IndexScan_15 actrows=17566 , max_proc_keys: 275851.
5.0.3上测试了下这块统计没问题,你的这个可能得研发大佬看看了
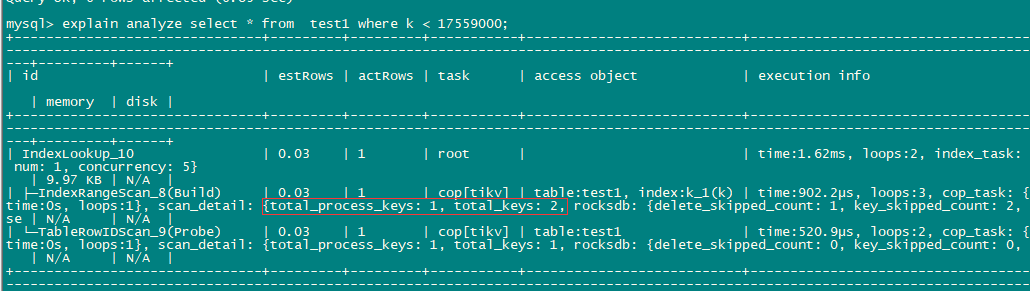
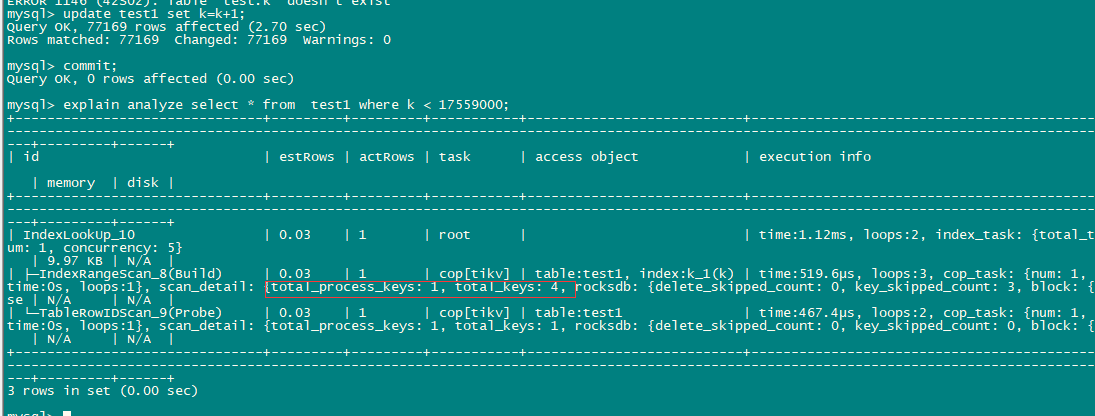
1 个赞
看执行计划没问题,咱们是疑问 为啥 process key 之类的多吗?(感觉有2个原因:1、像分布式,然后 limit 情况,本身会算一些。2、咱们的索引只用到了 第一个 key,本身又多了一些:可以尝试换个组合索引)
如果是想问,process key 是怎么算出来的,我也不是很确定,我问一下(可以看出我不是大佬了吧,每次我都心虚的难受)
话说集群版本是多少啊,优化器每个版本都有改进,不说版本,没法给答案
用户版本v4.0.10,问题是: index里符合条件的记录数约5000左右,而实际执行计划的processed keys有30w, 两者差异叫大
最近有点忙,把这个问题给忘记了, process key 多的原因,在上面已经回复了(如果是想要解决办法:1、开启 index merge 功能,原因是上面用到的索引,并不好 ,如果其他字段有索引,开启 index merge 功能会比较好一些。2、直接创建个适合的索引
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。