[root@master home]# kubectl get endpoints -n tidb-admin my-tidb-pd-peer
NAME ENDPOINTS AGE
my-tidb-pd-peer 10.244.1.220:2380,10.244.3.166:2380 63m
是的
应该是读不到pd1的endpoints
造成域名无法解析的原因多种多样,有很多是系统性的。从现象来看是这个 Pod 的域名解析有些问题,这里有个 DNS 问题诊断的文档可以参考下:
https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/
如果 Endpoints 里面没有相应的 Pod 的 Endpoint(现在的状况),那么还需要参考这篇文档来诊断此问题:
https://kubernetes.io/docs/tasks/debug-application-cluster/debug-service/
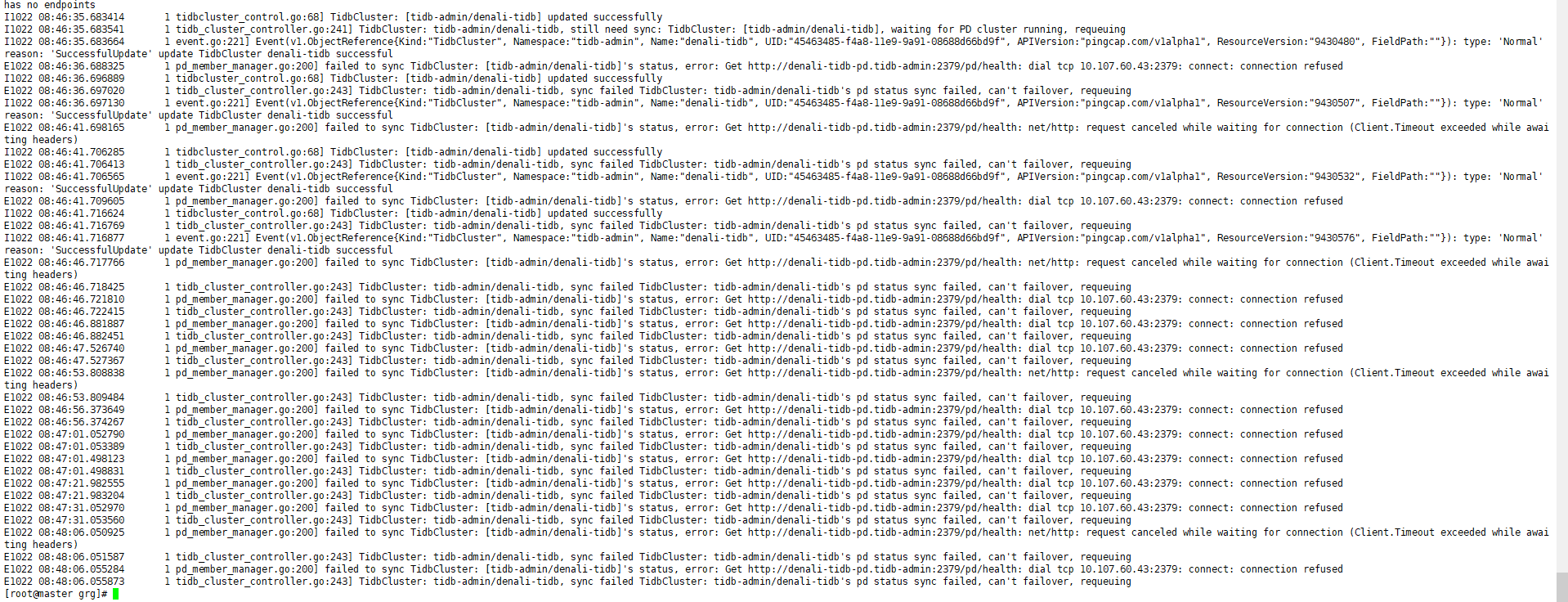
是不是因为我之前试图缩容的失败了 所以导致这样的问题的 。
之前是部署成功的 但是我就想试试缩容把三个节点变成一个 结果等很久也没有变化, 只看到node3是offiine状态。
之前删除重新部署就成这样了··
DNS那个不太懂怎么排查呀·· 看一大堆文档说明 看不大明白抓不住下手点!!
