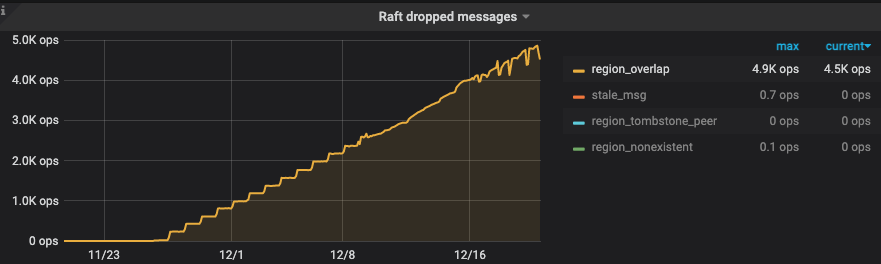
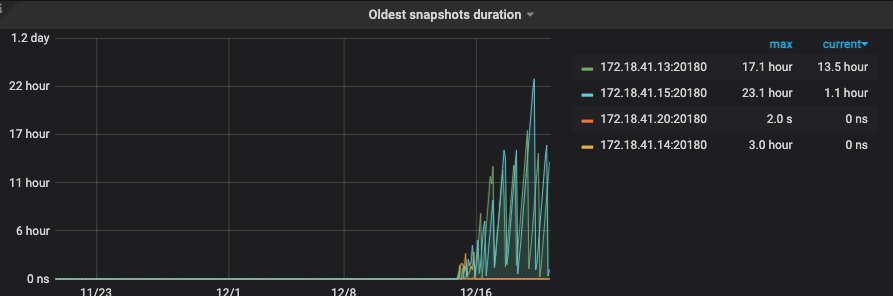
这有几千个,要一个一个操作也不现实吧》?
看起来是store 2导致的问题,如果不这么操作,那么可以增加一个节点,然后下线store 2节点,在加回集群。
这是什么原因导致的???
关键现在pending状态的region 还在增加。
pd-ctl store 发一下store的信息
看到了吗? 怎么样
不确定是否为已知bug,需要产研大佬看了,建议你升级至4.0.x最新版本尝试一下
那麻烦排查下,给个解决方案吧
之前有个问题导致 learner peer 一直 create 不出来 https://github.com/tikv/tikv/pull/8084 v4.0.14 修复
可以尝试 pd-ctl 手动 remove pending peer,如果可行,写个脚本批量 remove
现在问题是create出来的 都是pending状态 ,你这个是只解决当前的pending状态的region吧?
按你这样remove掉之后,后面新增的表或者新增的region在这个节点上 还是会pending状态 怎么办?
按照你这个操作 删除了一个pending状态的region,但是没有新 的region生成, 它本来有三个副本,现在只有两个了? 这个是为啥?
[2021/12/13 11:33:41.146 +08:00] [INFO] [operator_controller.go:424] [“add operator”] [region-id=1493854] [operator="“admin-remove-peer {rm peer: store [2]} (kind:region,admin, region:1493854(42338,5), createAt:2021-12-13 11:33:41.146367259 +0800 CST m=+10200117.003876679, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, steps:[remove peer on store 2])”"] [“additional info”=]
[2021/12/13 11:33:41.146 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“remove peer on store 2”] [source=create]
[2021/12/13 11:33:41.149 +08:00] [INFO] [cluster.go:551] [“region ConfVer changed”] [region-id=1493854] [detail=“Remove peer:{id:1493855 store_id:2 }”] [old-confver=5] [new-confver=6]
[2021/12/13 11:33:41.149 +08:00] [INFO] [operator_controller.go:537] [“operator finish”] [region-id=1493854] [takes=2.763583ms] [operator="“admin-remove-peer {rm peer: store [2]} (kind:region,admin, region:1493854(42338,5), createAt:2021-12-13 11:33:41.146367259 +0800 CST m=+10200117.003876679, startAt:2021-12-13 11:33:41.1464699 +0800 CST m=+10200117.003979322, currentStep:1, steps:[remove peer on store 2]) finished”"] [“additional info”=]
[2021/12/13 11:52:05.207 +08:00] [INFO] [operator_controller.go:424] [“add operator”] [region-id=1493854] [operator="“admin-add-peer {add peer: store [2]} (kind:region,admin, region:1493854(42338,6), createAt:2021-12-13 11:52:05.207891583 +0800 CST m=+10201221.065401001, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, steps:[add learner peer 1493922 on store 2, promote learner peer 1493922 on store 2 to voter])”"] [“additional info”=]
[2021/12/13 11:52:05.207 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=create]
[2021/12/13 11:52:05.211 +08:00] [INFO] [cluster.go:551] [“region ConfVer changed”] [region-id=1493854] [detail=“Add peer:{id:1493922 store_id:2 is_learner:true }”] [old-confver=6] [new-confver=7]
[2021/12/13 11:52:05.211 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=heartbeat]
…
