我按照官网的操作步骤,扩容成功,下面是配置文件inventory.ini
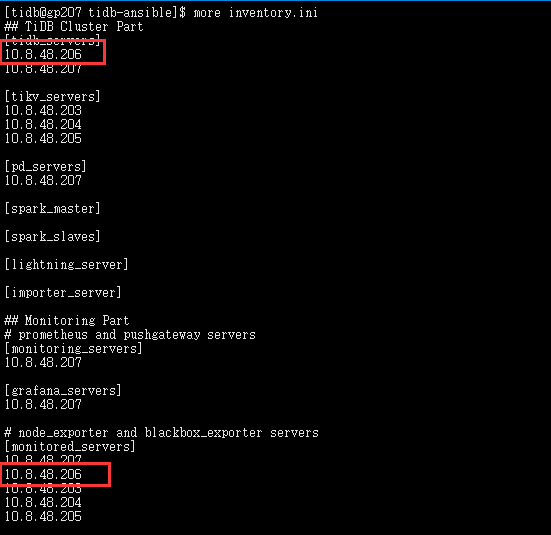
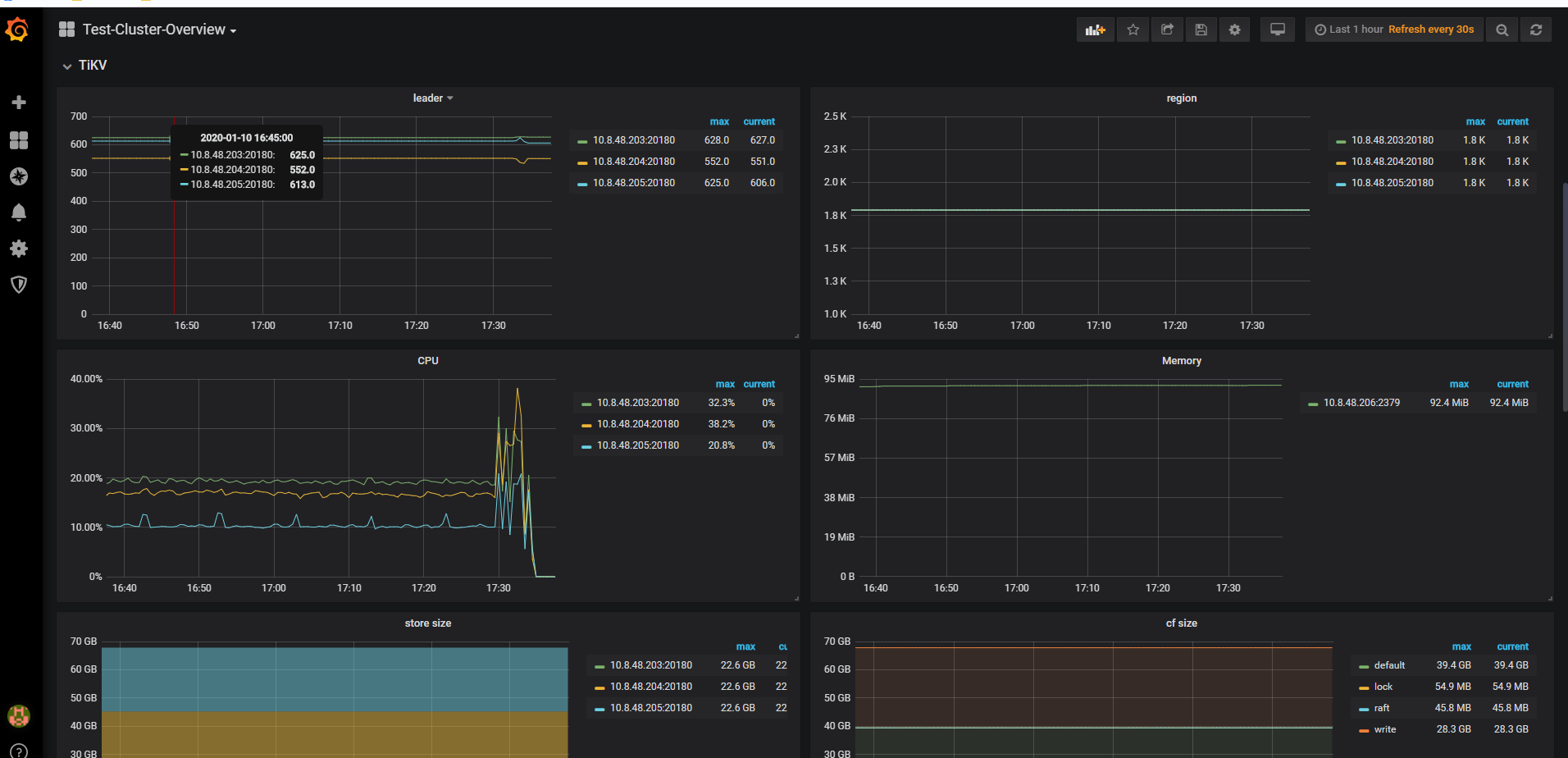
但是我在grafana的监控上面,并没有看到新增的tidb节点206呢
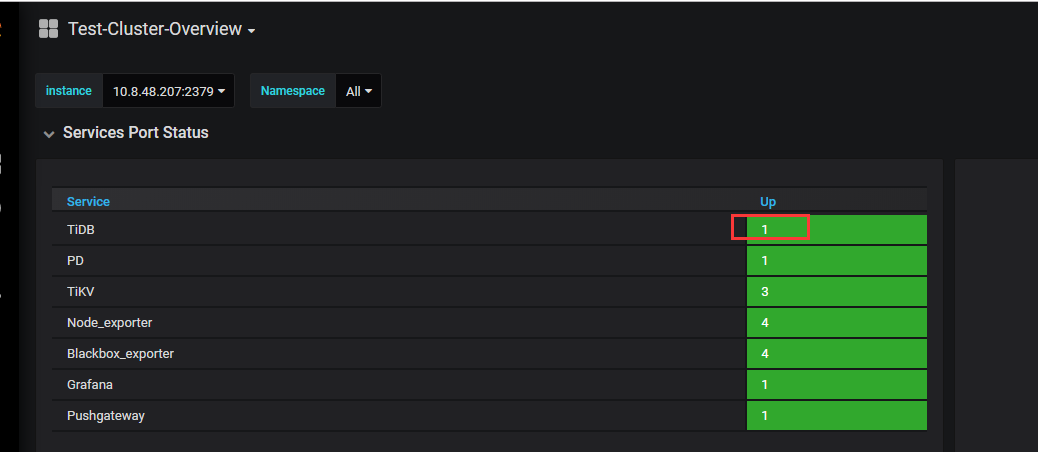
请问这是什么原因
现在刷新grafana,能看到新节点了,应该是扩容后,数据采集需要一段时间
这是没有更新 prometheus 监控吧,麻烦通过 rolling_update_morinited.yml 滚动一下 prometheus ,具体操作见官方文档。
