Dam1029
(Dam1029)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:V3.0.5
- 【问题描述】:tidb上线后,大批量查询卡住,被迫回滚
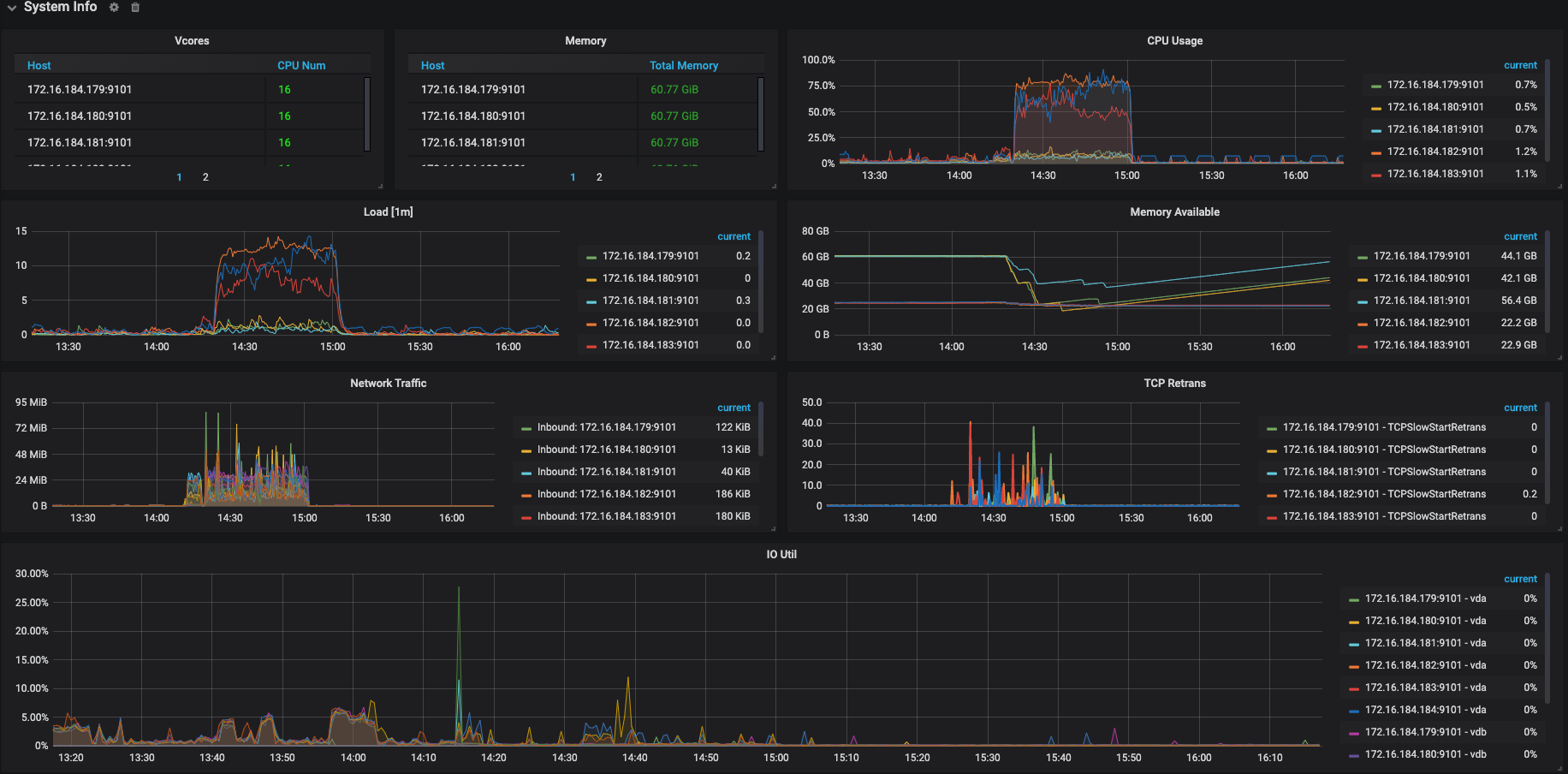
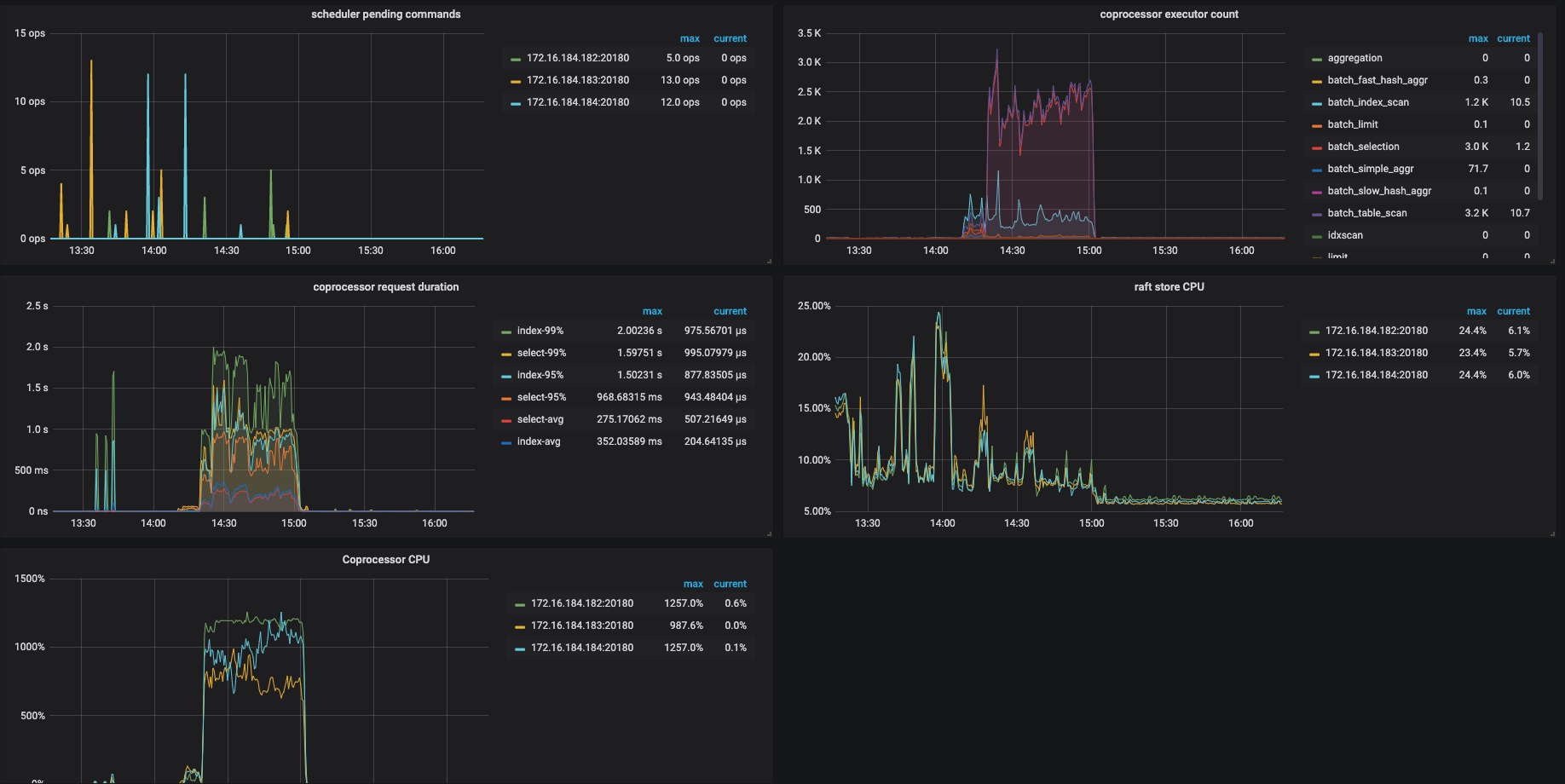
