本文根据 PingCAP DevCon 2021 上来自微众银行资深数据库架构师黄蔚的分享整理而成,主要阐述 TiDB 在微众银行的应用实践 ,包括微众银行选择 TiDB 的背景和 TiDB 的部署架构,以及 TiDB 在 贷款核心批量场景的应用 ,最后分享了基于 TiDB 优化方案的最佳实践和未来规划。
- 视频回顾: 【PingCAP DevCon 2021】微众银行 黄蔚-微众银行核心批量场景的 TiDB 实践_哔哩哔哩_bilibili
- 讲义下载:微众银行-黄蔚-微众银行核心批量场景的 TiDB 实践.pdf (467.8 KB)
TiDB 的产品优势
从 2018 年底微众银行开始接触 TiDB 的团队,到 2019 年上线,TiDB 在数据库的选型之中展现了很多独有的优势。
TiDB 兼容 MySQL 协议 ,同时也兼容 MySQL 的生态工具,比如备份、恢复、监控等等,不管是应用本身还是运维或是开发人员,从 MySQL 迁移到 TiDB,其成本和门槛都较低。对于 TiDB 原生的计算、存储分离的架构 ,用户将不必担心容量或者单机性能的瓶颈,某种程度可以把 TiDB 当作一个很大的 MySQL 来使用。同时 TiDB 的 数据多副本强一致的特性 对金融场景来说十分重要,TiDB 还 天然支持多 IDC 的部署架构 ,可以支持应用做到同城多活的部署架构。此外, TiDB 开源社区的运营也非常活跃 ,比如在 AskTUG 平台可以看到很多用户的典型问题的处理方法,包含大量的宝贵经验可以借鉴,可以进一步降低用户使用 TiDB 的门槛。
现在使用 TiDB 的用户越来越多,不管是互联网头部厂商或者金融行业用户都在大量使用,这也是 TiDB 产品越来越成熟的体现,也给更多用户使用 TiDB 带来了更强的信心。
TiDB 在微众银行的部署架构
TiDB 的特性是否能够满足金融机构高可用的架构需求?
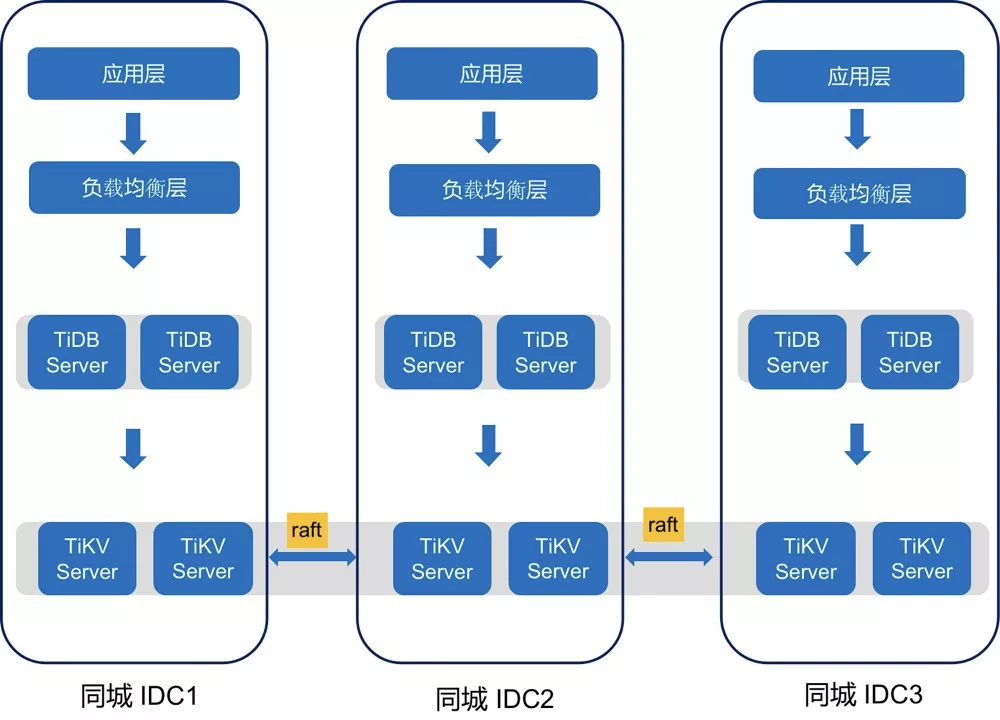
这是 TiDB 在微众银行的部署架构,如图所示,首先 TiKV 选择三副本,分别部署在同城的三个数据中心,这样可以实现 IDC 级别的高可用,同时在每个 IDC 部署了一套 TiDB Server,通过绑定到负载均衡器提供 VIP 服务,这样使得应用可以做到多活接入的模式。这套架构也经受过 IDC 级别的真实故障的演练验证,将其中一个 IDC 的网络全部断掉,观察到集群可以快速恢复,我们认为 TiDB 能够符合金融场景高可用的要求 。
核心批量核算场景
贷款核心批量核算 是金融行业比较经典且非常重要的场景,我们将其接入到了 TiDB。下图是之前微众银行贷款核心批量应用场景的架构,左边这部分有很多业务单元,相当于把用户的数据做了单元化拆分,每一个单元化数据可能不一样,但架构和部署模型是一样的,底层用的是单实例数据库,同时批量是在每一个单实例数据库上面运行,最终把批量结果 ETL 到大数据平台给下游使用,那么这个架构有哪些瓶颈或者优化点呢?
