[error=“Put http://pushgateway:9091/metrics/job/pd0/instance/e61d172b858e: dial tcp: lookup pushgateway on 127.0.0.11:53: no such host”] 这些报错不影响
我现在是按照顺序起的,那这些先略过,现在tikv跟之前一样的错误,
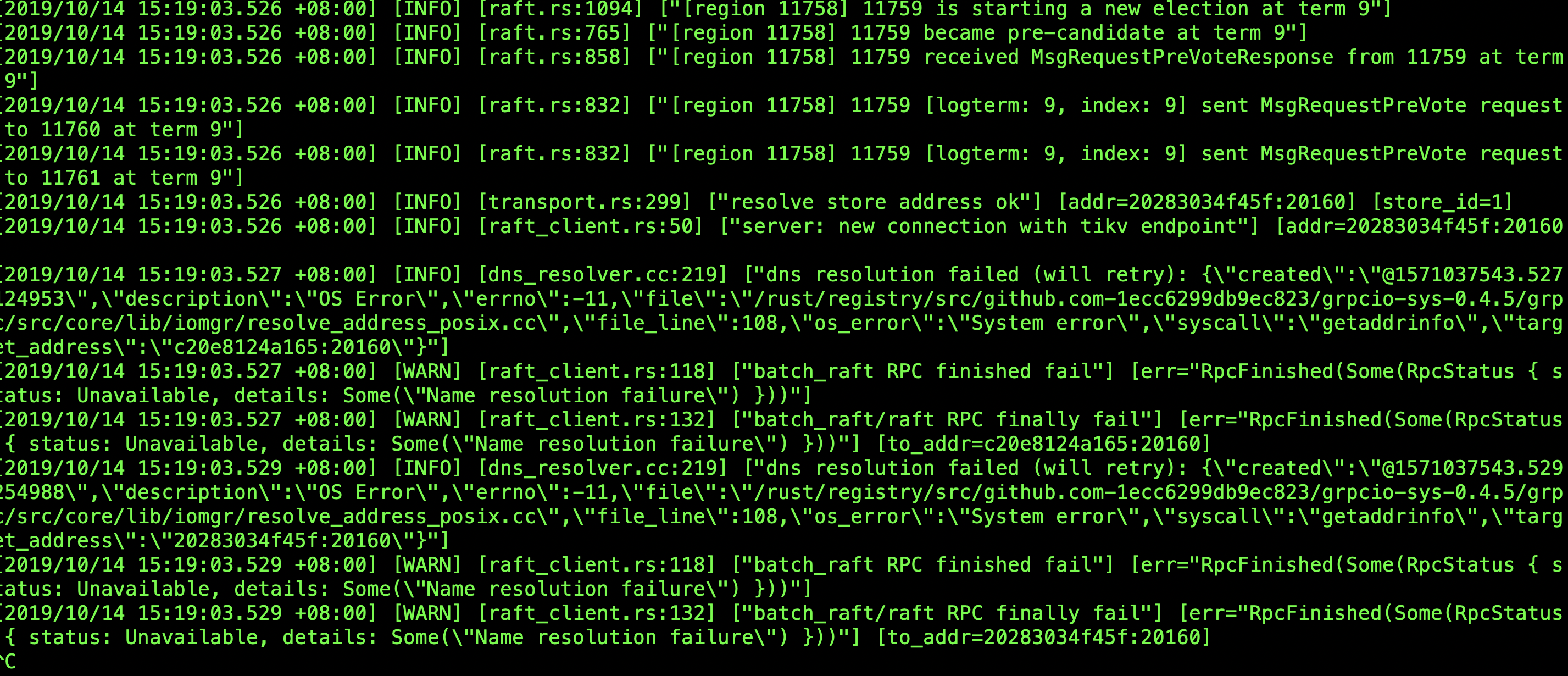
[2019/10/14 15:19:03.525 +08:00] [INFO] [raft.rs:832] [“[region 11774] 11775 [logterm: 8, index: 3849] sent MsgRequestPreVote request to 11776 at term 8”]
[2019/10/14 15:19:03.525 +08:00] [INFO] [raft.rs:832] [“[region 11774] 11775 [logterm: 8, index: 3849] sent MsgRequestPreVote request to 11777 at term 8”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:1094] [“[region 11534] 11535 is starting a new election at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:765] [“[region 11534] 11535 became pre-candidate at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:858] [“[region 11534] 11535 received MsgRequestPreVoteResponse from 11535 at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:832] [“[region 11534] 11535 [logterm: 9, index: 12094] sent MsgRequestPreVote request to 11536 at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:832] [“[region 11534] 11535 [logterm: 9, index: 12094] sent MsgRequestPreVote request to 11537 at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:1094] [“[region 11758] 11759 is starting a new election at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:765] [“[region 11758] 11759 became pre-candidate at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:858] [“[region 11758] 11759 received MsgRequestPreVoteResponse from 11759 at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:832] [“[region 11758] 11759 [logterm: 9, index: 9] sent MsgRequestPreVote request to 11760 at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft.rs:832] [“[region 11758] 11759 [logterm: 9, index: 9] sent MsgRequestPreVote request to 11761 at term 9”]
[2019/10/14 15:19:03.526 +08:00] [INFO] [transport.rs:299] [“resolve store address ok”] [addr=20283034f45f:20160] [store_id=1]
[2019/10/14 15:19:03.526 +08:00] [INFO] [raft_client.rs:50] [“server: new connection with tikv endpoint”] [addr=20283034f45f:20160]