烦请再帮我分析一下 看怎么处理法!
TiKV 的数据默认是三副本的, 所以,如果现在只剩三个 TiKV 节点的话,就无法再缩容了,会一直是 offline 状态的。
文档里提供了很多可能的方式,其中有一个我比较怀疑,我们可以来试试:按照上面的文档,首先来看看在那个 pod 的 node 上是否能解析域名,然后再进到 pod 里去看看 /etc/resolv.conf 文件:
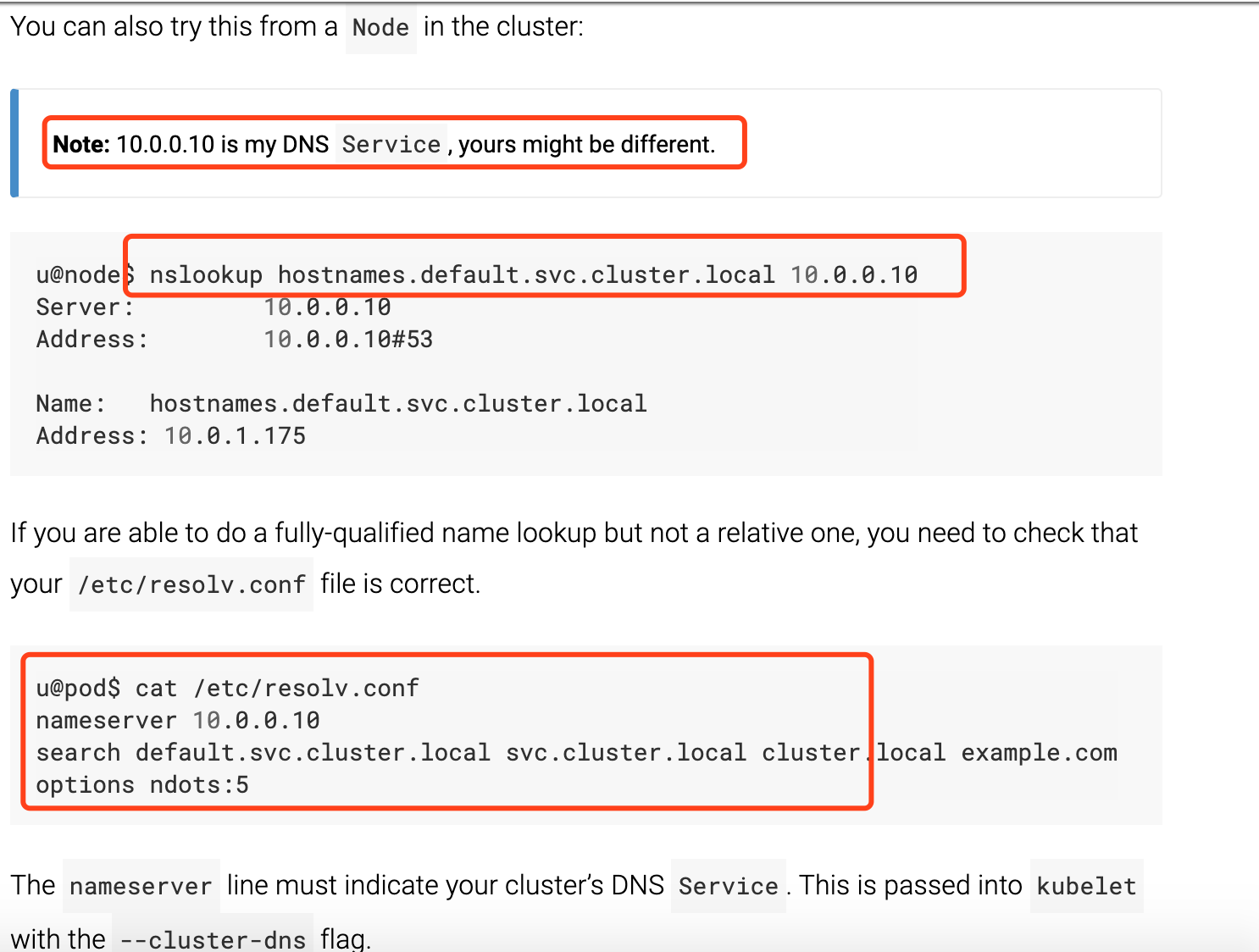
/ # cat /etc/resolv.conf nameserver 10.96.0.10 search tidb-admin.svc.cluster.local svc.cluster.local cluster.local localdomain options ndots:5 pod内的resolv.conf配置文件如上所示
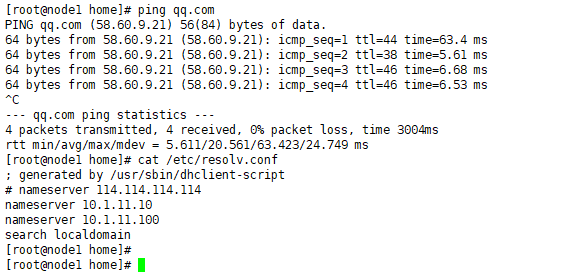
node节点外是正常解析域名 的 。。
麻烦再提供一下信息:
1,node 节点上是怎么解析这个 pod 域名的,详细截图下;