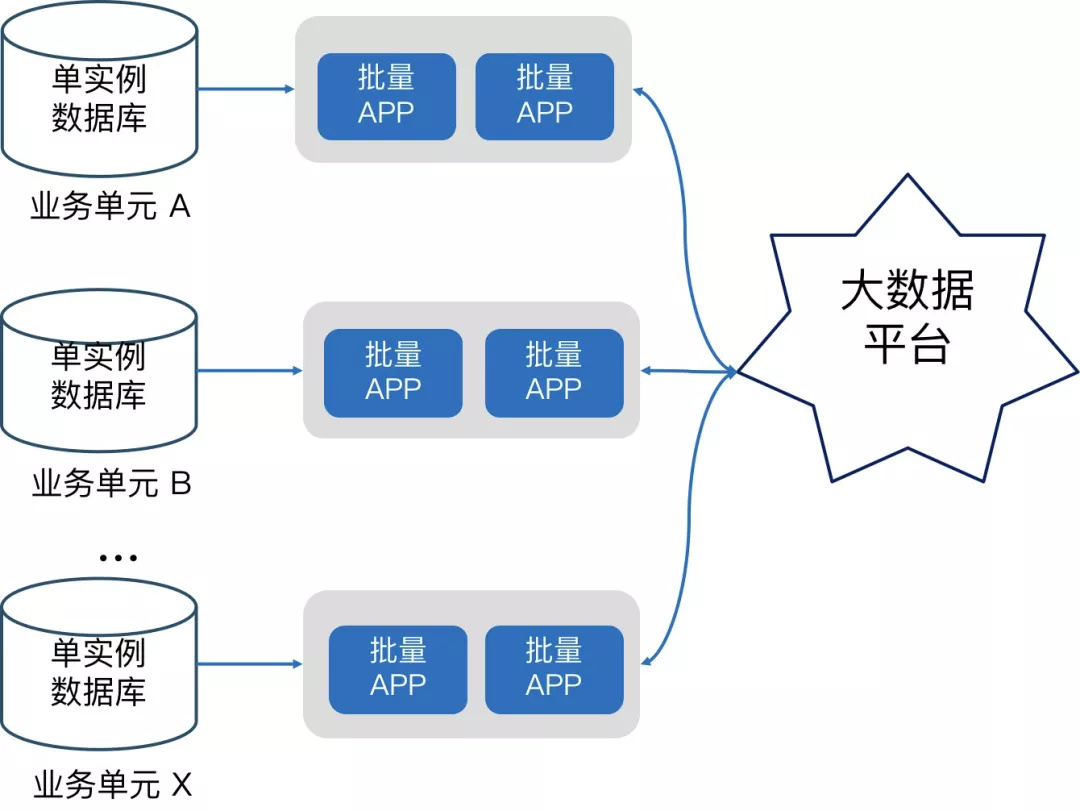
它是一个 纯批量 的应用,意味着有大量的批量的写入、更新以及运算,而且数据量都特别大,亿级或者十亿级别以上,随着业务快速开展,借据数、用户数和流水数据也在持续增涨,如果使用单机数据库来承载,首先受限于单机数据库的性能上限,跑批耗时会越来越长,而且之前单机数据库负载已经很高,IO、CPU 已经达到 70% ~ 80%,如果想提升跑批效率,应用通过增加并发的方式是有风险的,因为数据库负载太高可能造成主备复制延迟或者遇到故障无法进行快速主备切换,所以效率很难提升;其次单机数据库对这种亿级或者十亿级的表加字段或者数据管理难度非常大,虽然微众银行日常会用 online DDL 工具比如 pt-online-schema-change 来做表变更操作,但也会有小概率锁表风险。另外基于资源利用率考虑,批量系统和联机系统复用了同一套单机数据库,所以如果批量任务造成高负载,很可能会影响联机交易。基于这些背景问题,微众银行借助 TiDB 做了架构优化的升级。
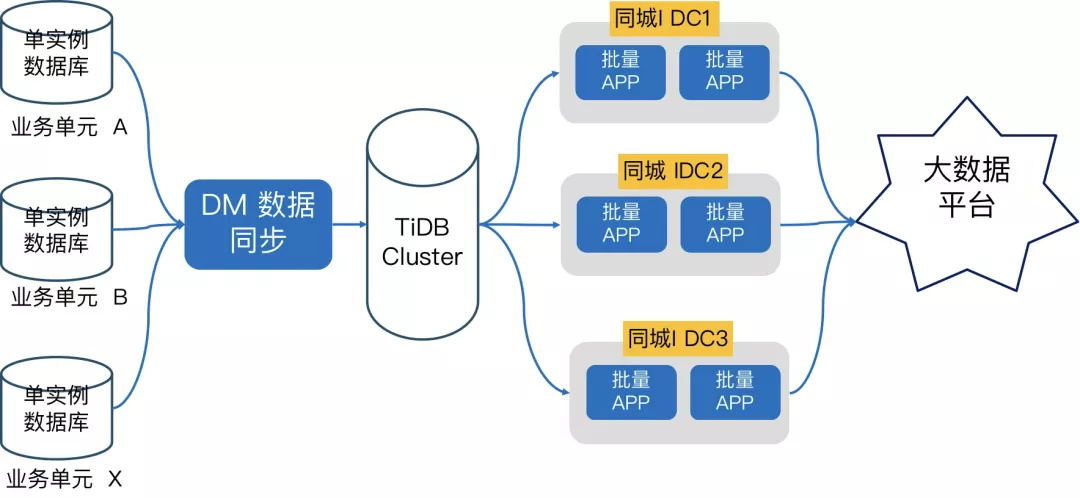