[2021/12/13 12:01:40.741 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=“active push”]
[2021/12/13 12:01:45.741 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=“active push”]
[2021/12/13 12:01:50.742 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=“active push”]
[2021/12/13 12:01:56.242 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=“active push”]
[2021/12/13 12:02:01.242 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“add learner peer 1493922 on store 2”] [source=“active push”]
[2021/12/13 12:02:05.741 +08:00] [INFO] [operator_controller.go:560] [“operator timeout”] [region-id=1493854] [takes=10m0.533990005s] [operator="“admin-add-peer {add peer: store [2]} (kind:region,admin, region:1493854(42338,6), createAt:2021-12-13 11:52:05.207891583 +0800 CST m=+10201221.065401001, startAt:2021-12-13 11:52:05.207976333 +0800 CST m=+10201221.065485759, currentStep:0, steps:[add learner peer 1493922 on store 2, promote learner peer 1493922 on store 2 to voter]) timeout”"]
[2021/12/13 12:02:27.648 +08:00] [INFO] [operator_controller.go:424] [“add operator”] [region-id=1493854] [operator="“fix-peer-role {promote peer: store [2]} (kind:unknown, region:1493854(42338,7), createAt:2021-12-13 12:02:27.648547738 +0800 CST m=+10201843.506057160, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, steps:[promote learner peer 1493922 on store 2 to voter])”"] [“additional info”=]
[2021/12/13 12:02:27.648 +08:00] [INFO] [operator_controller.go:620] [“send schedule command”] [region-id=1493854] [step=“promote learner peer 1493922 on store 2 to voter”] [source=create]
[2021/12/13 12:02:27.651 +08:00] [INFO] [cluster.go:551] [“region ConfVer changed”] [region-id=1493854] [detail=“Remove peer:{id:1493922 store_id:2 is_learner:true },Add peer:{id:1493922 store_id:2 }”] [old-confver=7] [new-confver=8]
[2021/12/13 12:02:27.651 +08:00] [INFO] [operator_controller.go:537] [“operator finish”] [region-id=1493854] [takes=2.745052ms] [operator="“fix-peer-role {promote peer: store [2]} (kind:unknown, region:1493854(42338,7), createAt:2021-12-13 12:02:27.648547738 +0800 CST m=+10201843.506057160, startAt:2021-12-13 12:02:27.648645817 +0800 CST m=+10201843.506155240, currentStep:1, steps:[promote learner peer 1493922 on store 2 to voter]) finished”"] [“additional info”=]
我把有问题的那个tikv节点上的一个pending状态的副本按照你们提供的步骤,给他删掉,删掉之后 它不会自动增加副本,然后 我手工添加了一个,添加完成之后 它先是learner ,过了十分钟之后,又变成了pending状态。 上面是pd的日志
删除和添加副本的脚本
tiup ctl pd -u http://ip:2379 operator add remove-peer 1493854 2
tiup ctl pd -u http://ip:2379 operator add add-peer 1493854 2
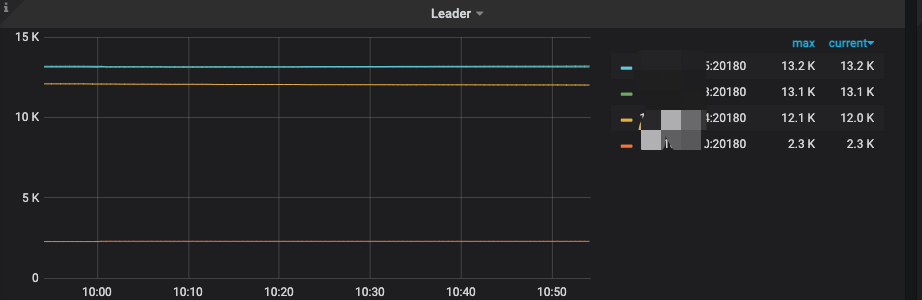
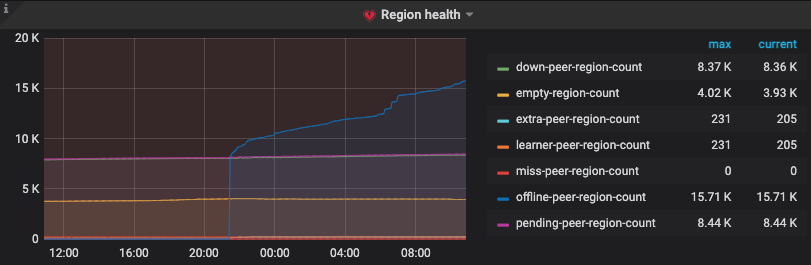
是否尝试升级?
