还是没有找到根本性问题啊,完全对不上啊
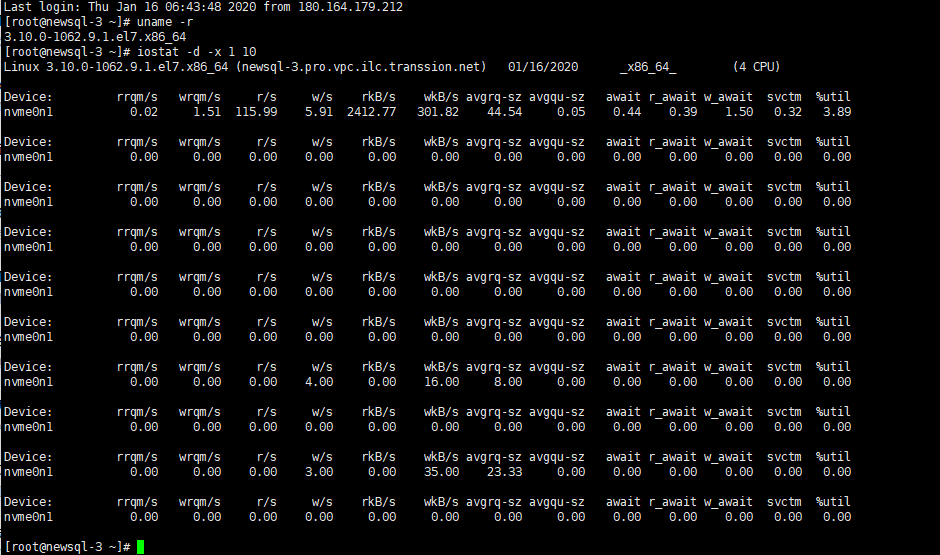
能不能辛苦帮忙仔细分析下问题在哪里啊, 一个问题弄了好几天都没有找到原因,硬件问题我也排除了,那只能说明是集群的问题,iostat跑出来的数据,明显跟grafana里面的不一样
还是没有找到根本性问题啊,完全对不上啊
能不能辛苦帮忙仔细分析下问题在哪里啊, 一个问题弄了好几天都没有找到原因,硬件问题我也排除了,那只能说明是集群的问题,iostat跑出来的数据,明显跟grafana里面的不一样
请问下,这个帖子以及 导入数据库之后,通过监控页面tikv-details页面发现存贮为空 两个帖子关于监控的问题是同一套集群吗 ?
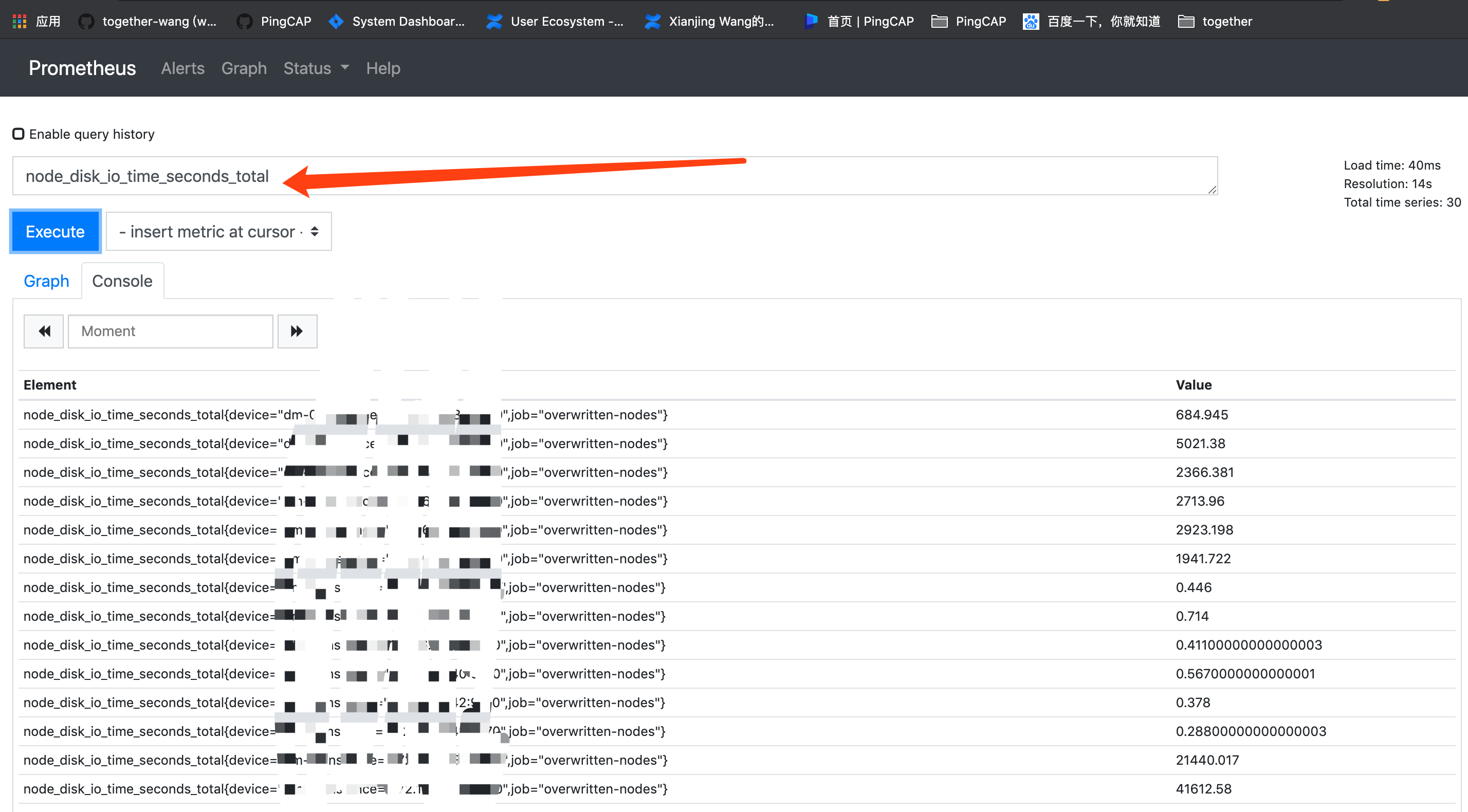
grafana 监控中可以根据相关公式,rate(node_disk_io_time_seconds_total{instance=“$host”}[$interval]) or irate(node_disk_io_time_seconds_total{instance=“$host”}[1m]) 来检查下 prometheus 中的值。
是同一个集群,我已经销毁,重新部署 了
额,那这个问题没办法继续排查了。
1、pd 节点 3.44 按照上述的排查过程 iostat 和 iostat -x -m 5 与 grafana 的指标呈现一个相反的现象
2、使用 io util 的公式 rate(node_disk_io_time_seconds_total{instance=“$host”}[$interval]) or irate(node_disk_io_time_seconds_total{instance=“$host”}[1m]) 在 prometheus 上看下上报的 io util 的数据是否也与 iostat 或 iostat -x -m 5 不一致