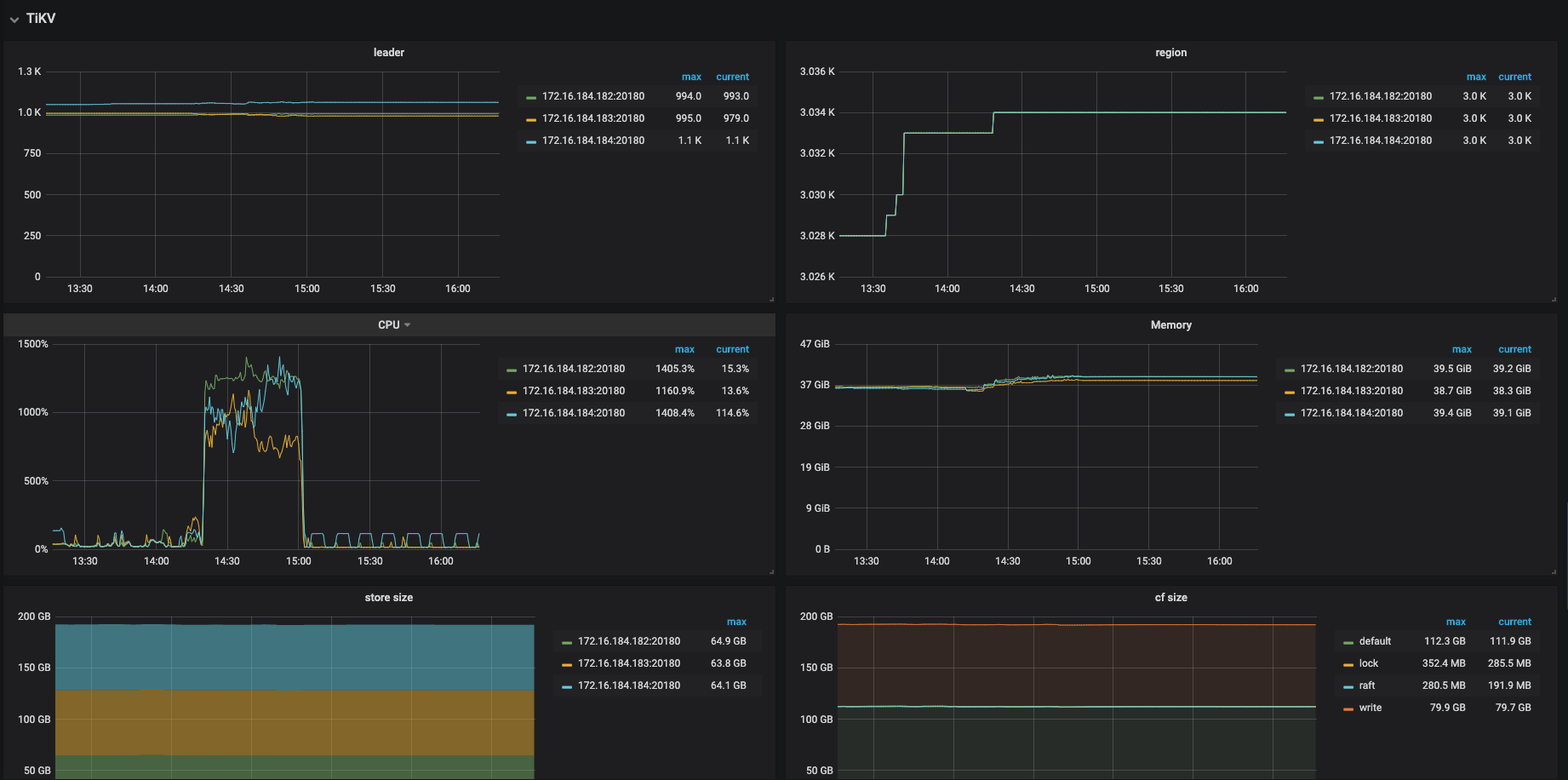
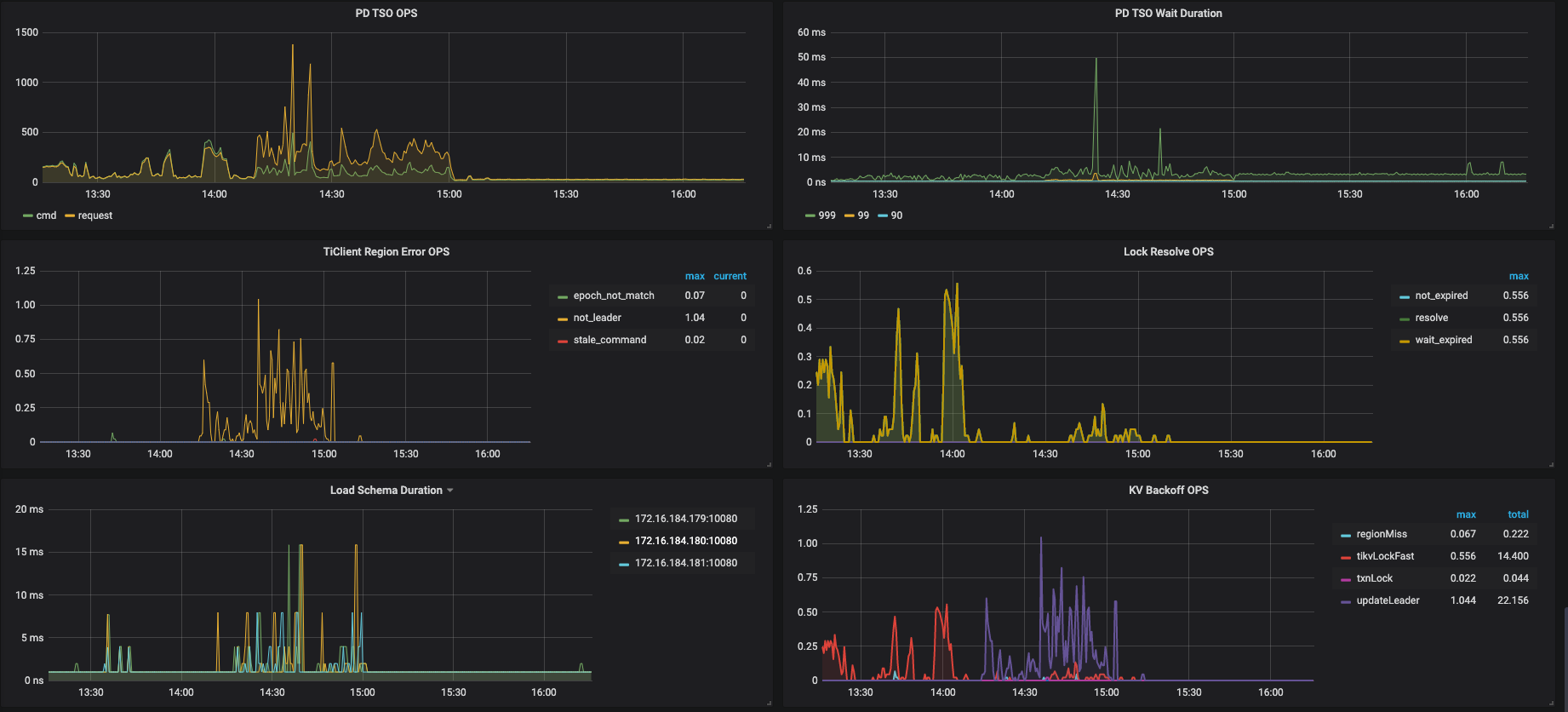
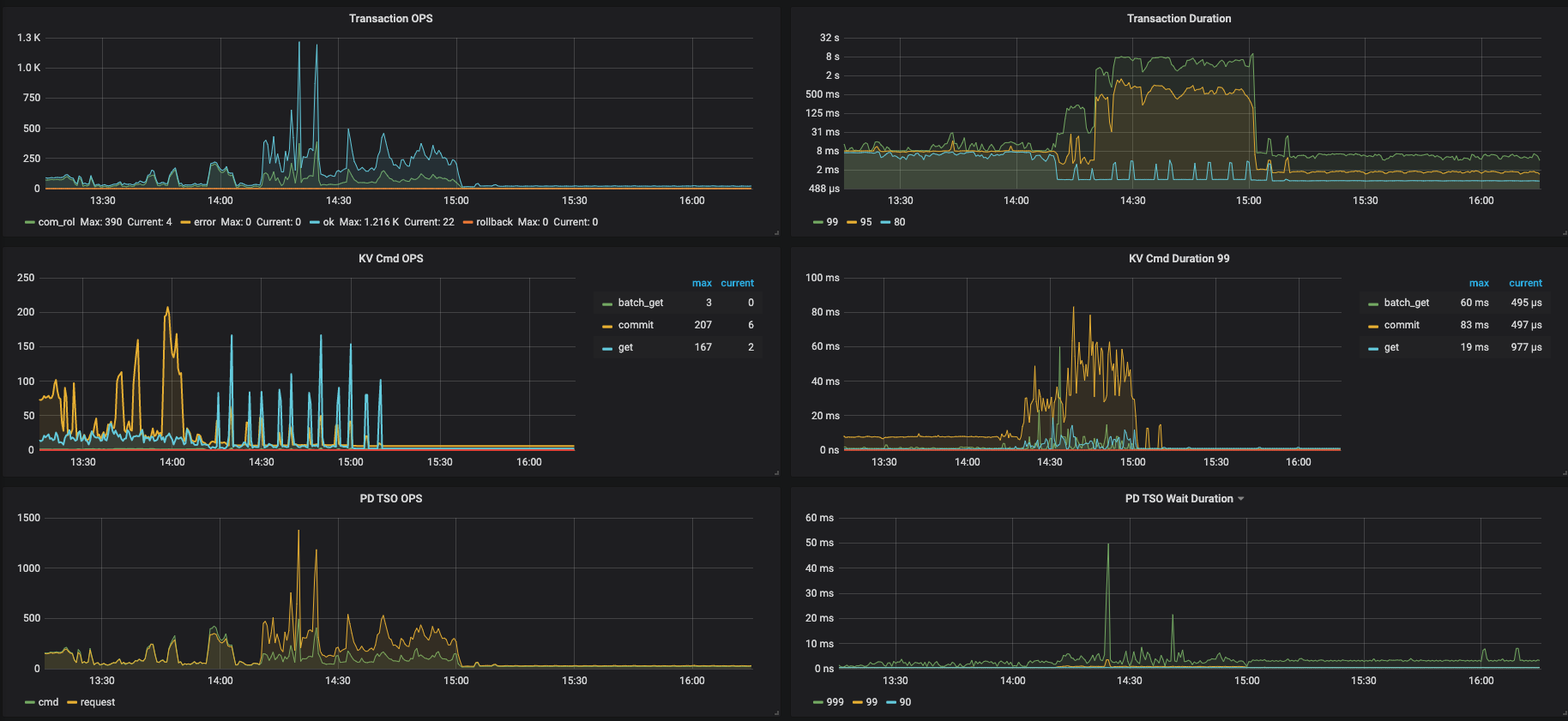
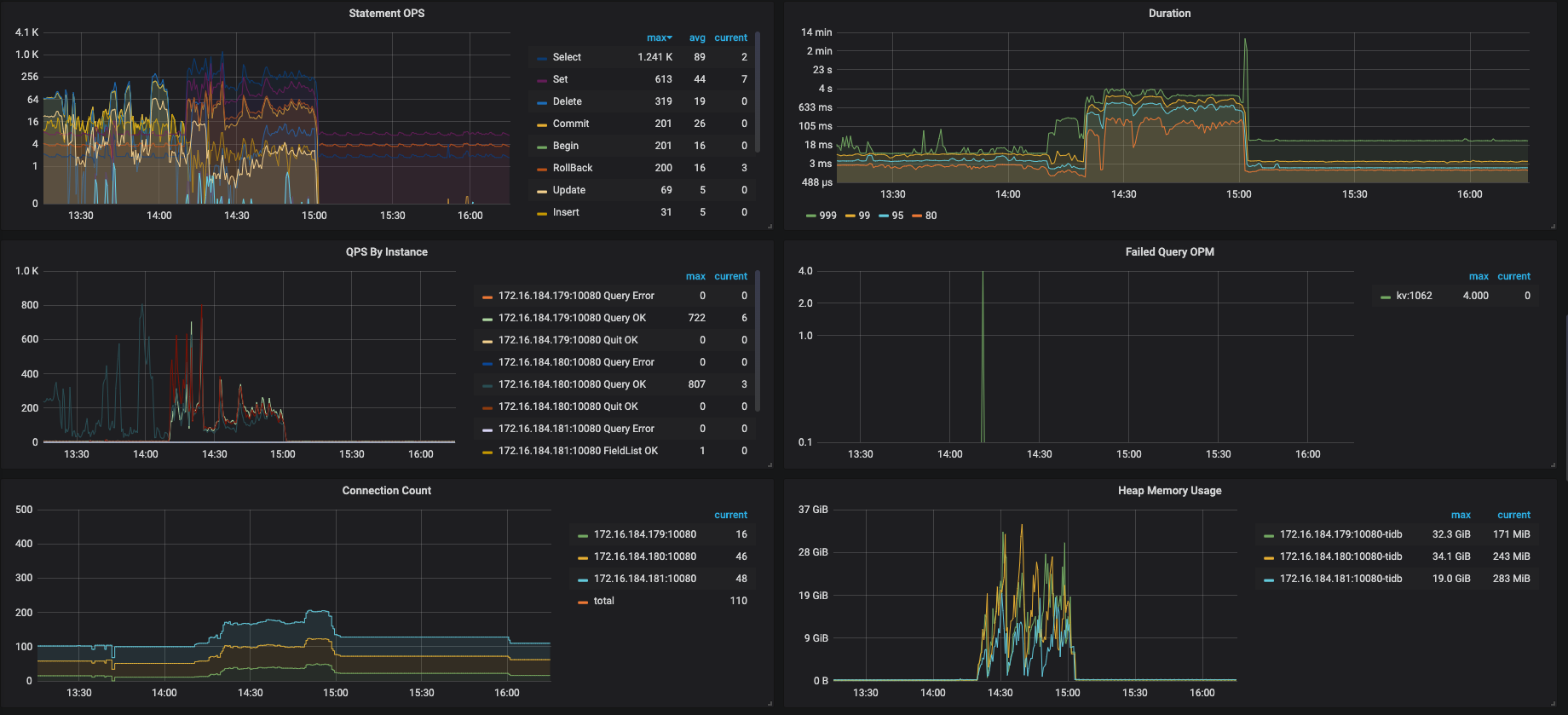
我们尝试将tidb作为hive metastore的元数据库,今天下午进行产线环境的正式上线,但是上线后不久,许多hive、spark任务失败,报错是无法连接到hive