集群节点频繁的告警:err_not_leader,看日志过程,主要是一个region 分裂一次后,新分的这个REGION 有一个版本号等信息,这个新的region又继续分裂一次了,最终导致err_not_leader问题,变化过程 这个store的peer也发生了变化,
2 个赞
过一会儿不就行了吗?tidb节点会缓存region的路由信息,如果region分裂或者迁移,tidb去tikv查的时候,tikv会返回not leader。如果不是频繁的迁移或分裂,过一会儿不就又缓存了吗?如果总是出现这个的话,pd那里看下,是不是很多迁移、分裂的?可以控制下。
1 个赞
这个直接导致9005 服务异常了…你说得控制是哪个?调整region大小?
1 个赞
这种磁盘打 消耗IO 非常大 ,一次异常能打30G得日志
1 个赞
这个应该是region replicate的时候出现问题
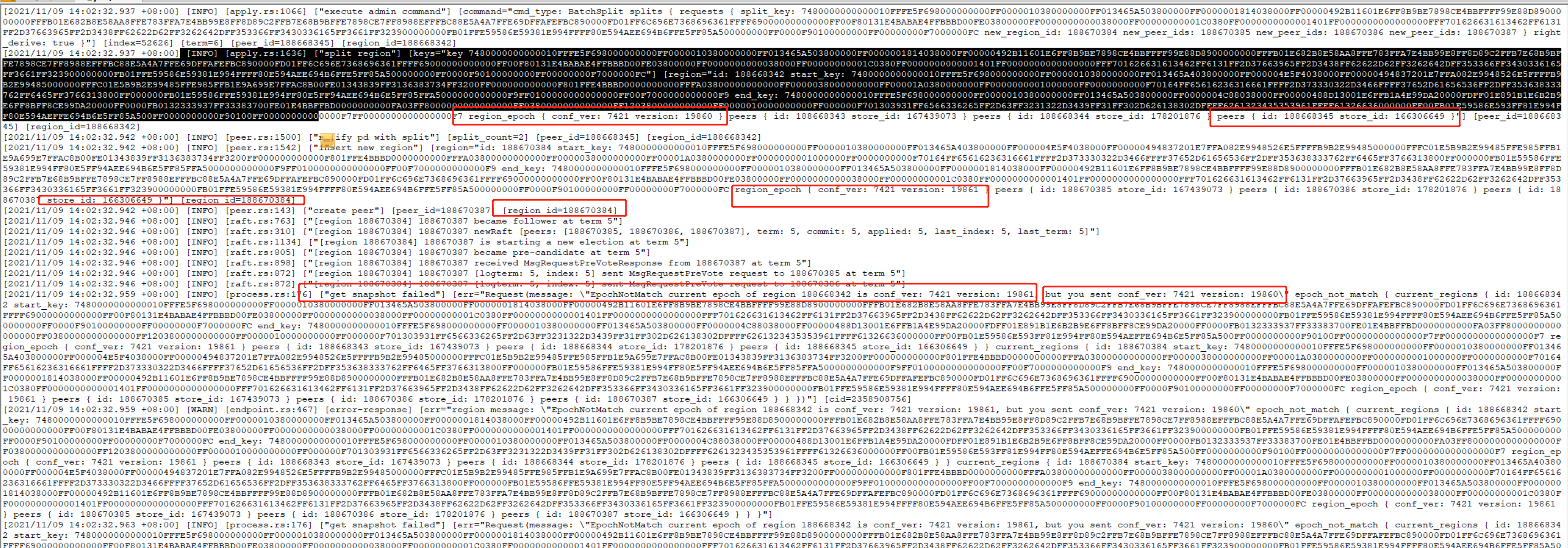
get snapshot failed
![]()
需要的version是19861,但是实际是19860,那就是region 在split(也可能是merge,但这里应该是)后的version信息没有更新导致的,怀疑是负载太高
另外你的集群是什么版本?
麻烦发下集群的负载信息和主机的负载信息。
谢谢!
1 个赞



14点之前 有做过什么操作吗?
1 个赞

怀疑是一台tikv打爆,或者这个tikv的负载太高,hbase tidb类似的这种集群,如果一个节点有问题,会拖慢整个集群,甚至可能把集群的监控状况搞出问题,这种情况下,情愿有问题的节点直接down 不要再被拉起来,集群还很可能正常运行下去。
1 个赞
你说得这个问题 确实存在,之前用对服务器其中得一个未使用得盘用dd压测,被压测得盘到极限了,直接影响到这台服务器上tikv,目前情况 都是直接关闭这个节点,过一会再拉起得,然后这个region group 跑到其他节点err_not_leader,再恢复节点 差不多就好了 ,,基本每次恢复都要好几分钟分,看日志 是一个是一个region发生了2次分裂后引起得问题,第一次分裂后得KEY 有100W多,那可以调整 “max-merge-region-keys” 这个?目前这个merge-schedule-limit是为0
1 个赞
merge-schedule-limit:0 表示关闭merge
登录pd-ctl,执行config show 看看
1 个赞
pd-ctl -i
config show
config set xxxx
把leader-schedule 限制成0,就不会来回切leader 了。
1 个赞
试过了 没用的
1 个赞
是还来回切leader?
我也遇到过类似的问题,不过那时候,在升级完集群之后就没出现了
你那升级到什么版本了,目前看根据我这业务读写特点,很难根治这个问题,还有就是region写入数据分片使用range分片,一个批次写入tidb_rowid依然是连续的,不管在怎么处理,也存在问题的
你的版本有点低,估计只能从调度的几个limit 参数限制了,另外,可以考虑一下 shard_row_id_bits/pre_split_regions 参数
那就是导入数据的时候,形成热点问题
都有这些参数的,,,数据是range分区,参数能够起到一定的缓解,但不能彻底解决的,,
嗯,所以比较麻烦,调整了REGION大小 能过缓解一点点问题