2,node 上的 /etc/resolv.conf 文件看下;
3,pod 内上是怎么解析这个 pod 域名的,详细截图下也。
另外,网络问题一直都是很复杂的,原因也是多种多样的,这个问题有一定可能跟 tidb operator 关系不是很大,也可以请你们负责 k8s 网络方面的同学也帮忙看看。
我就是负责我们k8s的啦 、
我现在最小化部署先 起一个pd 一个kv发现pd的日志信息是下面这样的
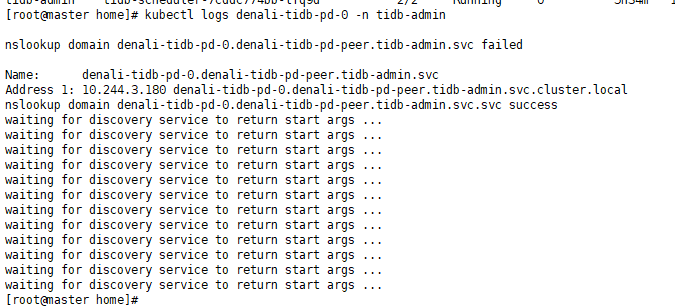
这么看起来是service有问题吗?
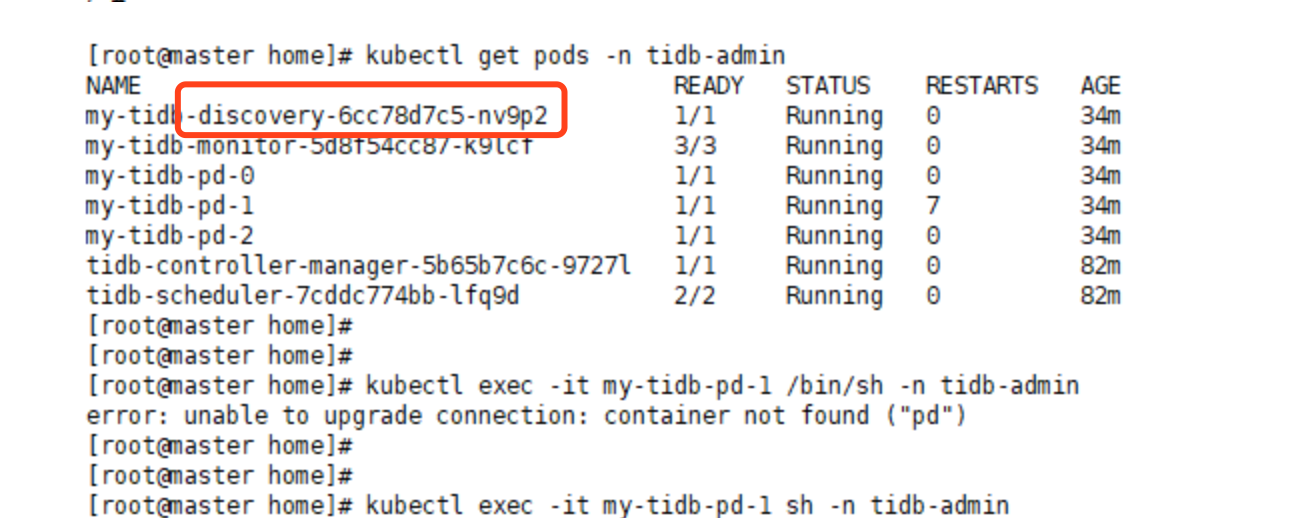
先通过这个 gist 里面描述的方法,确认一下 DNS 服务是否正常,如果不正常请联系你们网络的同事协助排查一下。
[root@master home]# kubectl logs denali-tidb-discovery-78654b4796-fc2vn -n tidb-admin
I1022 11:22:06.361214 1 version.go:38] Welcome to TiDB Operator.
