为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】 线上环境
【概述】使用tiup check命令查看集群状态,发现警告。
【背景】做过哪些操作
【现象】暂时对业务没什么影响。
【TiDB 版本】5.0.0
【附件】
执行命令:tiup cluster check tidb_cluster_name --cluster
警告信息:
![]()
Checking region status of the cluster tidb_sherlock…
Regions are not fully healthy: 18691 pending-peer
Please fix unhealthy regions before other operations.
4 个赞
store和region的监控图里面的信息咋样
4 个赞
Regions are not fully healthy
目前 每个 store 分别有多少 region ? 可以查下大概的分布以及大小
4 个赞
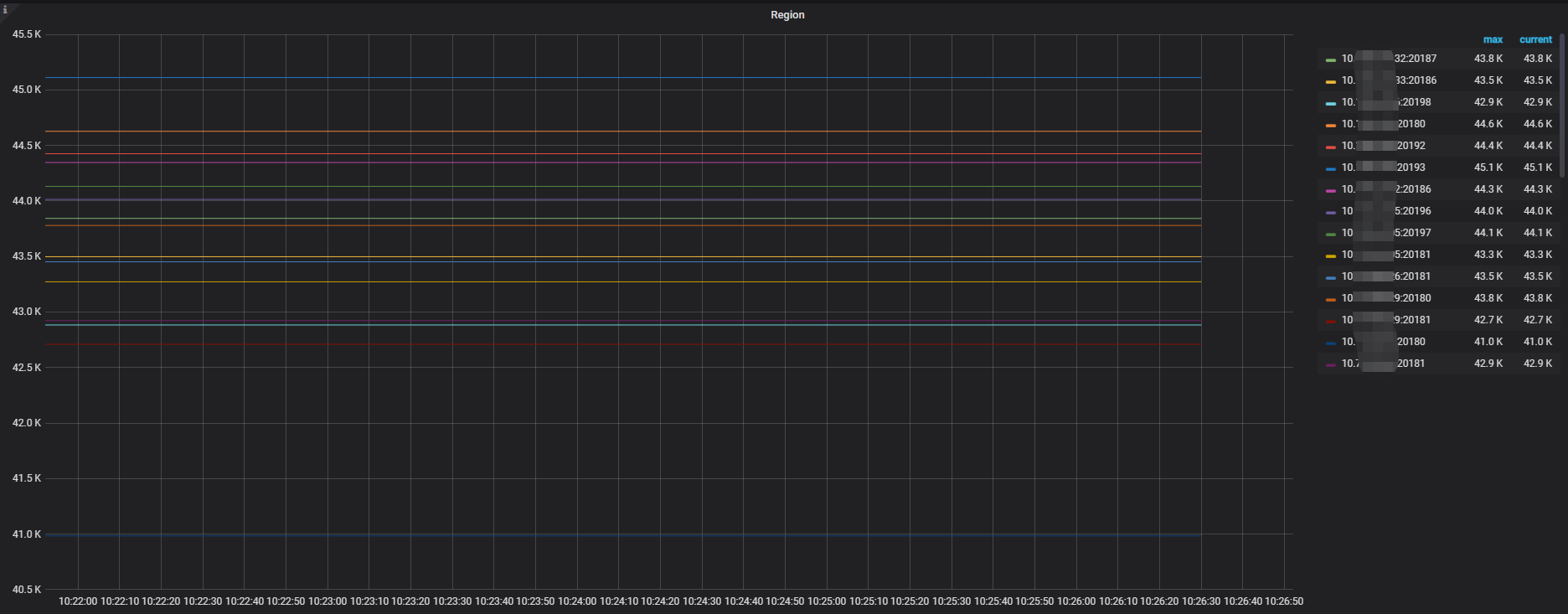
region 有点多了,控制在 2 - 3W 会比较好,或者开启 hibernate region
参考最佳实践
https://docs.pingcap.com/zh/tidb/v5.2/massive-regions-best-practices/#方法四开启-hibernate-region-功能
参考文档
https://docs.pingcap.com/zh/tidb/v5.2/tikv-configuration-file/#hibernate-regions
2 个赞
这个需要机器tikv数量再翻一倍,资源方面可能有点阻碍。
2 个赞
那就开启静默模式吧,多参考下哪个最佳实践,可以帮到你的
1 个赞
静默模式的开启,必须重新启动tikv节点吗?没有找到动态修改的方法。
1 个赞
要修改配置文件重启才行噢~
1 个赞
我利用tiup edit-config的方法改了这个参数,如下: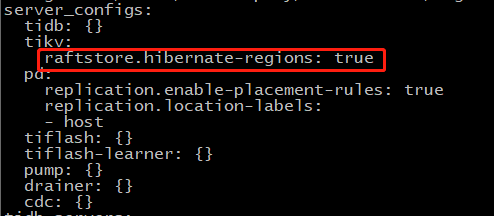
并且使用reload方法对集群的tikv进行了reload:tiup cluster reload tidb_cluster_name -R tikv
reload的过程中,pending-peer下降到了从18000左右下降到4000左右,但是reload完成之后似乎这个pending-peer的数量并没有下降,又反弹到18000左右了。
观察下先~
看看grafana 在调整后,重启的 tikv 节点 region 监控指标有什么变化
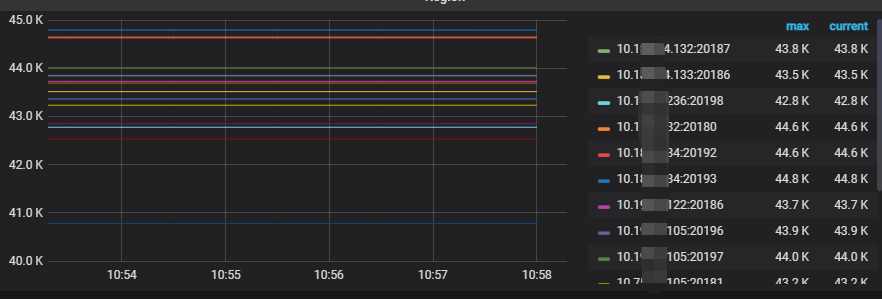
不是观察region的数量阿,你修改后的 tikv 节点,还有报哪个 状态异常的么?
Regions are not fully healthy: 18691 pending-peer
类似这样的
那个pending-peer的数量,还是保持在18444个。。。

就少了几百个 region 的 peer 么…
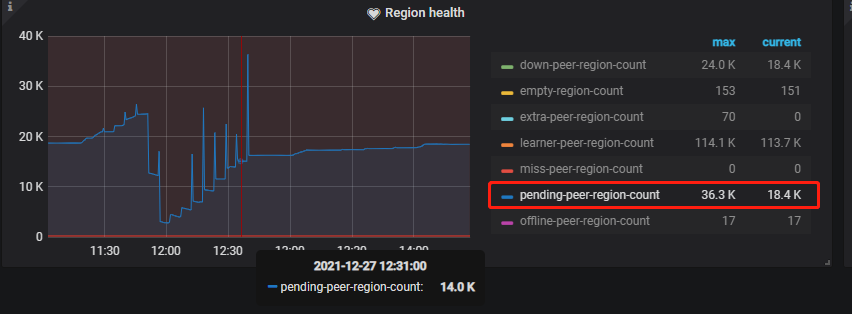
看着应该是某个TIKV掉
现在这个咋整啊,看着怪难受的。虽然业务访问暂时没啥报错。![]()