3、prometheus 访问方式为,在 inventory 文件中的这部分的 ip:port 方式在浏览器访问:

还有一根问题,我的tikv的面板上还是没有数据,为空
1、pd 数量一般建议为奇数个,具体请查看 tidb 高可用部分
2、pd 一个节点 io util 高,如果使用 iostat 确认服务器 io 本身空闲,但是 grafana 显示比较高,请在 overview 的 system info 面板执行下下述公式,看下 3.44 返回的数据:
irate(node_disk_io_time_seconds_total[1m])
3、tikv 监控没有数据,请在 prometheus 里面检查相关的监控数据是否上报
是这样吗?针对第二个问题
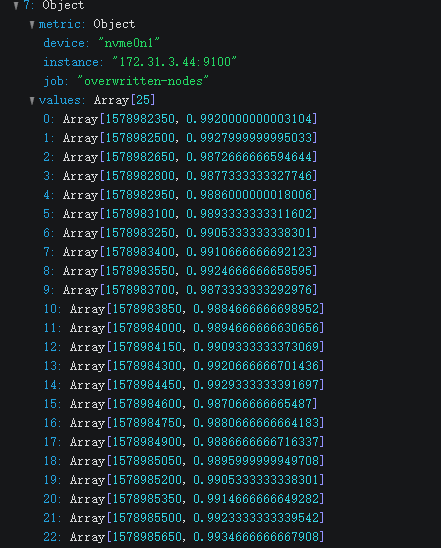
是这个截图吗
第三点怎么上报的,怎么看
我感觉你还是没有回答我的问题啊?跟奇数偶数什么的,我之前第一次部署的时候就是奇数,3个pd,也是这个很高,我感觉问了一个礼拜下来,根本没有解决我的问题,我现在有新增了一个节点是4个,那为啥另外两个还是很低呢,根本没有用到什么io
我这个已经一个多礼拜了,没有解决了啊,你们能不能给个彻底解决方案啊,我能试的都试过了,之前已经销毁过集群,重新部署了一次
这是另两个其中一个
可以看到出问题的节点,iostat每次第一行都是90多的使用率,没问题的节点,都很低. 停止pd以后,也是这样,所以请联系硬件厂商和操作系统看一下,多谢
![]()
![]()
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。