目前测试的瓶颈是网络,还是 PD?
有没有部署 prometheus 去收集这些测试的信息? 如果有的话,可以放出来
预期值,需要从并发量的量级(每秒多少并发请求),要充分的考虑网络带宽,客户端的处理能力,以及 tikv Raw 模式需要多少 节点来支持
一般 tikv 最佳划分是 2W 个region,每个 Region 差不多 96MB,最大 144MB,基本上就 一个节点 2T 的磁盘空间;
你需要自己估算下,我不清楚你的场景需求
目前测试的瓶颈是网络,还是 PD?
有没有部署 prometheus 去收集这些测试的信息? 如果有的话,可以放出来
预期值,需要从并发量的量级(每秒多少并发请求),要充分的考虑网络带宽,客户端的处理能力,以及 tikv Raw 模式需要多少 节点来支持
一般 tikv 最佳划分是 2W 个region,每个 Region 差不多 96MB,最大 144MB,基本上就 一个节点 2T 的磁盘空间;
你需要自己估算下,我不清楚你的场景需求
按照估算我们的盘的容量是足够,现在你需要哪一个监控数据我给你从面板上拿一下。并发的线程数是4000,均摊到三个节点的。现在我们也是结合日志和官方文档推测瓶颈应该是pd
有个案例,你们可以参考
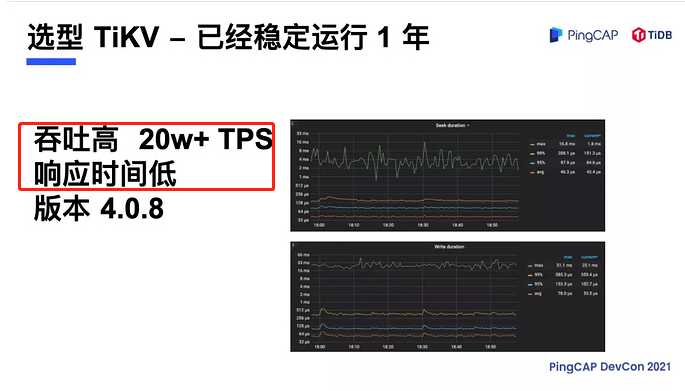
这里的关键问题:场景的预期到底是什么?
希望这个案例能给你们提示
我们也是直接往tikv写入的,现在是每次都能复现这个bug
给你的案例都上线了… 还是 4.0.8
现在的版本都5.3.x 了
然后你这边如果提供不了更多的信息,我也帮不了你,希望你能明白
你好你需要什么信息你可以直接回复我们给你提供,你给的案例我们也认真看了可是并没有解决我们的问题。他的案例应用场景我们这不一样啊我们写入数据到六亿就停机。具体的信息发了好几次给你你留意看了吗
出现 日志中无法访问 PD时,PD 的状态是什么? 是可用,还是不可用?
整个集群的资源占用和网络流量是否有异常?
你能自己把这些描述出来么? 需要来判断的问题点,或者 异常点
你好现在我们升级了版本目前是pd+tikv的配置现在写入到34亿左右的数据还是会到达pd的瓶颈
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。

