tidb4.0.13版本
问题描述 有个业务sql是select * from uk in (xxx,xx,xx),in 是个唯一键,里面的值很多,大概一万多个,所以跑起来的性能有点差,大概是1.几秒
执行计划如下
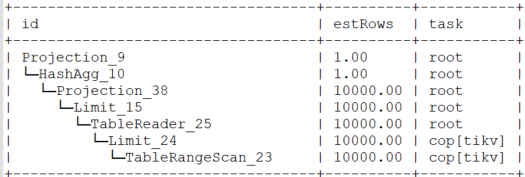
后来改写成union后性能反而更差了,大概需要45s才能出结果,改成union all,大概20秒出结果。
union的执行计划
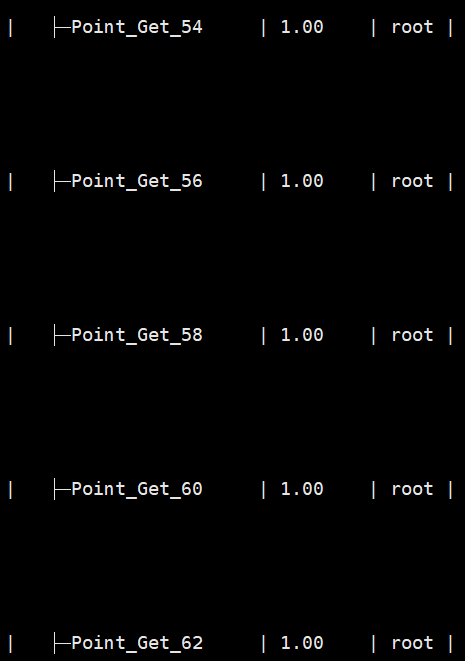
想请教一下,union的性能为什么反而比in差呢?
tidb4.0.13版本
问题描述 有个业务sql是select * from uk in (xxx,xx,xx),in 是个唯一键,里面的值很多,大概一万多个,所以跑起来的性能有点差,大概是1.几秒
执行计划如下
后来改写成union后性能反而更差了,大概需要45s才能出结果,改成union all,大概20秒出结果。
union的执行计划
想请教一下,union的性能为什么反而比in差呢?
in 是个唯一键 (这个是关键条件)
in 逻辑优化可以变成 pointBatchGet ,直接走 KV 接口了
union 则需要 DistSQL,需要在tidb 节点实现聚合 (这里会分为范围扫描,全表扫描等)
看执行计划优化就行了
哪种更符合你的场景,你就用哪种…
你的union不会是union了上万个select语句吧,感觉这样更慢
union的执行计划贴全些,SQL、表结构也贴下
就不算在TiDB,在传统数据库里面,用IN也比N个UNION(UNION ALL)速度快,IN只需要扫描某个索引一遍就行,而Union就不一定了
in不用把索引扫一遍吧,否则效率太低了
对于连续的数值,能用 between 就不要用 in 了
in后面是子查询吗?
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。