致延迟高于乐观锁。
同时,从官方获知,4.0 版本的悲观锁有了大幅度的改进,目前已经有 50% 以上的性能提升。
4. 遗留问题
目前,我们采取【乐观锁+显示事务】的优化方式,集群运行稳定,响应速度非常快。虽然读写冲突解决了,但是 TiDB 的日志中还是存在不少的 Write conflict 关键字,如何分析 Write conflict ?是否可以提供类似 MySQL 视图来查看相关锁信息?相信很多 DBA 都比较期待,![]()
select * from information_schema.innodb_lock_waits\G
5. 总结
本文抛砖引玉,从一次解决读写冲突的案例入手,描述了解决问题的整个过程。同时,我们也看到了乐观锁比较适用于冲突少的场景,对于冲突比较高的场景效率会大幅下降,此时,我们可以从业务逻辑出发去优化,降低冲突。当然,值得欣慰的是,针对冲突高的场景,TiDB 目前已经提供了悲观锁的方案,欢迎大家试用。
6. 感谢
解决问题的过程中,多次和仲舒沟通交流,感谢仲舒的大力支持和帮助,感谢 TiDB 提供这么强大的分布式 NewSQL 数据库。感谢开发同学(建瑞)积极的配合,最终解决了问题。