region 如果没有缺失,那可能是由于 tikv 所在的主机配置低、tikv 压力比较高,导致整个调度过程比较慢,业务请求遇到 region transfer 后重试超时,而且你这里 tikv label 设置不太合理,相同的主机上多个 tikv 实例 label 最好保持一致,否则可能出现 region 多个副本同时调度到一台主机上,如果这时主机挂了就会发生多副本丢失了。 建议你单独找台服务器扩容 tikv 节点, 并注意保持磁盘容量规格保持一致。
tikv目前压力不大,或者说几乎无压力,我们在线业务已经全停了,影响已经很大了
即使调度过程很慢,还是会遇到region transfer重试超时?
tikv的label,同一台主机,我们不想有多个store,是因为原来的tikv起不来,一直OOM,我们没办法,又不敢强制下线掉他,只能在本机换端口重开一个tikv,先保证3个副本数据不丢, 现在同一主机的tikv只有一个是UP状态的,另一个是offline的,offline的也可能出现region多副本同时调度到一台主机?
我们机器现在没啥负载,tikv还是不能提供服务,一直报region不可用,tikv timeout
offline 是 tikv 一个中间状态,只有在region leader transfter 和 region balance 完成后才能下线成功,而同一台主机上 2 个 tikv label 不相同,是有可能把 region 调度到相同的一台主机上的。如果想加速 region balance 过程,除了调大 scheduler limit 相关参数外,还需要把 store limit 也调大,参考:https://docs.pingcap.com/zh/tidb/v5.0/configure-store-limit#store-limit
我觉得region balance这个均衡不均衡我觉得已经不关键了,关键是为啥tikv无法提供服务了。。。我们现在生产tikv已经停止服务好几个小时了,region没丢,所有region都有leader, 这还无法提供服务,关键是还得不到解决的方法。。让人很无语
你的store有两个是offline,把任何一个启动起来就OK了
27那个store是前天 --force强制下线的,起不来
91这个节点,一启动就OOM,根本起不来,所以我们怕丢数据才赶紧在当前节点改了个端口又起一个
oom的报错是啥,现在业务没有的情况下,oom?
现在的问题是,你两个副本出问题,是业务不可用的啊,所以要想办法把oom的服务器启动起来,另外,就是建议先扩容一台tikv了
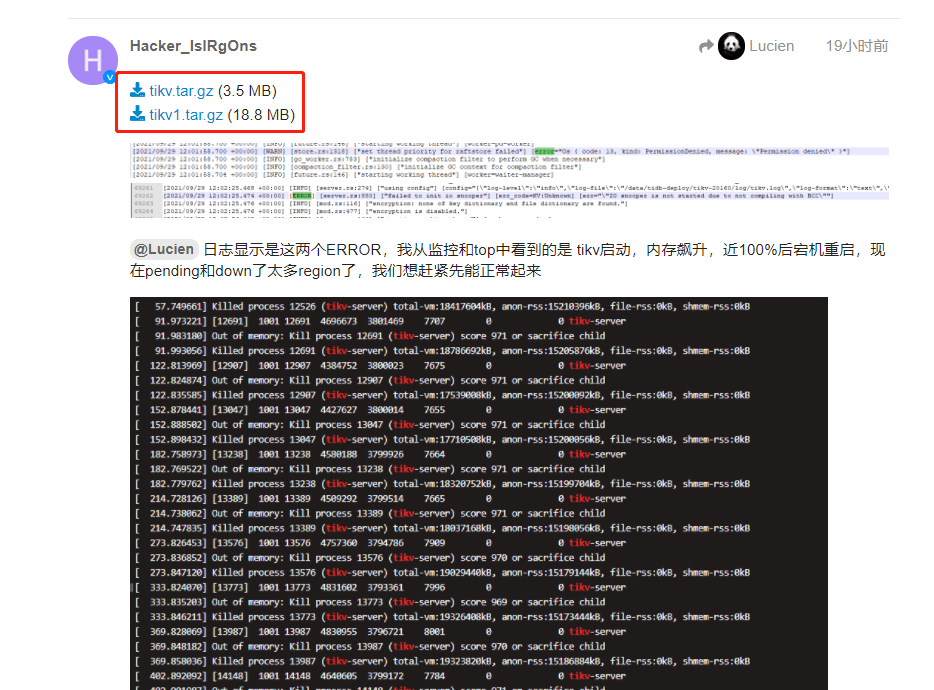
能修改一下内存相关的参数不,另外,看下监控,到底使用了多大内存,担心开启大页了
日志我看不了,地铁上
不是两个副本出问题, 27这个节点是前天出的问题,当时这个节点没有leader,就强制下线了,在该节点重启了个tikv,因为pd中有残留数据,所以一直显示在下线中, 在27上扩容完之后就已经好了,然后昨天91这个又出问题了, 因为里面还有57个leader,所以我们没强制下线,在该节点又起了个tikv,先把3副本保住,谁知道无法提供服务了
你看那个截图,OOM的日志就是报了那两个错误
[2021/09/29 12:01:58.700 +00:00] [WARN] [store.rs:1318] [“set thread priority for raftstore failed”] [error=“Os { code: 13, kind: PermissionDenied, message: “Permission denied” }”]
[2021/09/29 12:02:25.474 +00:00] [ERROR] [server.rs:880] [“failed to init io snooper”] [err_code=KV:Unknown] [err="“IO snooper is not started due to not compiling with BCC”"]
官网有命令,能查看没有leader及少副本的命令,你看一下

按你上面说的,不会报regon不可用的,而且27应该是Tombstone状态才对
那你业务的报错到底是啥,我看看
估计你要把tidbServer重启一下才行了,现在可以重启不


tidb server可以重启,我试下这个?