为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】 场景 + 问题概述
今天上午10点到12点我们的tidb集群出现问题,现象是tidb节点cpu与内存跑满,业务上没有做代码发布,访问量与之前持平。下面是一些监控图
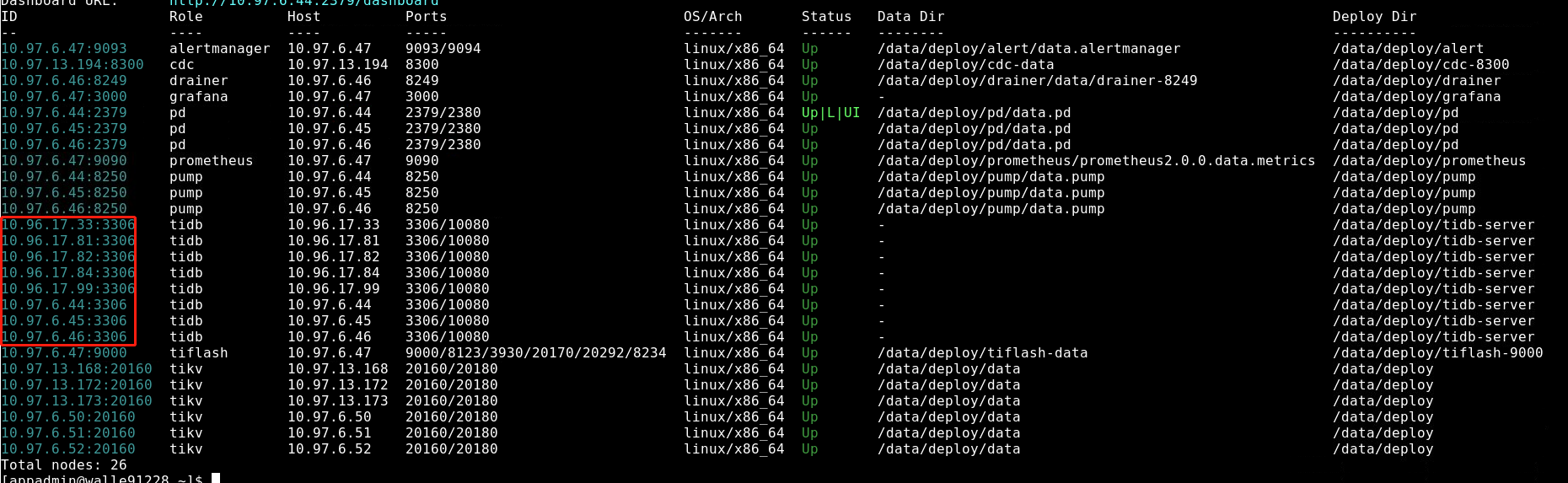
tidb集群情况如下图,其中17.33与17.99是我们在12点后新加的节点,6.44,6.45,6.46三个节点没有用到,我们前端有f5,负载到了17.81,17.82,17.84三台了,这三台cpu是16核,内存是64G
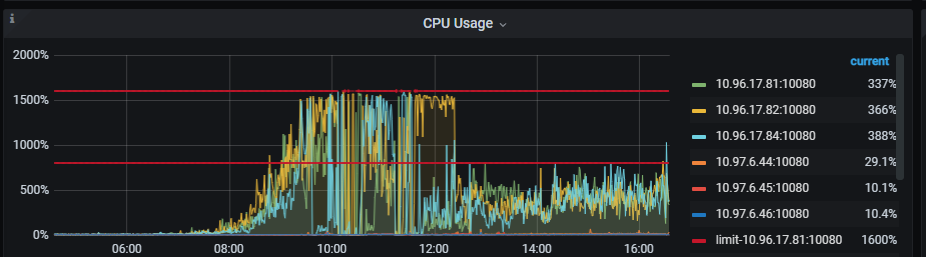
出现问题时段内17.81,17.82,17.84三台的cpu与内存情况如下:

三台磁盘情况如下:


