那就是那个explain的执行计划是不对的吧,实际还是 把数据都推送到tidb server 然后oom了吧,另外这个图我看推给tidb 3个多G,也没达到7G上限吧,即使达到7G上限也只是被kill掉,更没达到tidb server的总内存14G吧
- 对,估计是错的
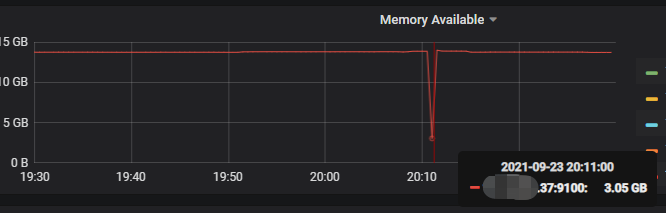
- 截图里的占用是 OOM 前的提前预警的时候抓取的 profile,不完全准确
1.我们很多sql都是使用这个字段分析的,如果这个字段加了索引,其他使用这个字段的sql都会有影响的,3个多亿数据走tikv太慢了,有别的方式吗?
2.这个sql已经很简单了。。。就是个group by having。。这个也不能完全下推tiflash吗。。。
尝试一下
set @@session.tidb_enforce_mpp=1;
这个系统变量看看,具体可以看一下文档关于这个变量的描述
使用这个系统变量后,explain 看一下计划是不是都在 TiFlash 上面
这个变量在 5.0.3 上好像没有…抱歉这个可能行不通。但是在更新版本上是可以的,譬如 5.2 版本上可以做到全部下推
所以说,5.0.3,只能是加索引走tikv了是吧。。
我们发现,之前在4.0.x版本的时候,我们几乎90%的sql都不能走tiflash,所以我们新集群用了5.0.3,
用上5.0.3之后,发现80%的sql还是不能走tiflash,虽然tiflash文档上写的能支持大量算子下推,但实际都是些比较普通场景的SQL 也无法下推tiflash,我们就比较苦恼。。。
请看,我刚刚使用了 5.2.1 版本,发现这个 SQL 是可以大量下推的。因为 TiFlash 还是很新的产品,功能在快速迭代之中,新的版本能支持更多的算子,也请海涵。
所以现在有两个选择:
- 升级版本到 5.2+,那么 hash agg 可以全量下推,在 TiDB 测的计算可以被限制住而不 OOM,但整体而言还是要扫全表做聚合
- 添加索引使用 stream_agg,这个可以从计算逻辑上限制住计算量,应该也可以跑得很快。我们可以通过 ignore index 这种 optimizer hint 保证其他 SQL 不走这个专门的索引
老师,这个内存占用图是你们内部的工具吧,开源吗![]()
这个图上的结构都是tidb模块的吗?
都是 TiDB 的模块,这个不是我们内部工具,是 golang 的 profile 工具
你给的 record 里面,解压执行
go tool pprof -http 127.0.0.1:4008 heap2021-09-23T02:56:34Z
然后就可以本地查看了
3 个赞
我计算了下,因为是读的tiflash,应该只会读 main_post_id 这一列,得到的结果只有两列,然后把这两列数据推送给tidb,按这两列计算的话,即使没有一条数据重复,那这3个多亿的数据,大概8G左右,生产这个tidb可用内存是14个G,还远远达不到,及时是这个hash_agg没下推,也没撑爆内存啊。。 而且我看了下top命令,内存在75% tidb server就重启了,看dashboard监控,这个节点当时的内存也没用完。。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。