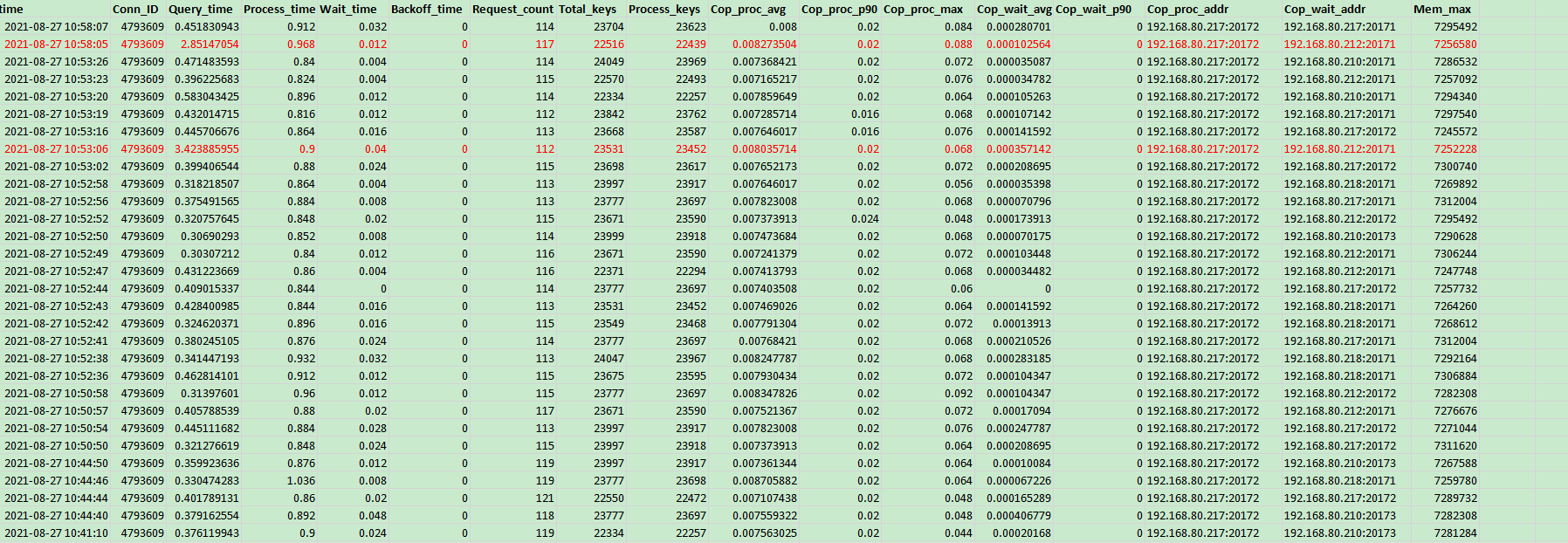
循环提交相同sql查询到tidb server,发现查询响应时间有比较大的抖动,短的在3s左右,长的达到近7s,具体参见慢查询日志表对应日志记录:
查看tidb server debug日志发现对应conn=2733的查询,每次都触发了“
rpc error: code = ResourceExhausted desc = Received message larger than max (xxxx vs. 10485760) ”异常,是由于此异常导致重试从而带来延迟抖动吗? 这个异常是怎么引起的呢?改如何调整集群配置来避免此异常呢?
tidb server debug日志 tidb.log.7z (678.4 KB)
sql查询语句 query.sql (3.7 KB)
tidb版本:v3.0.3
2 个赞
SQL执行计划参见 SQL执行计划.xls (32.5 KB)
1 个赞
@xfworld 这种查询时长的明显异常波动跟这个ResourceExhausted rpc error有关吗?
1 个赞
xfworld
2021 年8 月 26 日 09:20
5
这个执行计划感觉不准啊,table 数据有没有做analyze
1 个赞
@xfworld 按照你所说针对所有表执行了analyze table后,查询耗时确实出现了明显下降,现在普遍在0.3-0.5s,但还会出现个别点的大的耗时波动情况,慢查询日志表对应日志记录如下:
执行完analyze table后SQL查询计划情况参见
Analyze Table后SQL执行计划.xls (45 KB)
像这种查询耗时波动又会是由哪块怎么导致的呢?另外,表的统计信息是不会自动定期更新,怎么会出现这种统计信息更新不及时的情况呢?
1 个赞
xfworld
2021 年8 月 27 日 03:21
9
analyze 做分析的时候,会影响读写的
可以自己配置,如果这个表的数据更新,删除狠频繁,建议做,不然执行计划肯定不准
你得考虑一下什么时候做这个动作会更合适,至于操作可以看看文档https://docs.pingcap.com/zh/tidb/stable/statistics#自动更新
1 个赞
那analyze table后还有查询耗时的大的抖动,接下来该怎么进一步排查呢?
1 个赞
xfworld
2021 年8 月 27 日 04:35
11
是同一条 SQL 么?
如果是同一条的话,只能通过 explain 来分析优化了,通过查阅索引配置等等
1 个赞
是相同的sql呢,并且我又切换到另一个tidb server上去查询,连续运行这个相同sql对应的查询耗时却一直在0.3-0.5s,说明这个抖动跟tikv层关系不大了,是由先前那个特定的tidb server贡献的。
1 个赞
都是相同网络环境,而且先前那个抖动的tidb server是每隔几次查询后就会固定有一次抖动。
xfworld
2021 年8 月 27 日 08:16
15
上个网络流量监控看看, 资源够的话,tidb server 也可以多搞几个实例
system
2022 年10 月 31 日 19:05
16
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。