下面是tikv节点cpu、内存使用情况,我们tikv是8核cpu,32G内存

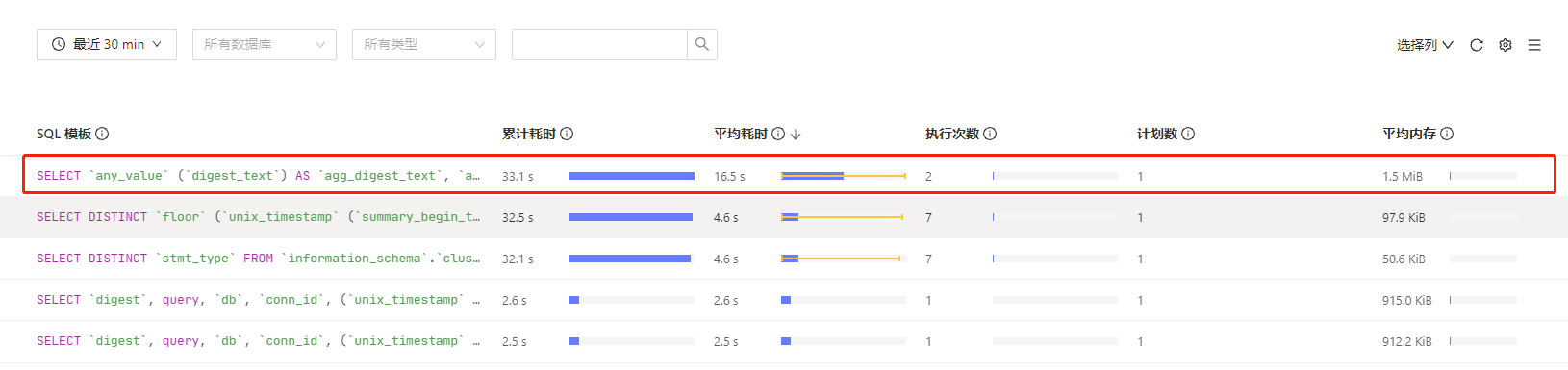
dashboard中出现了系统sql慢的情况,如下:
在12:30我们重新reload了集群,reload过程如下:
tiup cluster reload servicecloud_oltp -R tikv
tiup cluster reload servicecloud_oltp -R pd
tiup cluster reload servicecloud_oltp -R tidb
然后扩容了两个tidb节点,但是扩容后的tidb节点在grafana中看不到
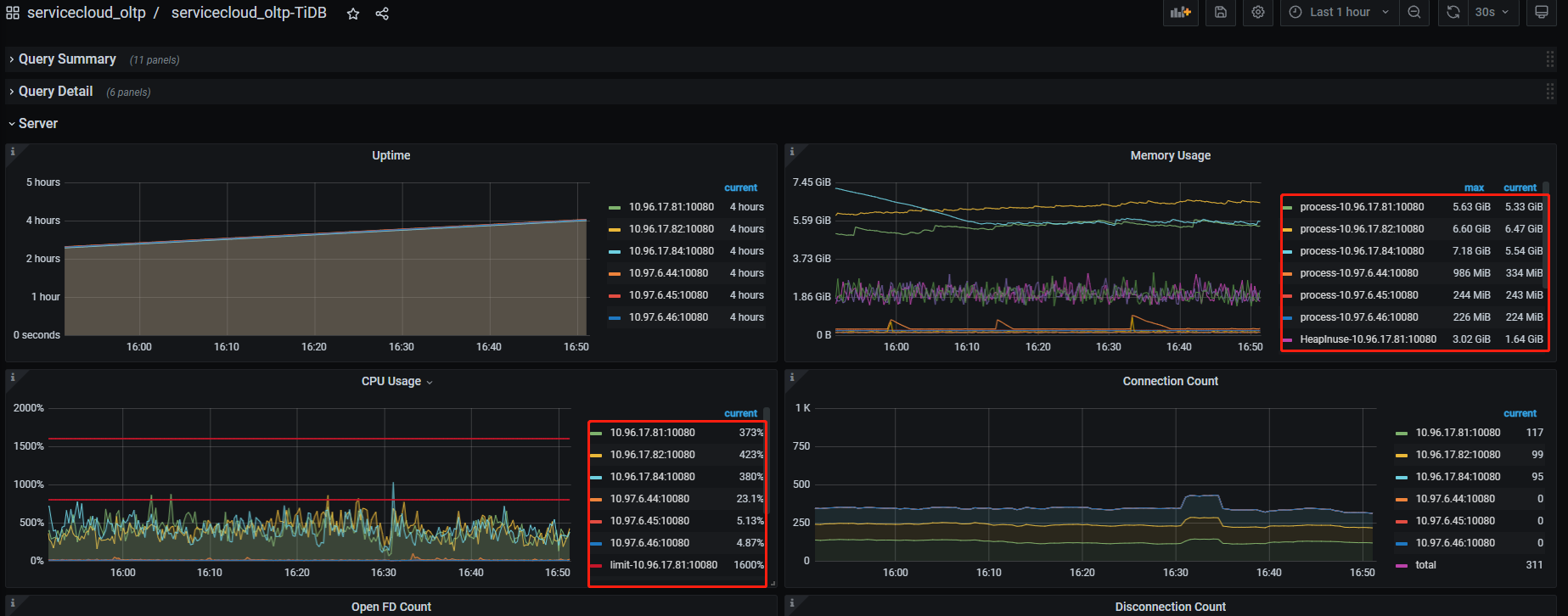
然后问题就解决了,很奇怪,
请帮忙看下,或是提供一下相关排查方法与思路,谢谢!
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
v5.1.1
【应用软件及版本】
【附件】 相关日志及配置信息
需要什么日志,我这可以提供。
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。