» config show
{
“replication”: {
“enable-placement-rules”: “true”,
“isolation-level”: “”,
“location-labels”: “host”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“enable-cross-table-merge”: “true”,
“enable-debug-metrics”: “false”,
“enable-joint-consensus”: “true”,
“enable-location-replacement”: “true”,
“enable-make-up-replica”: “true”,
“enable-one-way-merge”: “false”,
“enable-remove-down-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“high-space-ratio”: 0.7,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 4,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 16,
“max-snapshot-count”: 4,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 2048,
“region-score-formula-version”: “v2”,
“replica-schedule-limit”: 128,
“scheduler-max-waiting-operator”: 5,
“split-merge-interval”: “1h0m0s”,
“store-limit-mode”: “manual”,
“tolerant-size-ratio”: 0
}
}
------------以下是我执行的------------
» config set replica-schedule-limit 512
Success!
» config set max-snapshot-count 16
Success!
» config set max-pending-peer-count 64
Success!
» scheduler add evict-leader-scheduler 302321060
Success!
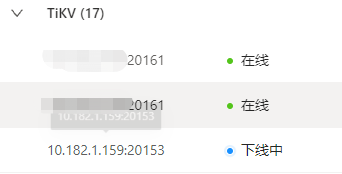
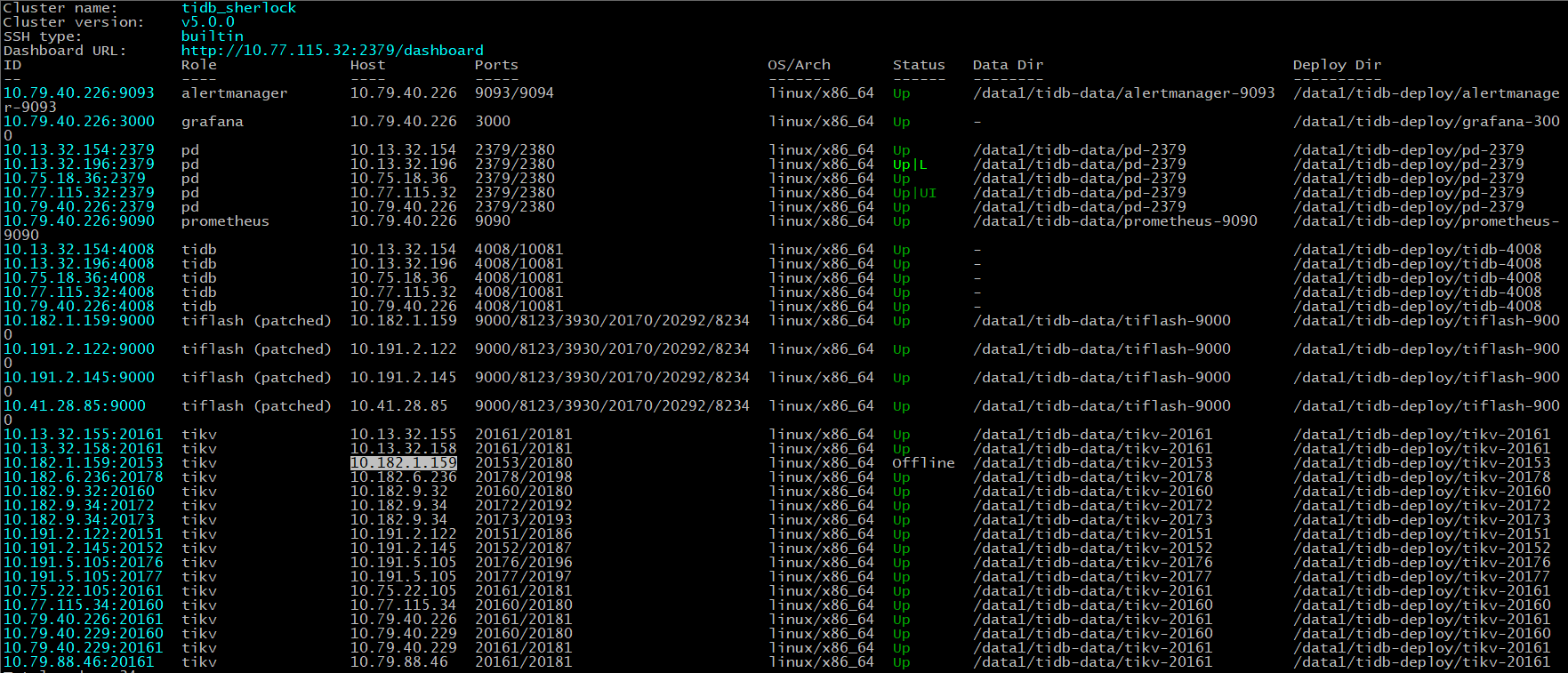
等待了好几天之后,依旧没有结果,还是有1032个region,无法迁移,监控显示下线中…