升级改造后的架构如下图所示,可以看到微众银行把各个业务单元的数据通过 DM 工具把数据实时同步和汇总到 TiDB,然后批量 APP 直接基于 TiDB 做批量计算,再把结果传到大数据平台,相当于借助了 TiDB 的水平扩展性来达到批量效率的水平扩展。之前是传统的 MySQL 主备架构,会要求 APP 服务器 要跟 MySQL 的主节点是部署在同一个 IDC,而如果是跨机房访问,网络延时会比较大进而影响批量耗时,所以其他 IDC 的 APP服务器 就处于 standby 的状态,会有一定的资源浪费,而 TiDB 架构的所有 TiKV 节点可以同时读写,所以 可以多个 IDC 同时启动批量任务,最大化资源利用率 。
价值收益
TiDB 在微众银行贷款核心业务场景中的使用,总结有三个主要的价值收益。
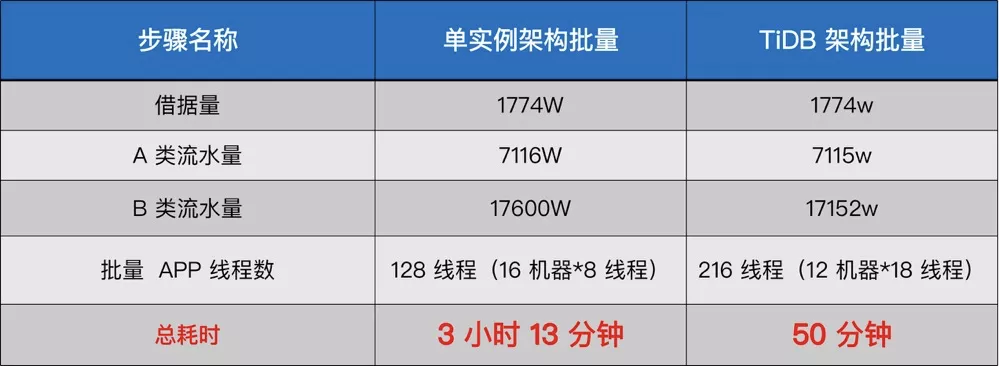
- 批量效率的提高 。下图左边是微众银行其中一个贷款业务的账单日的批量耗时对比,可以看到在单实例架构下面,批量大概是跑三个多小时,而微众银行通过借助 TiDB 进行架构的升级优化后,耗时减少到了 50 分钟左右,有绝对效率上的提升。
