为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.3
- 【TiDB 版本】:1.0.2
- 【问题描述】:
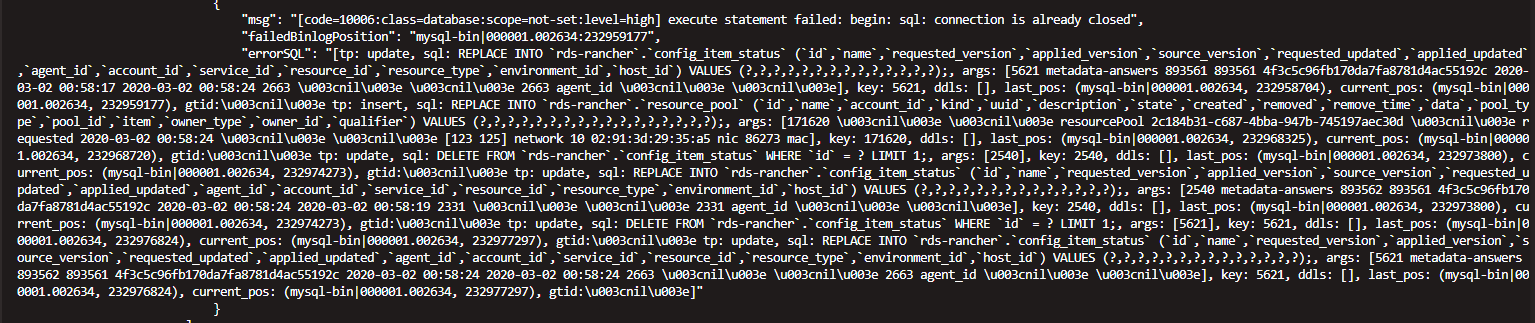
在同步数据的过程中出现以下报错,上游是阿里云 relay.meta 中的 binlog-pos是增长的
1:query-status taskname查询的日志

2:dm-worker的日志
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
1:query-status taskname查询的日志
connection close , 检查下下游 tidb 进程是否正常
1:正常,relay.meta 中的 binlog-pos是增长的
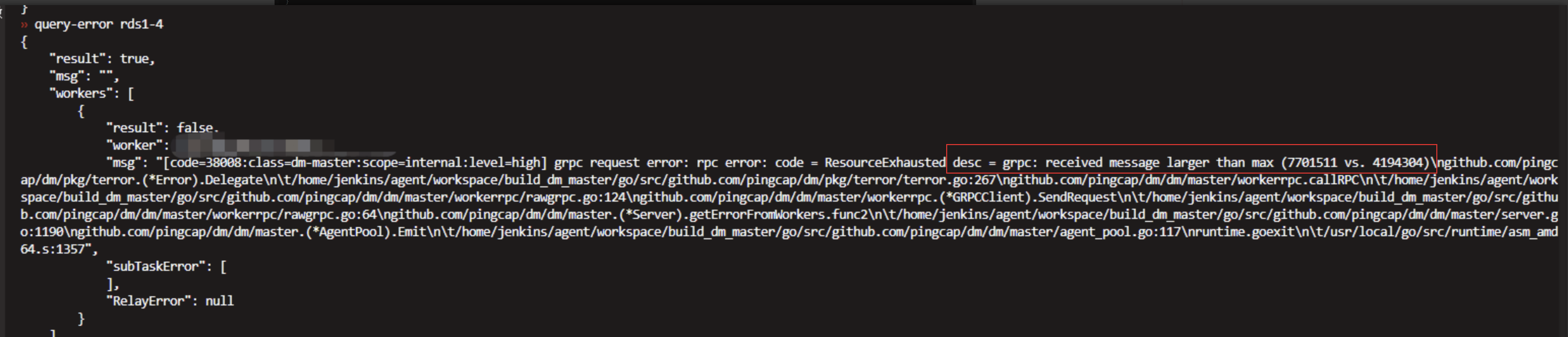
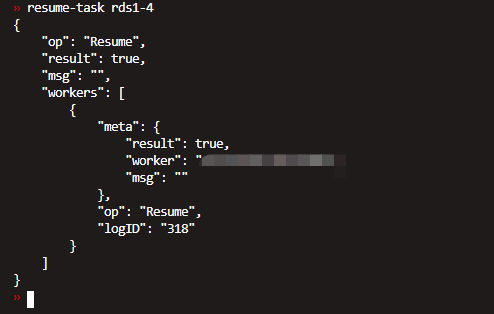
resume task 能否启动?
1:可以
![]()
可以查看一下官方文档关于 DM 常见错误的修复文档:
建议检查一下 dm-master 与 DM 组件之间通信是否正常
通信是正常的
我知道如何重置任务的操作,重新开始同步需要改worker的gtid设置吗?如果要改的话,如何找到最开始的gtid信息 上游是rds
可以看下 mydumper 备份文件是否还存在,mydumper 备份的 metadata 文件会记录最开始备份恢复的 GTID 信息
这个是部署worker生成的文件吗?
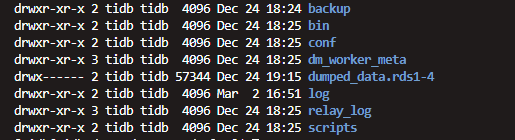
如果不需要重新拉取 relay log 的话,可以不重新设置 worker 的 gtid
需要重新拉取,不确定relay log 是否完整
如果 woker 配置文件中配置了 enable-gtid=true 那么重置任务时,需要将 woker 配置文件中 relay-binlog-gtid置空,DM 会自动找最新的GTID 点,不需要手动指定
如果enable-gtid=false ,那么不需要设置
1:我配置了 enable-gtid=true
2: 重新部署的时候也就是把 relay_log 文件下的所有文件删除然后重新部署就可以了是吗?
3:worker中配置的relay_binlog_gtid是否需要改动?