qhd2004
(Qhd2004)
1
【 TiDB 使用环境】
【概述】:场景 + 问题概述
我们6节点集群,三个tidb-server节点,其中某个节点总是连接不上,如下图
【背景】:做过哪些操作
正常运行,没有做调整,也没有上线相关业务
【现象】:业务和数据库现象
down的这个节点,ssh连接不上
【TiDB 版本】:
v5.1.0
【附件】:
- 我的问题
1,我要如何排查呢,这时,在grafana中我可以查看哪些来获取进一步的信息?
2,在相关慢查询中,我要如何判断sql使用了多少内存呢?
3,我们这个问题跟慢查询是否有关?
QBin
(Bin)
2
qhd2004
(Qhd2004)
3
qhd2004
(Qhd2004)
4
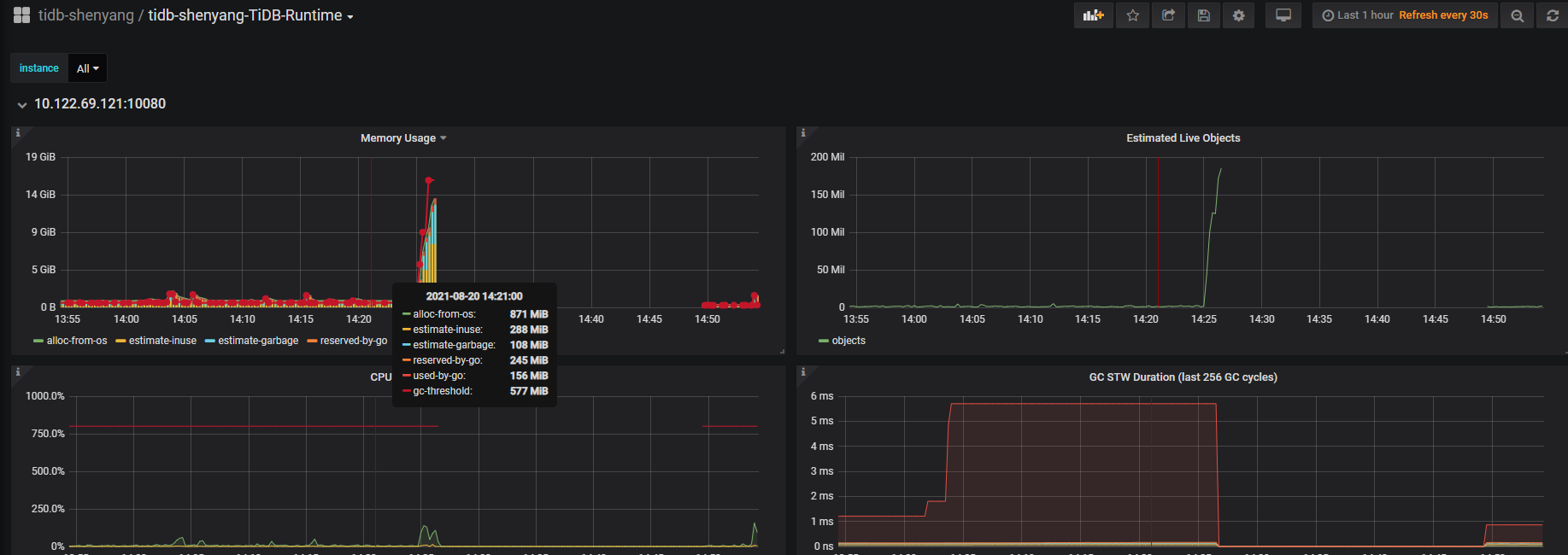