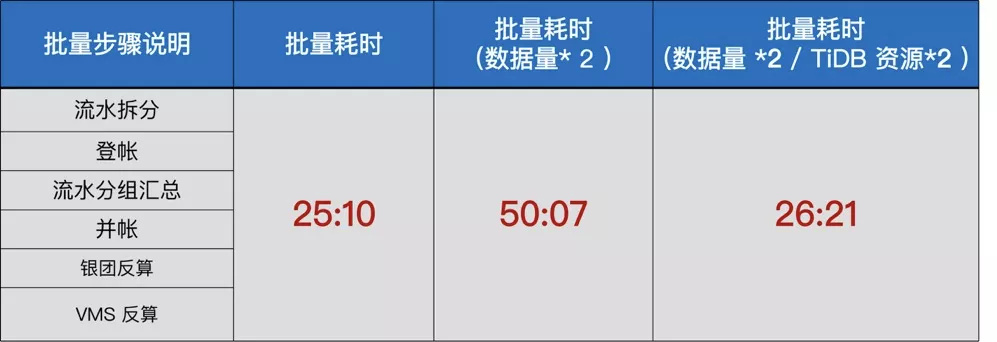
- 线性水平扩展 。微众银行的需求不仅仅是效率提升,而且要求其做到水平扩展,也就是弹性伸缩。因为随着业务发展,借据量包括用户量在持续增长,如果存在热点或者其他瓶颈,以后想继续提升将十分困难,下图右边是展示其批量耗时的对比情况,在初始的一个资源情况下大概跑 25 分钟,如果数据量翻倍,耗时增加到 50 分钟,如果想把这个耗时降下来再把资源也翻倍,可以发现耗时又降回到 26 分钟左右,可见已经具备线性扩展能力。所以除了效率上的提升,线性扩展能力的一大好处就是随着业务持续的发展,借据数、借据量都在快速增长,这套架构将无需担心业务快速增长可能出现的技术瓶颈,业务可以更加聚焦于产品本身,这是 TiDB 带来的一个实实在在的业务价值。
- 批量系统与联机交易系统分离 。前面提到跟联机系统是因为资源的考虑做了一个复用,现在拆分之后实际上跟联机就已经完全剥离了,并且没有像单机数据库的主备复制延迟,可以最大化资源利用率来提升批量效率。
基于 TiDB 的优化
以上这些收益可以看到比较明显的效果,那么微众银行做了哪些优化或者遇到了哪些问题呢?