[2019/10/14 15:19:03.527 +08:00] [INFO] [dns_resolver.cc:219] [“dns resolution failed (will retry): {“created”:”@1571037543.527124953",“description”:“OS Error”,“errno”:-11,“file”:“/rust/registry/src/github.com-1ecc6299db9ec823/grpcio-sys-0.4.5/grpc/src/core/lib/iomgr/resolve_address_posix.cc”,“file_line”:108,“os_error”:“System error”,“syscall”:“getaddrinfo”,“target_address”:“c20e8124a165:20160”}"]
[2019/10/14 15:19:03.527 +08:00] [WARN] [raft_client.rs:118] [“batch_raft RPC finished fail”] [err=“RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(“Name resolution failure”) }))”]
[2019/10/14 15:19:03.527 +08:00] [WARN] [raft_client.rs:132] [“batch_raft/raft RPC finally fail”] [err=“RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(“Name resolution failure”) }))”] [to_addr=c20e8124a165:20160]
[2019/10/14 15:19:03.529 +08:00] [INFO] [dns_resolver.cc:219] [“dns resolution failed (will retry): {“created”:”@1571037543.529254988",“description”:“OS Error”,“errno”:-11,“file”:“/rust/registry/src/github.com-1ecc6299db9ec823/grpcio-sys-0.4.5/grpc/src/core/lib/iomgr/resolve_address_posix.cc”,“file_line”:108,“os_error”:“System error”,“syscall”:“getaddrinfo”,“target_address”:“20283034f45f:20160”}"]
[2019/10/14 15:19:03.529 +08:00] [WARN] [raft_client.rs:118] [“batch_raft RPC finished fail”] [err=“RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(“Name resolution failure”) }))”]
[2019/10/14 15:19:03.529 +08:00] [WARN] [raft_client.rs:132] [“batch_raft/raft RPC finally fail”] [err=“RpcFinished(Some(RpcStatus { status: Unavailable, details: Some(“Name resolution failure”) }))”] [to_addr=20283034f45f:20160]
现在是测试环境把? 在 docker 中,各容器怎么通信的,通过服务名还是 ip 。
部署方式是什么?
现在是通过服务名通信,容器内测试是通信正常
nc -v -u tikv:9002
上方有截图
20283034f45f:20160
c20e8124a165:20160
这些都无法解析出来

我对 docker swarm 这个项目不太熟悉,如果容器 id 都不同了,那么应该都不是一个容器了。 我这边没办法去恢复他们
我不太理解,比如说 tikv1 , 现在应该是启动的新的容器了,那原来容器的数据都还在吗?
原来的容器数据还是在的,我理解的是这些同步的数据应该是raft同步状态中的这些数据,应该是存储有kv节点信息一类的数据,换种说法就是,现在能不能把一个已停止运行的tidb集群中的数据,恢复到一个tidb新集群中,有部分数据丢失没关系
跳过 SSD 检测两种方法: bootstrap 时 --extra-vars “dev_mode=True” 或者在 tidb-ansible/roles/machine_benchmark/defaults/main.yml 中修改阈值