现在有几个排查方向或者问题需要确认
1) pd、tikv组件是怎么部署的?独立还是混合?麻烦发下部署的拓扑结构;
2) 看看对应tikv主机的disk io latency情况;
3) 看看tidb-server中有没有对应报错异常;
4) 登录pd-ctl,查询config show 看看
5)重点看下 raft log相关的指标,在TiKV-Details下可以看
6) pending-peer-region-count 过多,本质上是那个region peer的raft log落后太多而被计数的region个数
可能原因:
- 目标region peer所在的tikv实例的主机负载(IO 网络 CPU等)太高导致
- raft log在广播的时候有没有什么大小限制或者latch竞争
- raftstore CPU 指标如何
另外,各个节点的主机时钟是否同步?
看日志,第一次出现问题的时候,5个PD节点同时挂掉?或者这个tikv节点跟PD集群失联
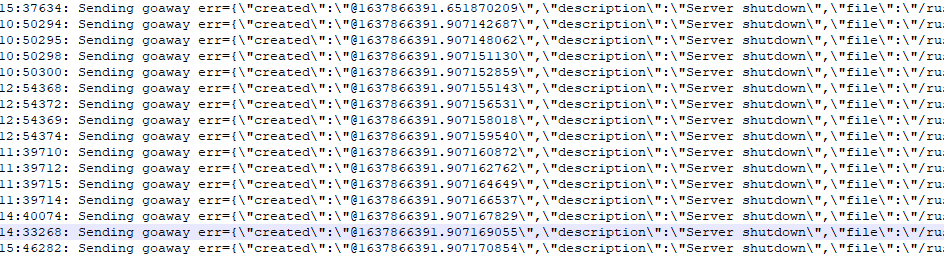
然后就开始连续报连接PD的错误:
[2021/11/26 02:53:12.398 +08:00] [ERROR] [kv.rs:612] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
[2021/11/26 02:53:13.089 +08:00] [INFO] [mod.rs:132] ["Storage stopped."]
[2021/11/26 02:53:13.101 +08:00] [INFO] [node.rs:379] ["stop raft store thread"] [store_id=3]
[2021/11/26 02:53:13.101 +08:00] [INFO] [mod.rs:375] ["stoping worker"] [worker=split-check]
[2021/11/26 02:53:13.101 +08:00] [INFO] [mod.rs:375] ["stoping worker"] [worker=snapshot-worker]
[2021/11/26 02:53:13.108 +08:00] [INFO] [future.rs:175] ["stoping worker"] [worker=pd-worker]
[2021/11/26 02:53:13.108 +08:00] [INFO] [mod.rs:375] ["stoping worker"] [worker=consistency-check]
[2021/11/26 02:53:13.114 +08:00] [INFO] [mod.rs:375] ["stoping worker"] [worker=cleanup-worker]
[2021/11/26 02:53:13.114 +08:00] [INFO] [mod.rs:375] ["stoping worker"] [worker=raft-gc-worker]
[2021/11/26 02:53:13.114 +08:00] [INFO] [batch.rs:411] ["shutdown batch system apply"]
[2021/11/26 02:53:13.114 +08:00] [INFO] [router.rs:250] ["broadcasting shutdown"]
[2021/11/26 02:53:13.127 +08:00] [ERROR] [peer.rs:2848] ["failed to notify pd"] [err="channel has been closed"] [peer_id=1414024] [region_id=1414021]
[2021/11/26 02:53:13.127 +08:00] [ERROR] [peer.rs:2848] ["failed to notify pd"] [err="channel has been closed"] [peer_id=1214372] [region_id=1214369]
您好 同步的我看了下
这个时间点是在做重启tikv操作。 导数据把节点夯住了 然后重启了其中两台tikv节点
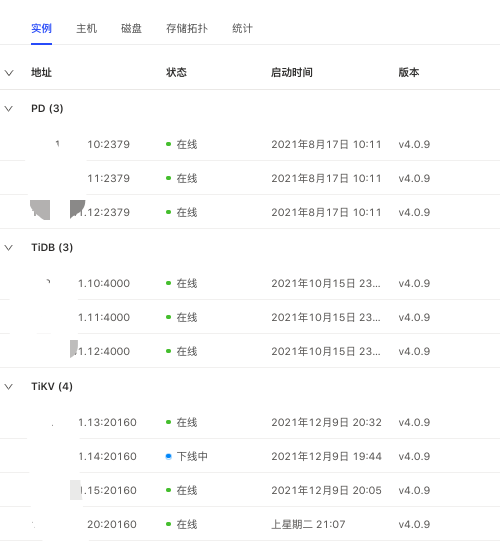
这个是集群信息 目前新扩容了一台20tikv节点 然后对14节点tikv执行了下线操作 一直在下线中好几天了 看新扩容的节点一直有报错 region peer所在的tikv实例的主机负载(IO 网络 CPU等)都不高的