-
SQL 模式优化 。TiDB 因为本身分布式架构其单条请求时延会相对比 MySQL 更高,所以需要去把一些跟数据库频繁交互的请求进行打包,尽量减少交互,比如把多个 select 改成 in 的方式,把 insert 多条改成 insert 单条多 values 的方式,把多个 update 改成 replace 多条 values 的方式。此外,因为把多个单元化的数据全部汇总到一个 TiDB 集群,那么它的单表数据量一定非常非常大,如果跑了一个比较低效的 SQL,很容易把这个集群搞垮,比如存在着 OOM 的风险,所以需要特别注意 SQL 的审核和调优。再比如早期版本会出现执行计划不准确的问题,在 4.0 版本支持 SQL 执行计划绑定,可以对一些高频的 SQL 进行绑定,使其运行更加稳定。因为微众银行接入 TiDB 比较早期,所以主要使用的是乐观锁模式,应用也做了很多适配,目前适配乐观锁模式的代码已经固化为一个通用模块,新系统接入时直接拿来用就可以了。
-
热点与应用并发优化 。使用 TiDB 比较多的用户可能会对热点这个问题比较熟悉,前面提到弹性伸缩,而要做弹性伸缩,数据必须足够离散,所以微众银行在前期接入 TiDB 的时候也发现像在 MySQL 上的 Auto Increment 特性,可能会存在热点问题,还比如像用户的卡号、借据号也可能是一些连续的数字,所以微众银行针对这两块做了一些调整或优化,比如把它改成 Auto Random,然后把一些卡号,根据它的数据分布规律,通过算法提前把这些数据的分布区间算出来,再通过 Split Region 打散功能进行预打散,这样大批量瞬时写入时就可以充分利用每一个节点的性能;另外也对低频修改、高频访问的小表进行了应用内的缓存处理,缓解热点读问题。除了数据需要足够离散,应用同样也要做分布式改造优化,因为应用是分布式的,所以需要一个 App Master 节点来做数据分片的工作,然后把分片任务均匀分摊到每一个 App 上做运算,运行期间还需要监测每个分片任务的状态和进度;最终通过数据和应用的协同优化,达到整体具备的水平扩展能力。
-
数据同步与数据校验优化 。这就是前面提到微众银行通过 DM 工具把各个业务单元的数据汇总起来,早期使用的 DM 1.0 版本不具备高可用特性,这在金融场景下是比较致命的。而在 DM 2.0 版本上包括高可用性,兼容灰度 DDL,易用性等等几个特性都已稳定上线。此外是数据校验部分,因为是核心批量场景,数据同步必须做到数据不丢、不错,所以应用也内嵌了数据 checksum 的逻辑,比如在 MySQL 入库时先对数据进行分片,然后把各个分片的 checksum 值写到表里面,再通过 DM 同步到下游 TiDB,最后应用在跑批期间从 TiDB 把各个分片加载出来,然后再跑一遍对应分片的 checksum,再对上下游的 checksum 值进行比对,通过这样的校验机制以确保数据的一致性。
-
故障演练与兜底预案优化 。这个系统之前是基于 MySQL 的批量系统,迁到 TiDB 后有一些故障场景表现可能会出现非预期的现象,所以微众银行做了大量故障演练,第一是模拟各个 TiDB 组件节点异常,确保应用可以兼容,同时当出现批量中断后,应用也支持断点续跑;第二是整批次重跑,由于可能会遇到程序 bug 或者非预期问题导致整个批次需要重跑,为了快速恢复重跑现场,应用开发了快速备份和 rename 闪回的功能; 第三是针对极端场景的演练,比如假设 TiDB 库出现了整体不可用,微众银行结合 Dumpling 和 Lightning 进行了整集群的快速备份和恢复,难点包括 DM 同步的还原点快速确认、大表人工预打散等等,最后验证的结果符合正确性和时效性的要求。因为这个架构涉及到较多数据流转,所以针对故障场景做了大量的演练以及对应预案 SOP 的编写。
未来规划
微众银行从 2018 年开始调研及 POC,2019 年上线了第一个 TiDB 的应用,当前 TiDB 在微众银行的应用领域已覆盖了贷款、同业、科技管理、基础科技等等,当前还有多个核心业务场景在做 POC 测试。针对未来的规划有五个方面:
-
TiDB 的云原生 + 容器化。 可以带来比如自动化运维能力的提升、资源调配的能力等等。
-
基于 Redis + TiKV 的持久化方案。 主要是替换 Redis + MySQL 的兜底方案,借助 TiKV 天然的高可用特性来做持久化的方案。
-
基于 SAS 盘低成本应用。 微众银行在行内有很多归档场景,数据量特别大,因为受监管要求需要保留很长时间,针对这种存储容量要求高但低频访问的场景,TiDB 基于 SAS 盘低成本的方向也会做一些试点。
-
国产化 ARM 平台的 TiDB 应用。 去年微众银行已经有业务上了 TiDB ARM,未来随着国产化的趋势,这块将会被继续加大投入力度。
-
TiFlash 的评估与应用。 TiFlash 提供的是 HTAP 的能力,尤其像实时风控以及轻量 AP 查询的场景会带来很大帮助,这也是微众银行未来的重点规划方向。