你先跑通一个?你这么说没用对我来说没有有用信息啊

建议,1,使用curl 命令,把4设置为tombstone 状态,如果报错发截图
2,使用刚才的命令 remove,然后看看pd的日志,看看这个动作后台有无报错,或者你直接使用add peer操作,添加副本

那就2吧,估计这个命令被禁止了
还有oom,是可以修改内存相关的参数的

怎么修改,能限制内存,不oom起来更好啊
1,需要你+两个才能多数派
2,内存,capicty 参数,官网搜就有
官网搜一下单机多实例部署,你一台服务器两个实例,必须要改这个参数

另外为啥pd上一直显示tikv有问题,但是tiup显示tikv没问题呢
你的现在三个up还不行?另外,调度加快确实有助加快恢复
三个up都不行
报错还是region unavailable?下次提供我报错,我打字不方便
是的,有个SQL报:region is unavailable
有个sql报:region not in region cache

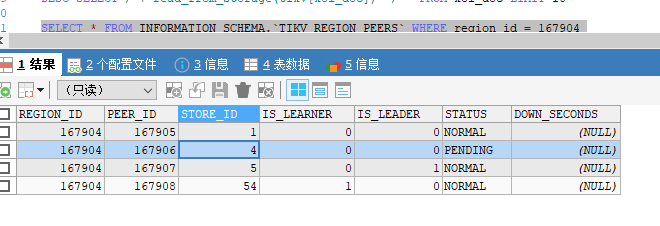
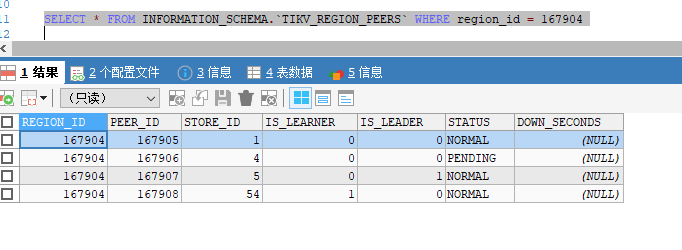
![]() 你都所有的region都操作完了吗?得用刚才的sql验证吧
你都所有的region都操作完了吗?得用刚才的sql验证吧
你还是2步都操作吧:1、调整 内存相关的参数,别 oom 了 2、再add-peer (你的 region 数量太多了,add-peer 操纵 估计的几小时才能结束)
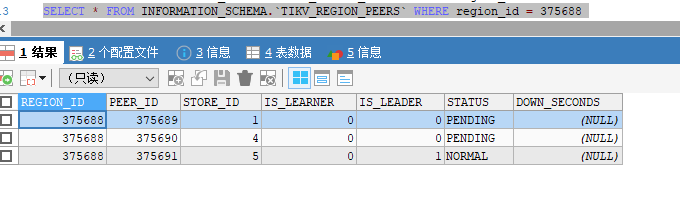
我发现报错的region都是这样的,分布在store 1和4,状态是pending,有两个问题啊:
1.这个status的pending和offline是啥关系,这个store 1 现在在下线中,为啥有的peer是pending有的是offline,有的是normal
2.为啥现在tikv已经5个节点了,这个region pending了两个副本了,为啥没被调度补充?
如果是v4版本,可以直接将store改为Tombstone,然后就可以直接remove,正常下线了,v5不能强制Tombstone有点坑了。。。 现在就是有2000多个region down了两个副本,卡住了,即使扩容了tikv,也不调度了