[2021/12/20 10:49:23.077 +08:00] [WARN] [peer.rs:3441] [“leader missing longer than max_leader_missing_duration. To check with pd and other peers whether it’s still valid”] [expect=2h] [peer_id=1580425] [region_id=1358925]
[2021/12/20 10:50:50.054 +08:00] [WARN] [peer.rs:3441] [“leader missing longer than max_leader_missing_duration. To check with pd and other peers whether it’s still valid”] [expect=2h] [peer_id=1580278] [region_id=107408]
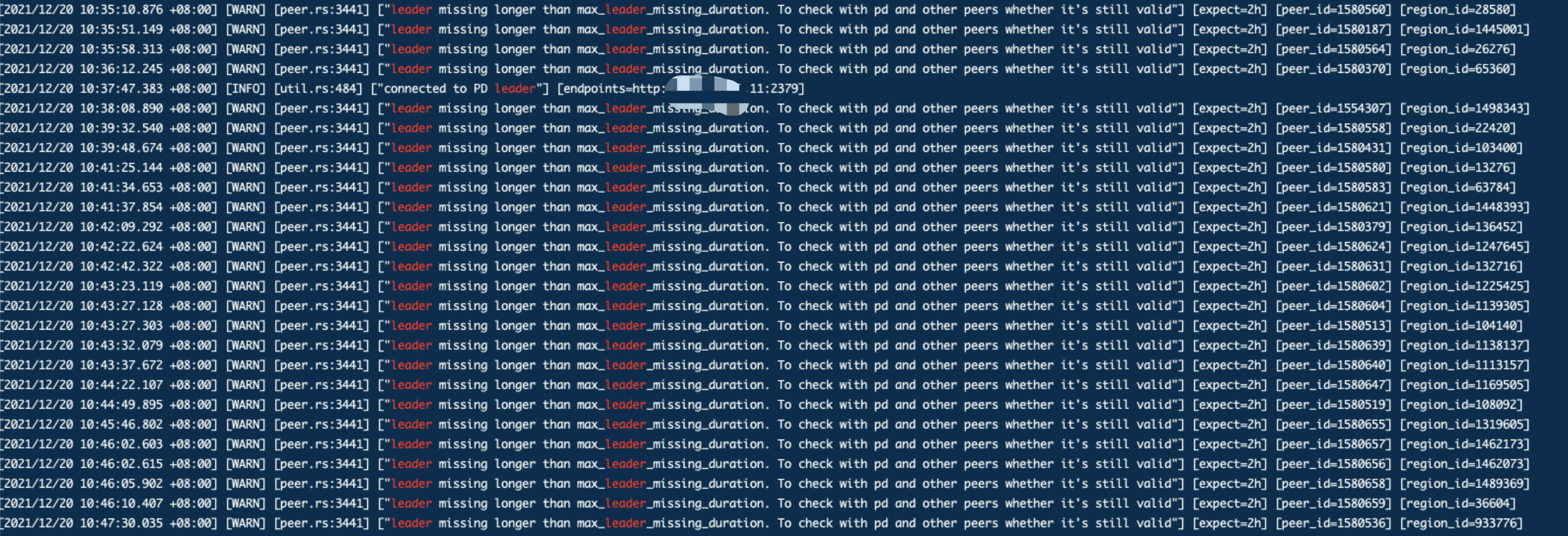
» config show
{
“replication”: {
“enable-placement-rules”: “true”,
“location-labels”: “”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“enable-cross-table-merge”: “false”,
“enable-debug-metrics”: “false”,
“enable-location-replacement”: “true”,
“enable-make-up-replica”: “true”,
“enable-one-way-merge”: “false”,
“enable-remove-down-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“high-space-ratio”: 0.7,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 8,
“leader-schedule-limit”: 6,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 64,
“max-snapshot-count”: 12,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 4096,
“replica-schedule-limit”: 64,
“scheduler-max-waiting-operator”: 5,
“split-merge-interval”: “1h0m0s”,
“store-limit-mode”: “manual”,
“tolerant-size-ratio”: 0
}
}
tidb日志看起来没有啥报错 和之前的日志输出差不多
[2021/12/20 11:28:44.376 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:3.111516069s txnStartTS:429908536604229633 region_id:1234729 store_addr:1
72.18.41.15:20160 kv_process_ms:727 scan_total_write:58 scan_processed_write:48 scan_total_data:12 scan_processed_data:12 scan_total_lock:11 scan_processed_lock:0 kv_
wait_ms:2372”] [conn=6742574]
[2021/12/20 11:28:49.798 +08:00] [WARN] [session.go:1222] [“compile SQL failed”] [conn=6741358] [error=“[planner:1046]No database selected”] [SQL=“SHOW FULL TABLES FR
OM LIKE 'BONECPKEEPALIVE'"] [2021/12/20 11:28:49.799 +08:00] [INFO] [conn.go:793] ["command dispatched failed"] [conn=6741358] [connInfo="id:6741358, addr:172.18.22.7:33386 status:10, collation: utf8_general_ci, user:bi_system"] [command=Query] [status="inTxn:0, autocommit:1"] [sql="SHOW FULL TABLES FROM LIKE ‘BONECPKEEPALIVE’”] [txn_mode=PESSIMISTIC] [err