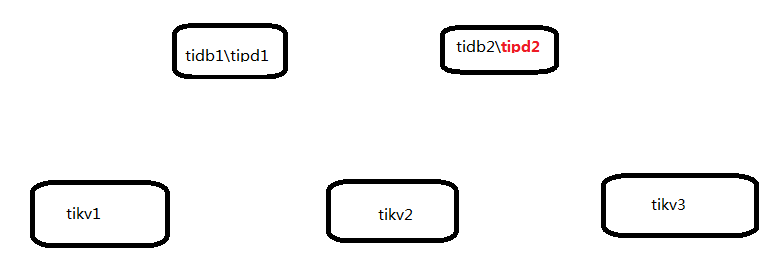
你好,我是测试环境,目前的tidb架构如下
红色tipd2是本次扩容的节点。
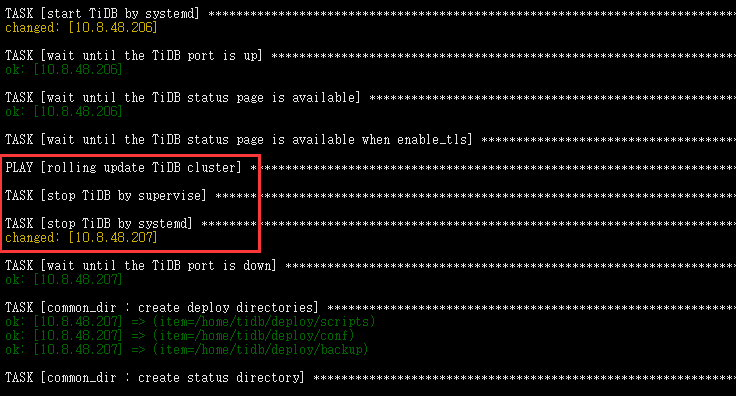
在扩容升级过程中,发现tidb对外提供服务会出现闪断的情况,执行命令为
ansible-playbook rolling_update.yml
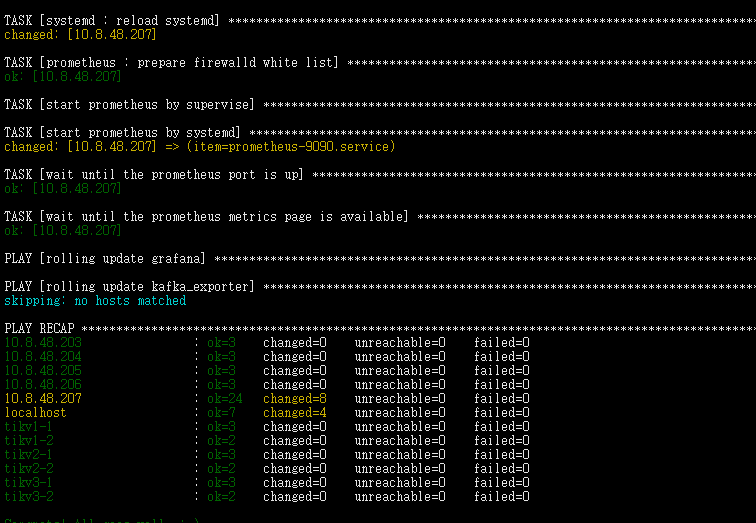
对外停止服务时的升级日志大概如下
1 请问下,我升级后,已经有两个tipd节点,为什么还是会中断对外服务呢
2 在服务中断过程中,如果有数据请求,服务恢复正常后,还能继续处理这部分请求吗
