【版本】v5.2.1
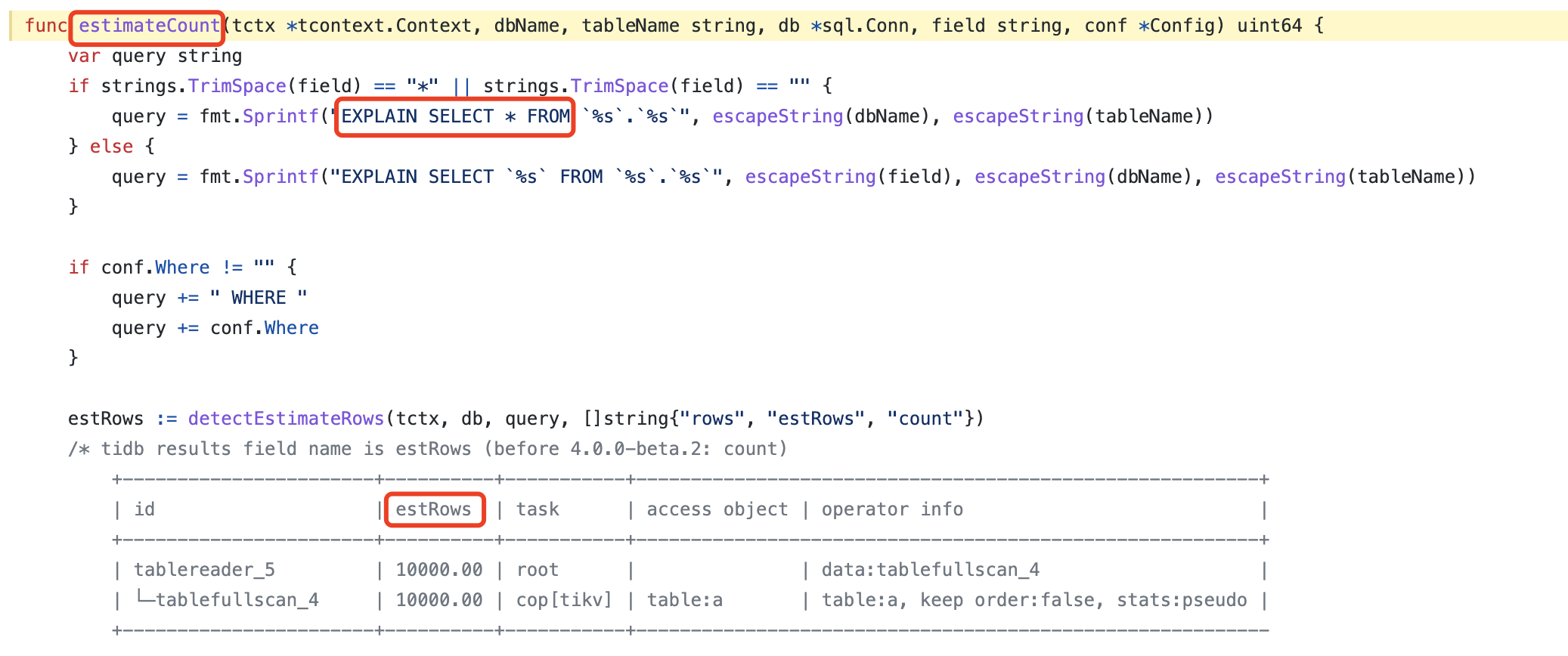
dump导出提示[“skip concurrent dump due to estimate count < rows”] [“estimate count”=10000] [conf.rows=200000] ,这里estimate count是根据什么计算的,没有统计信息的默认是10000吗?
[2021/11/03 14:56:21.934 +08:00] [INFO] [dump.go:490] [“get estimated rows count”] [database=d_xxx] [table=TF_F_xxxx] [estimateCount=10000]
[2021/11/03 14:56:21.934 +08:00] [WARN] [dump.go:496] [“skip concurrent dump due to estimate count < rows”] [“estimate count”=10000] [conf.rows=200000] [database=d_xxxx] [table=TF_F_xxxx]
[2021/11/03 14:56:21.934 +08:00] [INFO] [dump.go:448] [“didn’t build tidb concat sqls, will select all from table now”] [database=d_xxxx] [table=TF_Fxxxxxx]
[2021/11/03 14:56:21.935 +08:00] [WARN] [writer.go:230] [“no data written in table chunk”] [database=d_xxxx] [table=TF_F_xxxx] [chunkIdx=0]