metastore或者连接超时,由于出错任务较多、影响范围较大,后来执行了回滚操作。 我们的机型是16C64G,tidb的内存和tikv的cpu消耗的比较多,以下是tidb的一些监控图,请大佬帮忙排查以下原因,以及改进措施。
请提供一下机器配置,部署结构,以及出错误时间段的错误日志
Dam1029
(Dam1029)
3
一、机型与部署
- 共使用6台机器,其中3台机器混合部署TiDB和PD,另外3台部署TiKV。
- TiDB机器机型为阿里云G6, 配置为:16C64G,万兆网卡,500G SSD云盘
- TiKV机器机型为阿里云I2G, 配置为:16C64G,万兆网卡,1788G 本地SSD盘
二、时间段
TiDB正式上线时间段为12月24日14:00~15:00,上线后不久查询hang住,15:00左右执行了回滚操作,所有查询断开了与tidb的连接。
三、日志
tikv.log (676.2 KB)
pd.log (884.1 KB)
tidb.log太大了,怎么上传?
从监控来看发现,TiKV 的 CPU 占用比较高,你们有跑复杂的查询吗?
能提供一下这个时间段的慢查询吗?
只需要提供错误信息就可以
Dam1029
(Dam1029)
5
1、tidb.log中并没有[ERROR]日志,有几个error关键字,应该是回滚的时候断开连接产生的。
tidb_1224_error.log (2.2 KB)
