hanson
(hanson)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v3.0.11 DM 1.0.3
- 【问题描述】:
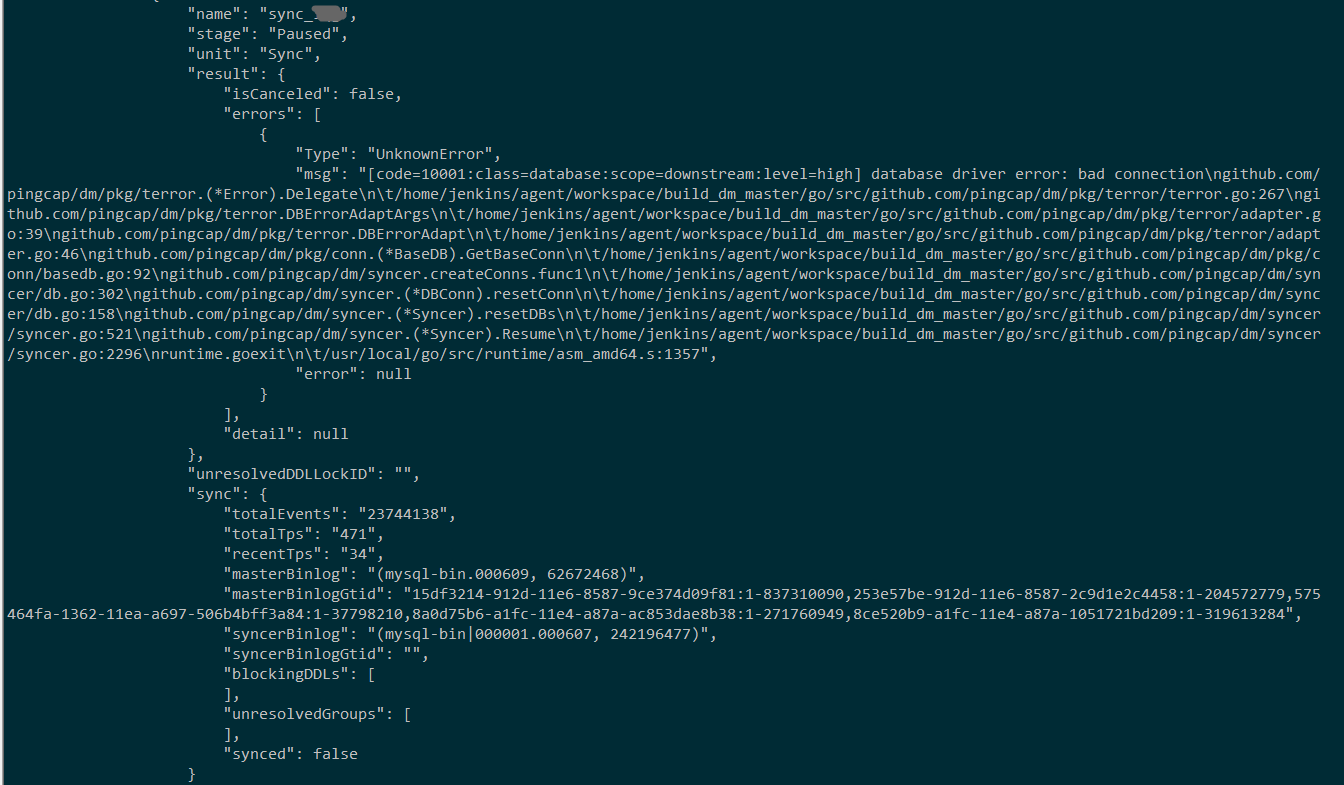
上游mysql为阿里云rds,版本:5.6,近几天已发现同步中断3次,查看中断位点binlog信息,都是update 同一个表的记录,表结构中有两个字段是longtext,总共有58个字段
query-status报错信息如下:
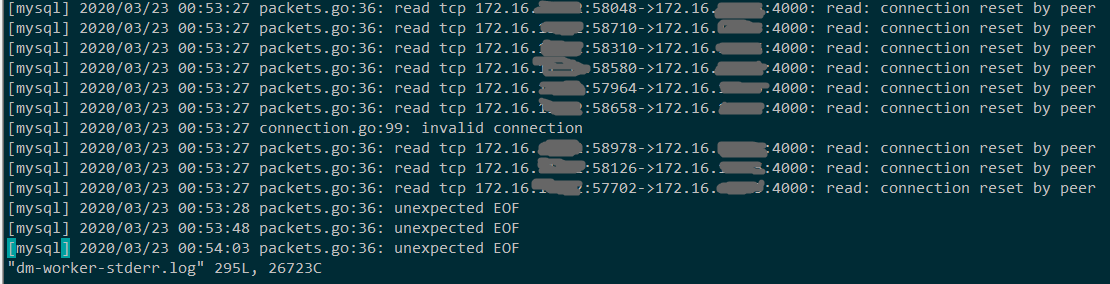
dm-worker报错日志:
dm-worker-stderr.log
这个问题是不是表中有longtext字段的原因导致?
使用resume-task不管用,只能stop-task再start-task才能解决
把觉得有问题的 update 语句拿出来到 tidb 中执行下,看看有问题吗?
官网有个文档
1.0.4 之前的版本,resume 可能不一定能成功。
DM 1.0.4 release notes: https://pingcap.com/docs-cn/stable/reference/tools/data-migration/releases/1.0.4/
修复到下游 TiDB 连接异常导致同步暂停后, resume-task 可能无法正常恢复同步的问题
hanson
(hanson)
4
问题定位到了,是tidb重启了。发现在重启之前,有个sql直接导致OOM,tidb节点是64G内存。刚把语句拿出来执行一下,瞬间tidb oom
表结构字段信息
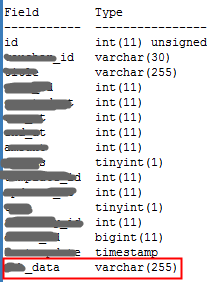
只使用了最后一个字段:xx_data ,语句如下:
select xx_data
from a
group by xx_data
order by xx_data
limit 5000
表a记录数9千万,xx_data存放的记录类似json格式的数据,请问这样语句是不支持吗?
hanson
(hanson)
6
添加索引后,观察了一晚上,没有出现oom,看监控内存使用量很少。
应该就是全表扫描导致oom了
system
(system)
关闭
8
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。