rolling_updata.yml 脚本里面的执行逻辑可以了解一下,其实 pd leader 会有 transfer 的操作,所以业务中断一段时间也是预期的。
一般还有两种重试情况
对于重试的情况,根据我的操作和得到的信息,感觉像是tidb都不提供对外连接,所以如果中断期间,有写新的写请求,tidb是接收不到的,也就无法重试了,不知道是不是这种情况
这种只能客户端去重试了。
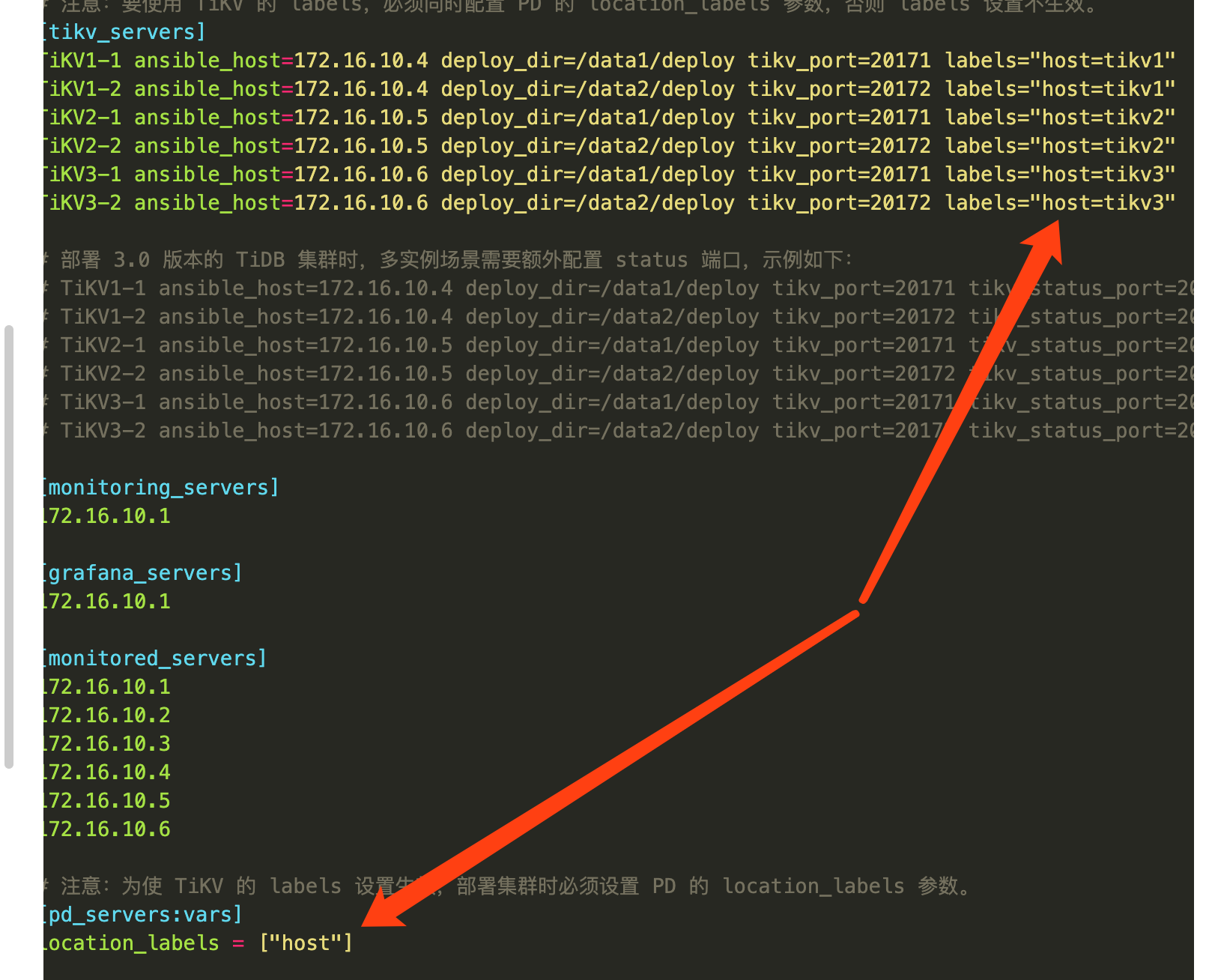
label 可以参考这个链接,https://pingcap.com/docs-cn/stable/how-to/deploy/geographic-redundancy/location-awareness/