2、慢查询日志也很大,大概90多MB,慢查询阀值使用的默认配置,我截取了一部分tidb_slow_query_part.log (171.0 KB)
Dam1029
(Dam1029)
6
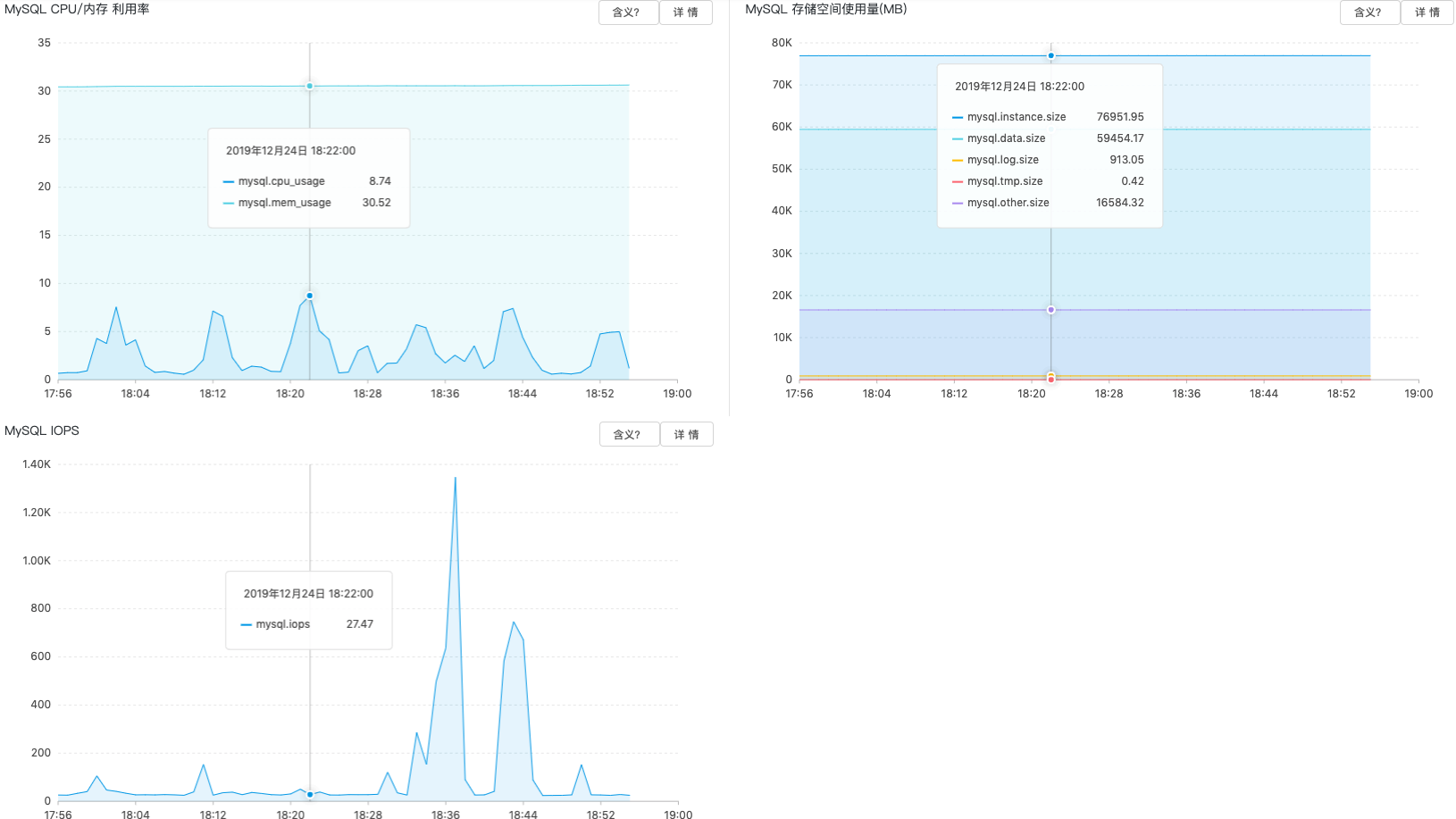
大佬,看出来一些线索了吗? 我们后来回滚到了阿里的RDS上了,之前是考虑RDS查询时间慢、单表条数过亿所以尝试使用TiDB的。RDS的机器配置是32C128G独享型,以下是RDS当前的运行指标。
目前来看瓶颈在 TiKV 的 CPU 上,但从慢查询日志的内空来看,产生慢查询的语句都不是特别复杂
TiKV 的配置能提供一下吗
Dam1029
(Dam1029)
8
TiKV机器机型为阿里云I2G, 配置为:16C64G,万兆网卡,1788G 本地SSD盘, 还需要其他什么参数配置吗? 我看到tikv.log里面有不少ERROR信息.