I1022 11:22:06.361338 1 version.go:39] TiDB Operator Version: version.Info{GitVersion:“v1.0.0”, GitCommit:“0214ddab80dc07616f86102733fb6c69a0137429”, GitTreeState:“clean”, BuildDate:“2019-07-30T09:10:06Z”, GoVersion:“go1.12”, Compiler:“gc”, Platform:“linux/amd64”}
I1022 11:22:06.362082 1 mux.go:40] starting TiDB Discovery server, listening on 0.0.0.0:10261
[root@master home]#
节点域名 解析是正常的
denali-tidb-discovery-78654b4796-fc2vn的日志信息 现在看不出什么问题
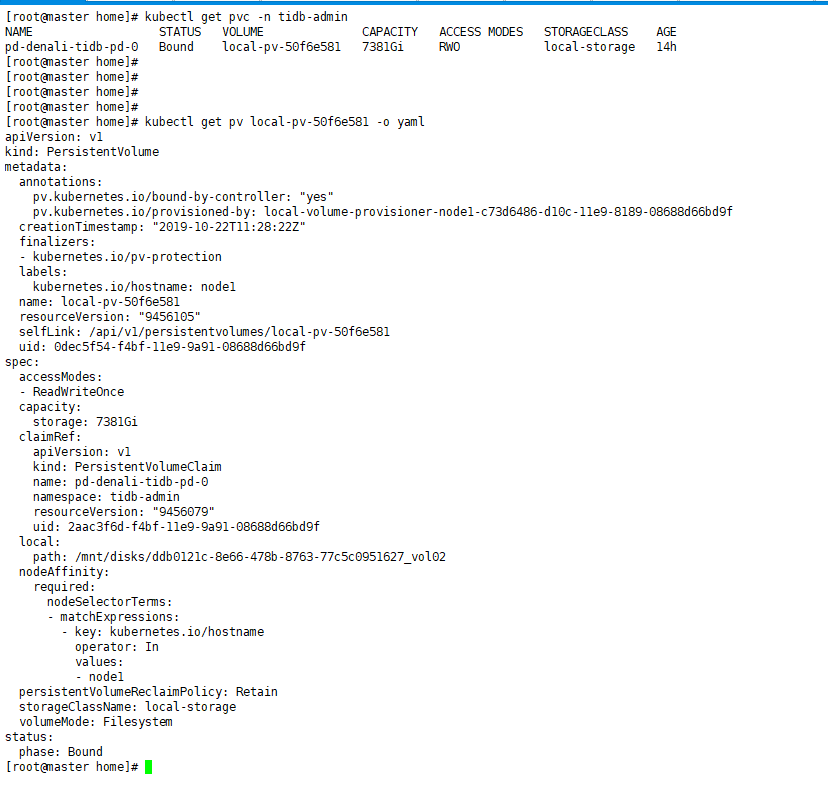
- 找到 3 个 PD 的 PVC 对应的 PV, VOLUME 这一列输出就是:
$kubectl get pvc -n tidb-admin
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pd-dan-pd-0 Bound local-pv-51611e5a 440Gi RWO local-storage 27m
pd-dan-pd-1 Bound local-pv-618ce90c 440Gi RWO local-storage 27m
pd-dan-pd-2 Bound local-pv-3a513ead 440Gi RWO local-storage 27m
- 针对每个 PV,找到其对应的挂载节点及目录:
kubectl get pv local-pv-51611e5a -o yaml
...
local:
path: /mnt/disks/vol1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- 172.16.4.9
...
