halleyshx
(halleyshx)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
通过k8s docker部署的集群
TiKV
Release Version: 5.1.1
Edition: Community
Git Commit Hash: 4705d7c6e9c42d129d3309e05911ec6b08a25a38
Git Commit Branch: heads/refs/tags/v5.1.1
UTC Build Time: 2021-07-28 10:59:26
Rust Version: rustc 1.53.0-nightly (16bf626a3 2021-04-14)
Enable Features: jemalloc mem-profiling portable sse protobuf-codec test-engines-rocksdb cloud-aws cloud-gcp
Profile: dist_release
【概述】 场景 + 问题概述
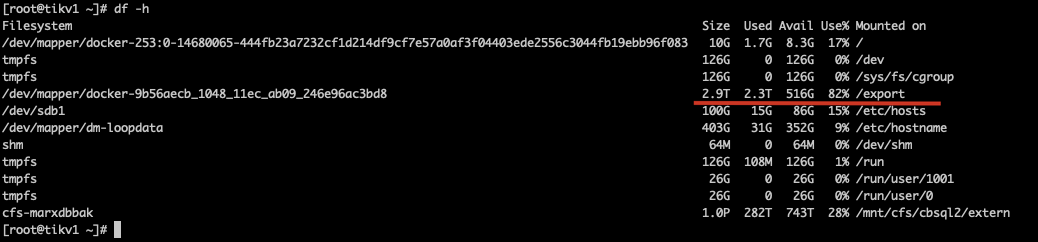
备份集群:32个tikv节点,单点df -h,2.3T数据 2.9T盘使用率82%
恢复集群:58个tikv节点,单点df -h, 2.1T数据
最开始建同规模32个节点集群进行恢复,磁盘2.9T 100%写满 恢复进度89%
重做集群,扩增25个节点到58个节点后,进行恢复数据,每个节点恢复了2.1T数据
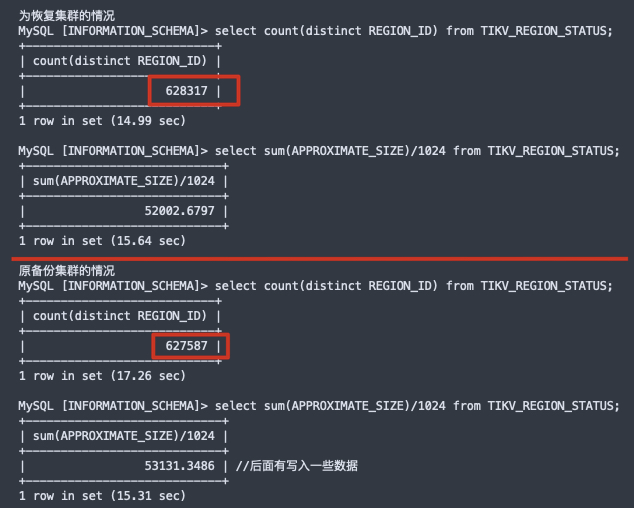
原集群32个点,每个节点2.3T 磁盘总占用73.6T (几天没有数据写入,数据静置)
恢复到58个节点,每个节点2.1T 总占用 121.8T (恢复完成后1h和9H一样的磁盘占用,以为会进行合并后缩小)
恢复后磁盘与原集群磁盘使用占比 1.65:1
【备份和数据迁移策略逻辑】
集群全量备份 数据全量恢复到另一个集群
【背景】 做过哪些操作
无
【现象】 业务和数据库现象
恢复后磁盘与原集群磁盘使用占比 1.65:1
【问题】 当前遇到的问题
数据无法恢复到同等规模集群中,并且比原来的磁盘占用增加了0.65倍
【业务影响】
导致某些集群需要恢复时无法同规模恢复,资源有限的情况下,影响集群恢复与业务提供
【TiDB 版本】
v5.1.1
【附件】
- 相关日志、配置文件、Grafana 监控(https://metricstool.pingcap.com/)
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
- TiDB-Overview 监控
- 对应模块的 Grafana 监控(如有 BR、TiDB-binlog、TiCDC 等)
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
听风吹雨
(听风吹雨)
2
1、请问你存储的备份文件是外部存储吗?你说的空间是否包含这部分的数据呢?