[2019/12/24 14:15:30.727 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 16704, leader may Some(id: 16706 store_id: 5)\" not_leader { region_id: 16704 leader { id: 16706 store_id: 5 } }"]
[2019/12/24 14:15:30.727 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 16704, leader may Some(id: 16706 store_id: 5)\" not_leader { region_id: 16704 leader { id: 16706 store_id: 5 } }"]
[2019/12/24 14:15:30.978 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 16704, leader may Some(id: 16706 store_id: 5)\" not_leader { region_id: 16704 leader { id: 16706 store_id: 5 } }"]
[2019/12/24 14:15:30.978 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 16704, leader may Some(id: 16706 store_id: 5)\" not_leader { region_id: 16704 leader { id: 16706 store_id: 5 } }"]
[2019/12/24 14:15:31.202 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 16704, leader may Some(id: 16706 store_id: 5)\" not_leader { region_id: 16704 leader { id: 16706 store_id: 5 } }"]
[2019/12/24 14:15:31.202 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 16704, leader may Some(id: 16706 store_id: 5)\" not_leader { region_id: 16704 leader { id: 16706 store_id: 5 } }"]
[2019/12/24 14:15:32.433 +08:00] [INFO] [pd.rs:566] ["try to transfer leader"] [to_peer="id: 20198 store_id: 5"] [from_peer="id: 20197 store_id: 1"] [region_id=20196]
[2019/12/24 14:15:32.433 +08:00] [INFO] [peer.rs:1762] ["transfer leader"] [peer="id: 20198 store_id: 5"] [peer_id=20197] [region_id=20196]
[2019/12/24 14:15:32.433 +08:00] [INFO] [raft.rs:1294] ["[region 20196] 20197 [term 6] starts to transfer leadership to 20198"]
[2019/12/24 14:15:32.433 +08:00] [INFO] [raft.rs:1304] ["[region 20196] 20197 sends MsgTimeoutNow to 20198 immediately as 20198 already has up-to-date log"]
[2019/12/24 14:15:32.434 +08:00] [INFO] [raft.rs:924] ["[region 20196] 20197 [term: 6] received a MsgRequestVote message with higher term from 20198 [term: 7]"]
[2019/12/24 14:15:32.434 +08:00] [INFO] [raft.rs:723] ["[region 20196] 20197 became follower at term 7"]
[2019/12/24 14:15:32.434 +08:00] [INFO] [raft.rs:1108] ["[region 20196] 20197 [logterm: 6, index: 8862, vote: 0] cast MsgRequestVote for 20198 [logterm: 6, index: 8862] at term 7"]
[2019/12/24 14:15:32.530 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 20196, leader may Some(id: 20198 store_id: 5)\" not_leader { region_id: 20196 leader { id: 20198 store_id: 5 } }"]
[2019/12/24 14:15:32.863 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 20196, leader may Some(id: 20198 store_id: 5)\" not_leader { region_id: 20196 leader { id: 20198 store_id: 5 } }"]
[2019/12/24 14:15:33.070 +08:00] [ERROR] [endpoint.rs:454] [error-response] [err="region message: \"peer is not leader for region 20196, leader may Some(id: 20198 store_id: 5)\" not_leader { region_id: 20196 leader { id: 20198 store_id: 5 } }"]
[2019/12/24 14:15:33.648 +08:00] [INFO] [process.rs:188] ["get snapshot failed"] [err="Request(message: \"peer is not leader for region 20556, leader may Some(id: 20559 store_id: 4)\" not_leader { region_id: 20556 leader { id: 20559 store_id: 4 } })"] [cid=145441723]
[2019/12/24 14:15:34.120 +08:00] [INFO] [raft.rs:924] ["[region 20556] 20557 [term: 8] received a MsgRequestVote message with higher term from 20558 [term: 9]"]
[2019/12/24 14:15:34.120 +08:00] [INFO] [raft.rs:723] ["[region 20556] 20557 became follower at term 9"]
[2019/12/24 14:15:34.120 +08:00] [INFO] [raft.rs:1108] ["[region 20556] 20557 [logterm: 8, index: 640022, vote: 0] cast MsgRequestVote for 20558 [logterm: 8, index: 640022] at term 9"]
[2019/12/24 14:15:42.839 +08:00] [INFO] [raft.rs:1662] ["[region 20312] 20313 [term 6] received MsgTimeoutNow from 20314 and starts an election to get leadership."]
[2019/12/24 14:15:42.840 +08:00] [INFO] [raft.rs:1094] ["[region 20312] 20313 is starting a new election at term 6"]
[2019/12/24 14:15:42.840 +08:00] [INFO] [raft.rs:743] ["[region 20312] 20313 became candidate at term 7"]
目前能确认的是瓶颈在 TiKV 的 CPU,而且读数据 (查询)占了大头,所有我们想分析一下到底是哪条 SQL 引起的
Dam1029
(Dam1029)
13
是的,绝大多数都是查询操作,写操作比较少。 慢查询日志比较大,怎么上传给你?
丫头吖88
(丫头吖88)
15
你好,请问解决了吗,我的也是外部大量查询导致这个问题,但是查询的sql语句都很简单
yilong
(yi888long)
16
您好:
麻烦新建个帖子,我们来跟追您的问题,多谢。 描述清楚您的版本信息, 上传几个慢sql日志, 多谢
丫头吖88
(丫头吖88)
17
谢谢,还是之前我发的帖子,问题没有解决,也不知道怎么解决,我在自己的帖子里重新给您描述一下,谢谢。
yilong
(yi888long)
18
感谢,再您的帖子里答复吧, TIKV总有一个CPU高,热点越分裂越多 问题已解决。 多谢