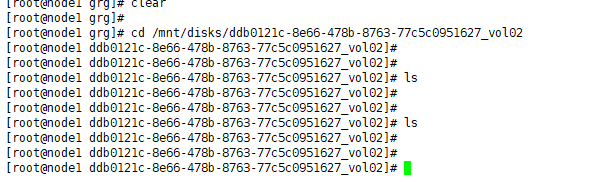
- 登录到 节点上,将对应目录下所有的数据删除,注意,目录(/mnt/disks/vol1)本身不要删除
- 手动删除所有 PD Pod
- 如果还是不行,请再次拿一下 3 个 PD,discovery 和 tidb-controller-manager 的 log
麻烦确认一下,中间是不是有 手动 删 PV 的过程,或者整个 k8s 集群重装的过程,从现象上看,PD 绑定的 PV 上有以前 PD 启动的数据,应该是某些操作导致 PV 被重新创建,但是 PV 对应的目录下面的数据没有清除,保留了旧数据。 另外,一般 tidb 集群 和 tidb operator 部署在不同 namespace,看起来比较清晰,但是本身对这个问题没有影响。
现在只起了一个 PD? discovery pod 的 log 抓一下吧,还有下面的两个输出:
kubectl get tc denali -o yaml -n tidb-admin
kubectl get sts denali-tidb-pd -o yaml -n tidb-admin
kubectl get tc denali -o yaml -n tidb-admin
![]()
kubectl get sts denali-tidb-pd -o yaml -n tidb-admino.yaml.log (7.5 KB)


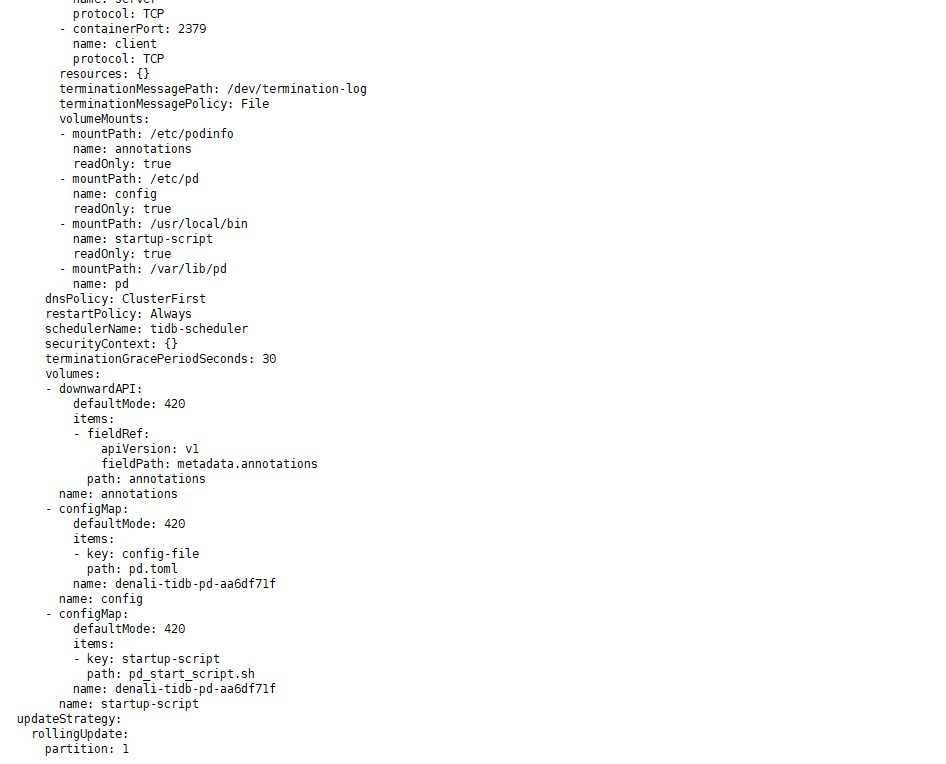

discovery Pod 没有任何日志,说明 pd 这个 Pod 到 discovery Pod 的网络不通,也就是说 pod 到 pod 的网络是有问题的。所以建议首先排查下 k8s 的网络,看看网络组件是否工作正常。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。