tidb版本:5.0.3
这两天集群出现其中一台kv负载很高得问题,重启该kv后会平缓一段时间,后续负载又上来了
请问要如何排查。以下是部分截图
3 个赞
可以看下 TiKV-Details -> Thread CPU 相关的监控
看下是不是有热点的问题:https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#tidb-热点问题处理
3 个赞

检查下服务器上IO情况(iops/吞吐),还有看下TIKV当前响应是不是比较慢
3 个赞
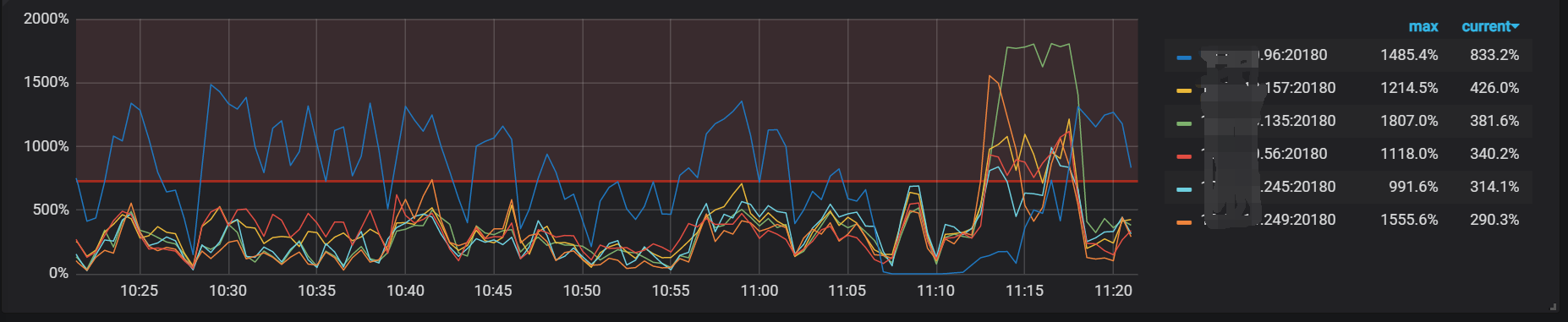
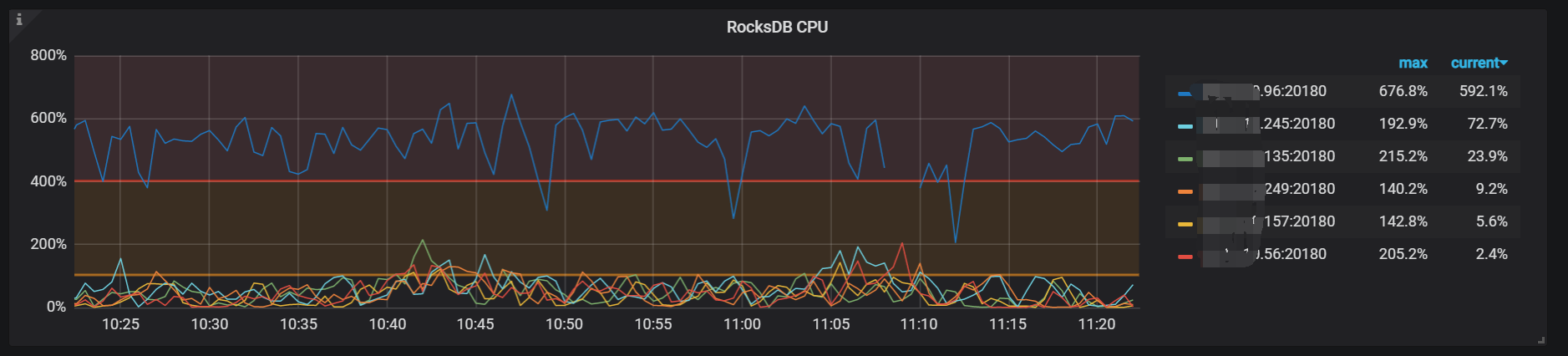
io情况比其他得节点多一点点。响应也比会慢点。
3 个赞
从热力图定位到region,看看region对应的sql的执行情况。。
2 个赞
查出来得语句 大部分执行时间都不长,,完全找不到方向。
3 个赞
这个cpu 高的tikv主机的负载如何? 所有tikv的配置都一样吗?
1 个赞
可以考虑增加一个TIKV节点,把慢的节点LEADER驱逐了:smiley:
1 个赞
负载很高, 其他得平均3-5 他能到25 ,。。 机器都是24*64得
1 个赞
所有tikv的配置都一样吗?之前碰到一个同学把其中一台的日志级别调成debug,其他的都是info,结果这个tikv负载很高,并且集群的整体吞吐量还上不去。
1 个赞
配置都一样,这是配置
tikv:
raftstore.raft-entry-max-size: 125829120
raftstore.sync-log: false
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: false
tikv_servers:
- host: 192.168.1.245
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/tidb-deploy/tikv-20160
data_dir: /data/tidb-data/tikv-20160
log_dir: /data/log/tikv-20160
arch: amd64
os: linux - host: 192.168.1.135
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/tidb-deploy/tikv-20160
data_dir: /data/tidb-data/tikv-20160
log_dir: /data/log/tikv-20160
arch: amd64
os: linux - host: 192.168.1.249
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/tidb-deploy/tikv-20160
data_dir: /data/tidb-data/tikv-20160
log_dir: /data/log/tikv-20160
arch: amd64
os: linux - host: 192.168.1.56
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/tidb-deploy/tikv-20160
data_dir: /data/tidb-data/tikv-20160
log_dir: /data/log/tikv-20160
arch: amd64
os: linux - host: 192.168.1.96
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/tidb-deploy/tikv-20160
data_dir: /data/tidb-data/tikv-20160
log_dir: /data/tidb-deploy/tikv-20160/log
arch: amd64
os: linux - host: 192.168.1.157
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /data/tidb-deploy/tikv-20160
data_dir: /data/tidb-data/tikv-20160
log_dir: /data/tidb-deploy/tikv-20160/log
arch: amd64
os: linux
1 个赞
这机器是物理机在idc, 不好加啊。。。。
1 个赞
直接在这个机器上加个新盘 把旧的TIKV 停止 避免因为IO影响到新的,我猜测你目前这个异常的TIKV节点的磁盘IO的吞吐应该很大
1 个赞
1、排查热点:
1)hot read/write/store 和 region topread/topwrite [limit]查看热点信息(表或者索引信息)
2)热力图
2、排除tikv主机差异:
1)tikv主机CPU、IO、网络、内存等
2)特别是主机io调度策略
3、排除tikv配置差异:
你这个cpu高,就重点查看tikv几个线程池的cpu使用情况
gRPC 线程池\Scheduler 线程池\Raftstore 线程池\StoreWriter 线程池\Apply 线程池\RocksDB 线程池\UnifyReadPool 线程池
具体查看 grafana的 tikv-details --》thread cpu 这块,然后根据情况再做分析。
1 个赞

那麻烦在贴下 rocksdb-kv rocksdb-raft这两个面板的metrics指标。也是在tikv-details下。
1 个赞
前提要排除掉有写热点。
1 个赞
写入得热力图

tidb-pro-TiKV-Details_2021-12-28T08_38_24.067Z.json (1.5 MB) tidb-pro-TiKV-Details_2021-12-28T08_36_57.157Z.json (1.7 MB)
1 个赞
麻烦再把disk-performence这个面板的json数据导出来,谢谢!
1 个赞