LUAgam
(Lu Agam)
1
pingcap-benchmarksql:https://github.com/pingcap/benchmarksql
原生benchmarksql:https://sourceforge.net/projects/benchmarksql/
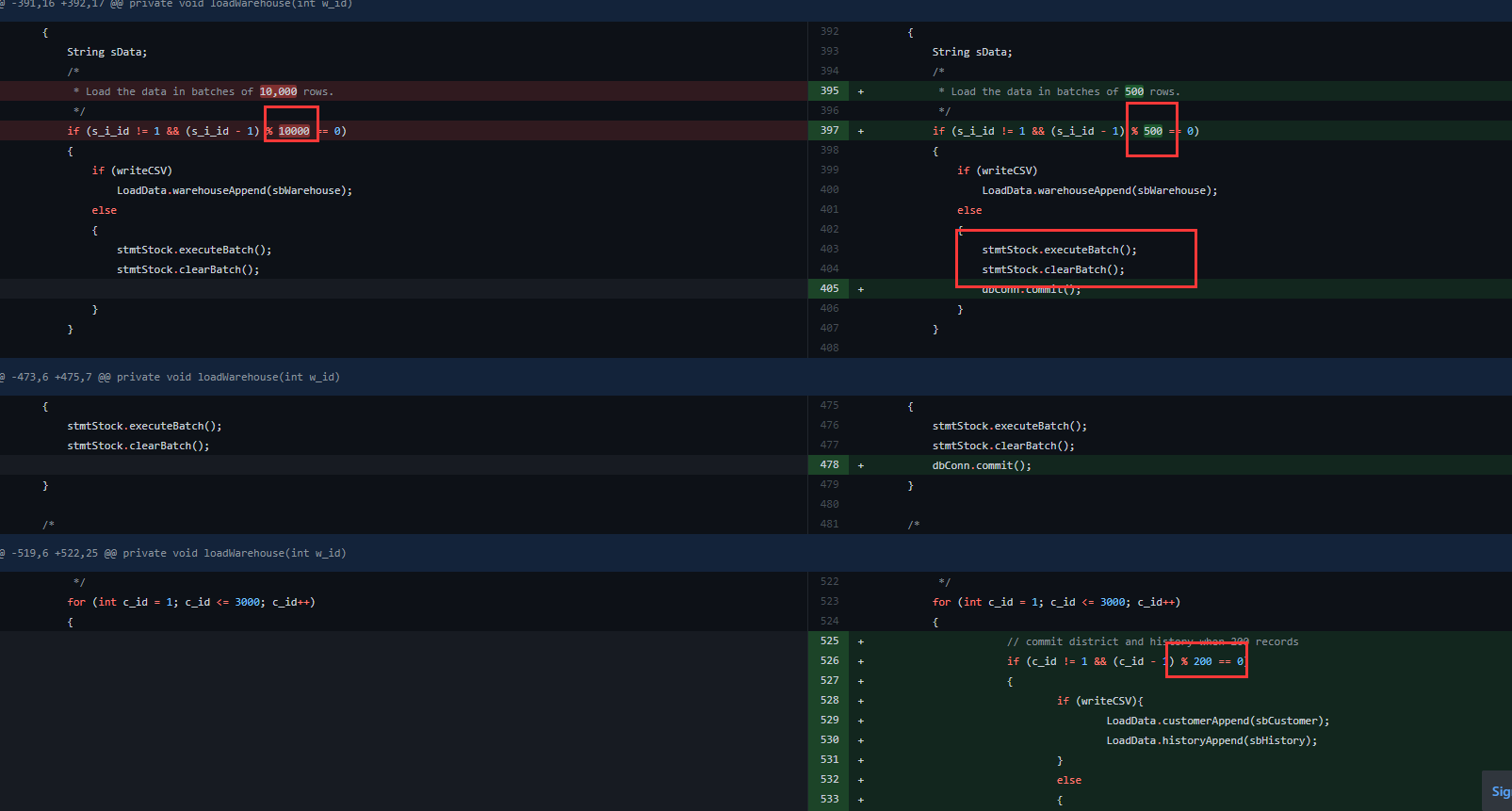
通过两者源码查看,发现load data期间,pingcap版本相比于原生的banchmarksql在insert中的values数目明显减少,不知道pingcap这样做是基于什么考量?如果是针对的是insert的时间,那么有没有做pingcap和原生benchmarksql在相同仓数的情况下,load data时间的对比?
qizheng
(qizheng)
2
调整 insert batch 大小是基于之前测试的参考值,在 500 以内的 batch tidb 集群能达到比较高的吞吐量,而过大的 batch/事务一般不推荐
LUAgam
(Lu Agam)
3
所以这个修改只是为了适配tidb了
那么我看最新版的tpcc测试,提供了 TiDB Lightning导入的方式,这种方式和批量insert方式,效率差距多少?有没有测试结果供查看
qizheng
(qizheng)
4
TiDB Lightning 也分为几种导入模式,其中 tidb 模式相当于批量 insert 的方式,效率对比可以看下这个文档,如果追求速度可以用 local 模式
https://docs.pingcap.com/zh/tidb/v5.0/tidb-lightning-backends
LUAgam
(Lu Agam)
5
看了文档,如果结合benchmarksql的话,local模式就不能直接使用了吧, Importer-backend模式可以对csv文件进行导入
Importer-backend相比于批量insert效率提升还是很明显的,另外 Importer-backend模式有没有更多原理性的描述,想知道为啥这么快?
system
(system)
关闭
7
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。