2、可以查看监控,对比两个集群占用空间大小和Region的个数和大小。
1 个赞
是否采用外部存储,恢复时需要每个节点先同步其余节点备份文件
1 个赞
halleyshx
(halleyshx)
4
1、我的备份文件存储在共享盘中/mnt/cfs/cbsql2/extern, 每个节点都挂载了这块儿盘,进行的数据恢复,恢复过程中同时读这块儿盘,实际tikv每个节点的数据目录在/export下,现象是恢复后所有节点的/export盘占用是原备份集群的磁盘占用的1.65倍,这块儿占用是不包括共享盘的
2、请问所说的这些监控指标项从哪里看呢
halleyshx
(halleyshx)
5
每个节点挂载的共享存储,用共享存储恢复,会自动copy相关内容到本地节点再恢复吗? 我理解应该都是直接通过共享存储读取进行恢复吧
halleyshx
(halleyshx)
6
我尝试从数据库中查询了一下两个集群的region情况,发现相差不大,排除由于region大量变多而导致的磁盘占用较之前增加0.65倍
luancheng
(Luancheng)
7
这个情况多数是因为备份时集群的数据压缩比率,和恢复时的集群默认不一致导致的,只要恢复的 checksum 阶段顺利通过,可以忽略这个问题,不影响正常使用。
luancheng
(Luancheng)
8
另外,在5.2以后的版本中,默认采用zstd的方式生成恢复数据,通过这个方式缓解恢复后数据比备份时大的问题,具体实现是这个pr。https://github.com/tikv/tikv/pull/10577
halleyshx
(halleyshx)
9
感谢您的回答,我有一个疑问,就是我两个集群都是按tidb的默认参数启动的,compression-per-level = [“no”, “no”, “lz4”, “lz4”, “lz4”, “zstd”, “zstd”] 两个集群都是一样的,正常我认为恢复出来比率都是这个 占用的磁盘空间应该不会不一样; 您的意思是说 原备份集群可能2-6层的数据占的比较多,恢复出来的新集群,可能0-4层数据占用比较多,而5-6层占用比较少,导致展现出来的数据磁盘空间占用大小不一样吗?
首先要读取到kv节点,然后编排成sst文件,然后再将sst文件ingest到TiKV
halleyshx
(halleyshx)
11
您的意思是读取到kv节点后,编排成的sst文件,在恢复完成之后所占用的额外空间?
halleyshx
(halleyshx)
13
感谢,我看了下,还是没有明确看出是哪里导致恢复集群比原集群多占用了将近一半的磁盘空间,唯一有这样一句话"所以恢复的数据量=备份数据量 * 副本数",但这个是在说明恢复的数据量和备份的数据文件大小的关系,是与副本多少相关,而不是集群维度的数据占用量的对比。
听风吹雨
(听风吹雨)
14
逻辑是:备份出来的SST文件在还原恢复的时候默认压缩算法和级别跟备份时候不一致。这个可以更新到v5.2就没有这个问题了。
halleyshx
(halleyshx)
15
这可以认为是在恢复的时候把集群的默认压缩级别给更改了吗?楼上luancheng也提到了这个pr; 我所理解的是数据在集群上展现的大小情况,是跟集群中compression-per-level配置有直接的关系的,如果这两个集群的compression-per-level都是按照默认配置,我觉得对于同一份数据来说,即使备份压缩,再经过恢复解压缩等,数据到这个集群中,都会按照集群的compression-per-level配置的压缩情况来展现数据大小,也就是应该两个集群的磁盘空间占用相仿。除非恢复过程中目标集群的compression-per-level被修改成非默认了,导致数据在这个集群中适配了不同的压缩方式,进而展现出不同的磁盘大小占用。不知道我这么理解的有什么问题没?
system
(system)
关闭
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。