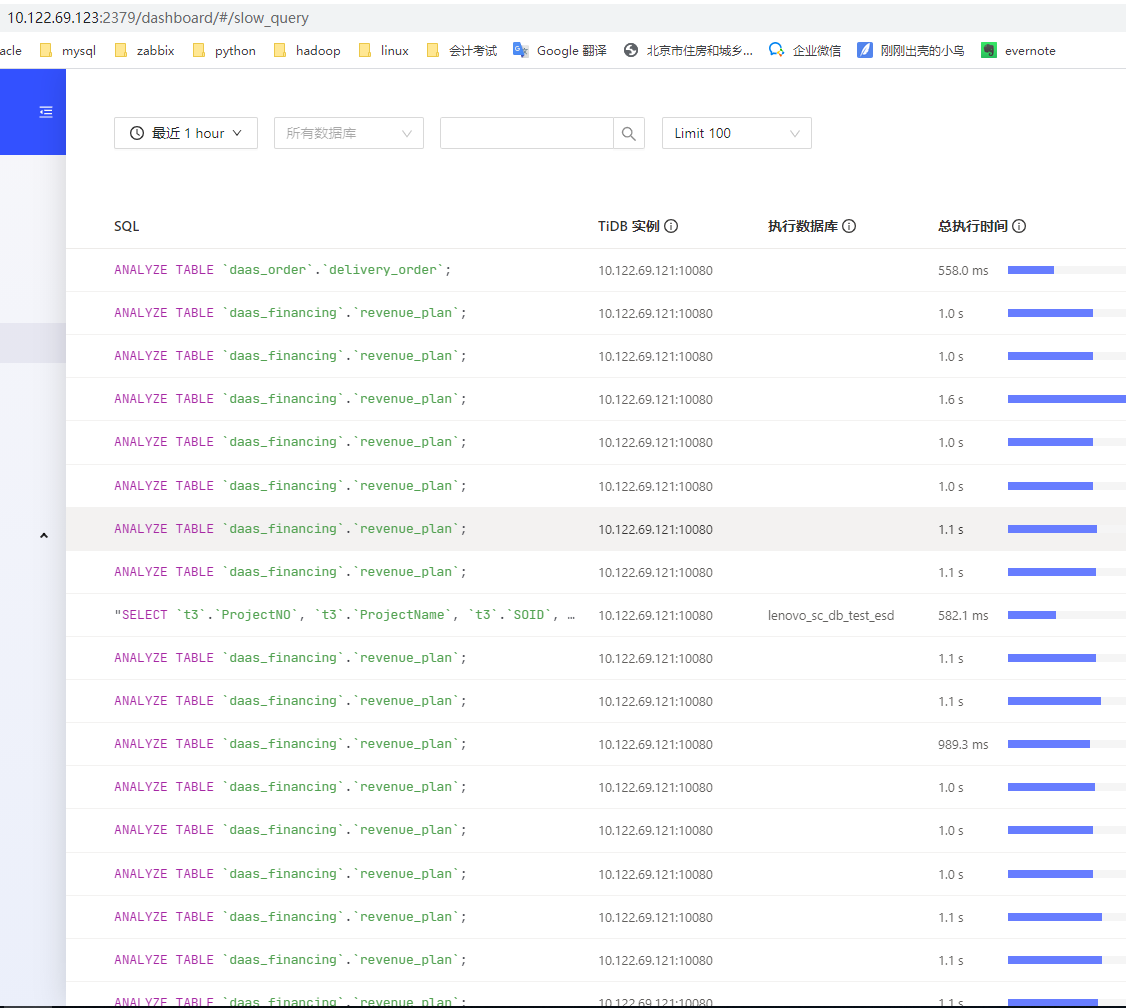
我在dashboard中发现,在121这个节点上有大量的analyze table操作,如下:
这个analyze还是只针对这一张表
qhd2004
(Qhd2004)
6
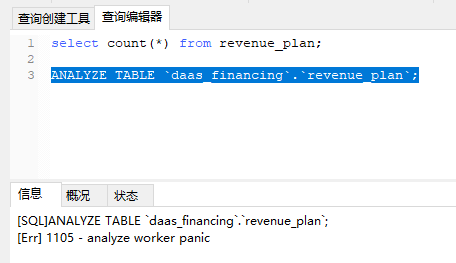
空表是可以的,但是这个表中有数据就报错了(表中大约有4W+数据)
qhd2004
(Qhd2004)
7
qhd2004
(Qhd2004)
9
已经升级到5.1.1了,目前观察问题解决了。
估计是,tidb执行analyze语句,没有收到正常反馈,然后就再次发出analyze语句,这样就把资料给用尽了。
system
(system)
关闭
10
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。