=“[planner:1046]No database selected”]
[2021/12/20 11:28:49.853 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:337.029412ms txnStartTS:429908539330527235 region_id:1234689 store_addr:1
72.18.41.15:20160 kv_process_ms:327 scan_total_write:40 scan_processed_write:32 scan_total_data:6 scan_processed_data:6 scan_total_lock:12 scan_processed_lock:0”] [co
nn=6742545]
[2021/12/20 11:28:49.864 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:346.433879ms txnStartTS:429908539330527235 region_id:1234713 store_addr:1
72.18.41.13:20160 kv_process_ms:346 scan_total_write:38 scan_processed_write:31 scan_total_data:5 scan_processed_data:5 scan_total_lock:11 scan_processed_lock:0”] [co
nn=6742545]
[2021/12/20 11:28:49.879 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:362.855584ms txnStartTS:429908539330527235 region_id:1234701 store_addr:1
72.18.41.14:20160 kv_process_ms:363 scan_total_write:48 scan_processed_write:37 scan_total_data:5 scan_processed_data:5 scan_total_lock:13 scan_processed_lock:0”] [co
nn=6742545]
[2021/12/20 11:28:49.943 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:427.093611ms txnStartTS:429908539330527235 region_id:1234685 store_addr:1
72.18.41.13:20160 kv_process_ms:415 scan_total_write:37 scan_processed_write:29 scan_total_data:4 scan_processed_data:4 scan_total_lock:10 scan_processed_lock:0”] [co
nn=6742545]
[2021/12/20 11:28:49.981 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:463.90654ms txnStartTS:429908539330527235 region_id:1234717 store_addr:17
2.18.41.14:20160 kv_process_ms:454 scan_total_write:42 scan_processed_write:34 scan_total_data:6 scan_processed_data:6 scan_total_lock:11 scan_processed_lock:0”] [con
n=6742545]
[2021/12/20 11:28:50.049 +08:00] [INFO] [coprocessor.go:1034] [“[TIME_COP_PROCESS] resp_time:385.735783ms txnStartTS:429908539330527235 region_id:1234729 store_addr:1
72.18.41.15:20160 kv_process_ms:385 scan_total_write:42 scan_processed_write:35 scan_total_data:3 scan_processed_data:3 scan_total_lock:11 scan_processed_lock:0”] [co
nn=6742545]
都是这种的