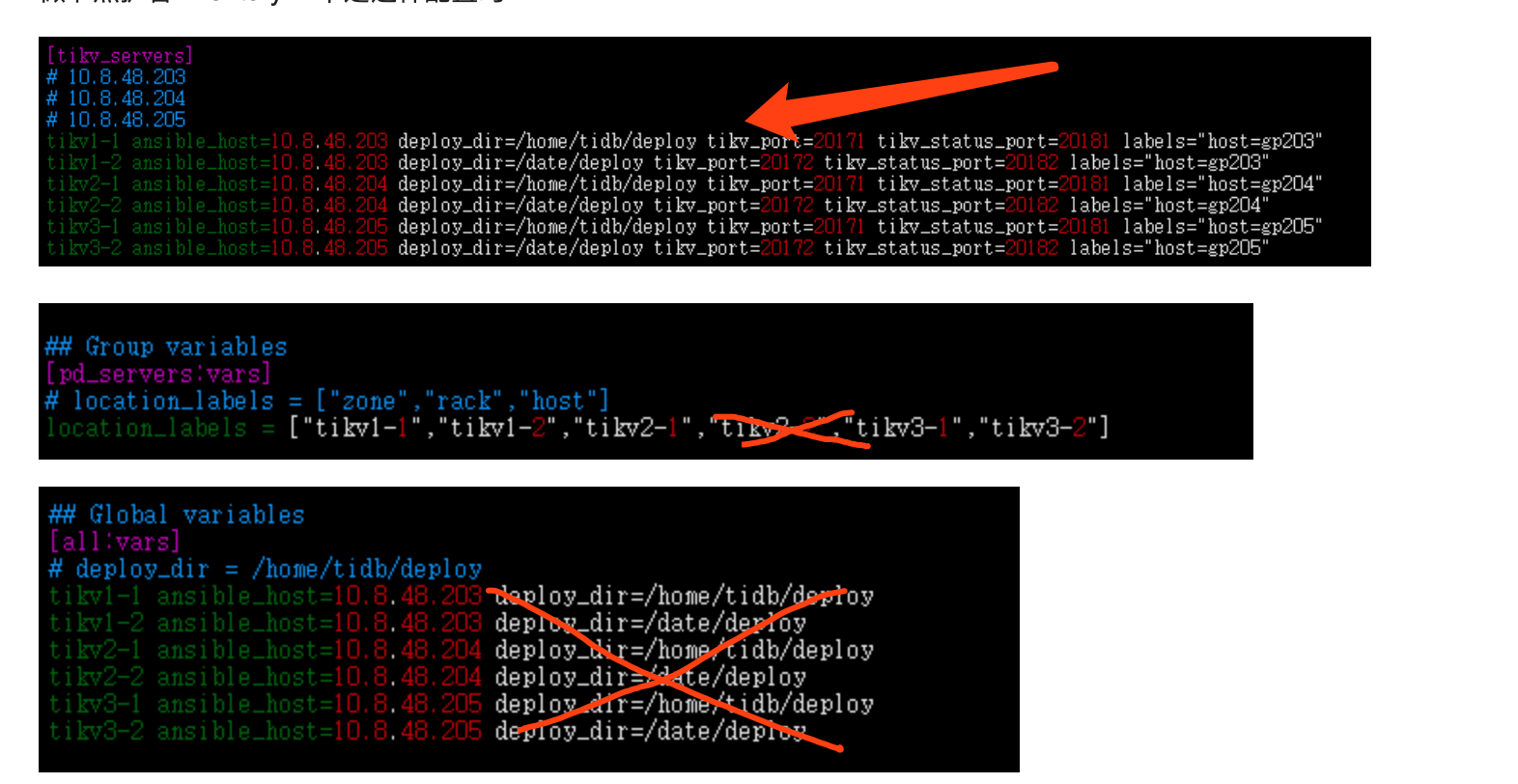
上面为每个 tikv 示例配置 deploy_dir 配置即可,下面的不需要修改,另外 location_labels 设置有些问题,可以参考上述链接。
请帮忙发一下,扩容前的inventory.ini配置
扩容前的文件inventory.ini_bak (1.9 KB)
如果[all:vars] 中的deploy_dir不修改,在[tikv_servers]中又设置了两个地址的deploy_dir,那么会最终部署在哪个目录下面呢
tikv tidb pd中设置的优先于vars中的dir路径
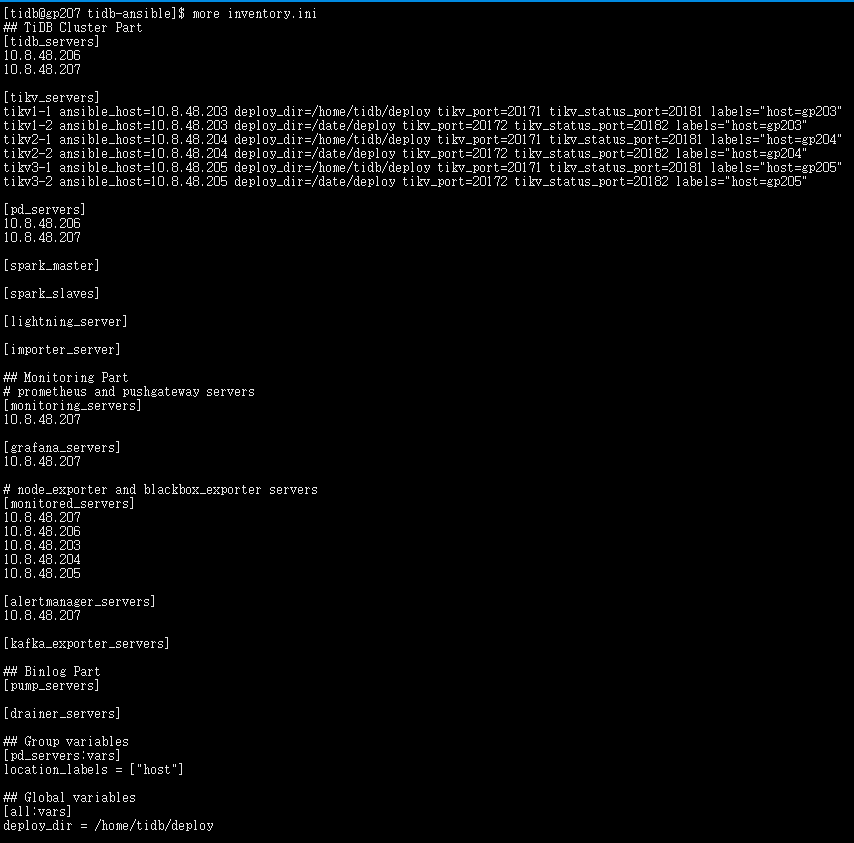
根据指导,重新调整了inventory.ini,结构如下
1 麻烦帮忙再确认下,这样调整是否已经正确了
2 目前一个region有几个副本,在哪个地方配置的呢
3 目前我的tikv有三个节点,停掉一个服务器上面的节点后,集群还可以正常服务,如果按照新的inventory扩容后,停掉一个服务器,还能正常提供服务吗
方便给个具体的需要操作pd-ctl的连接吗,我在官网搜索label,出来内容蛮多的
不是扩容吗? 为什么是升级? 应该按照扩容的方式,新增新的节点
是扩容,从原来一机器一节点,扩容成一机器两节点,但是新扩容的节点,在grafana上没有体现
当前扩容的pd节点,使用ps -ef | grep node_exporter 看一下是否存在进程,多谢.