一、业务概述
威锐达远程诊断大数据中心是以风场端WindCMS风机振动在线监测系统为前端基础,配合在离线数据回收工具,在威锐达公司内构建的一个满足人工故障诊断、机器学习与数据挖掘、BI可视化统计等各种业务数据需要的综合大数据中心,宗旨是以尽可能小的成本最高效地提供按需数据响应。整个中心的业务数据流如下图所示:
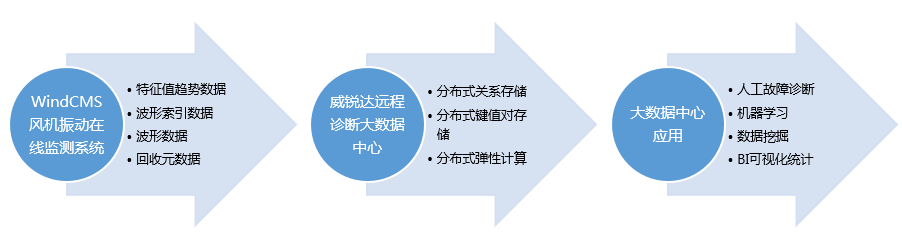
中心的数据是风场端WindCMS风机振动在线监测系统从风机振动监测采集单元采集到的工业振动数据,会每4小时左右产生一组,这些时序数据通过离线数据回收工具回收到中心,而进入中心的数据还会呈现出随时间流逝访问热度也随之逐渐降低的特点。目前,中心可在线稳定接入全国具备接入条件的所有风场在线振动监测数据,对于不具备接入条件的风场,还支持历史数据的在离线回收,在线接入数据涵盖了100多个风场、4000多个机组,日接入数据主要包括280w多条特征值趋势数据、28w多条波形及其索引数据,除此之外还有10w多条数据回收元数据。如果有历史数据回收任务进行的话,接入数据规模还会进一步加大。
面对全国风场的在离线数据接入需求,使用传统的“单机关系数据库+文件系统”方式显然不能很好满足接入吞吐和效率的要求,另外,随着接入时间的持续,源源不断的接入数据也会进一步拖慢单机数据库、文件系统的运作效率,同时磁盘剩余空间也会被慢慢吃完。为此,选择一种分布式的、可按需扩展的数据存储方案势在必行!
二、TiDB 数据库优势特点
TiDB数据库是一款分布式分析/事务混合型NewSQL数据库,其优势特点如下:
-
支持容量及性能的水平弹性扩缩
-
兼容 MySQL 协议,几乎无须修改代码即可无缝迁移切换
-
满足业务故障自恢复的高可用,且易维护
-
强一致的分布式事务处理
-
支持 Spark,可支撑大体量数据查询与机器学习应用
-
集群状态可视化监控,方便运行维护
三、TiDB 应用结合点
基于上述业务和TiDB数据库自身优势特点的分析,我们分布式、可扩展的数据存储方案最终选择将TiDB数据库作为关系数据存储。TiDB数据库在我们实际使用中,主要有下面两方面的结合点:
1. 分布式关系 - 键值对混合型二级数据存储方案
中心需要接入的在线振动监测数据主要是特征值趋势数据和原始振动波形数据。前者是一条条的关系数据记录,接入到中心后适合存储到关系数据库表中,后者是一个存储大小在500KB左右的数值列表,而其在业务使用时又是通过机组ID、测点位置、采集时间等组合属性来定位的,由此可见其数据访问使用具有典型的索引+键值对访问特性。基于上述数据本身及其使用的特点,我们对数据的存储方案选择了“特征值趋势、波形索引存储于TiDB,波形存储于键值对数据库”的分布式关系-键值对混合型二级数据存储方案。其中,TiDB特征值趋势主要用于进行趋势图展示、BI可视化统计,TiDB波形索引主要用于进行数据定位和其他一些基于关系的数据统计;键值对数据库波形则用于基于键的波形展示。
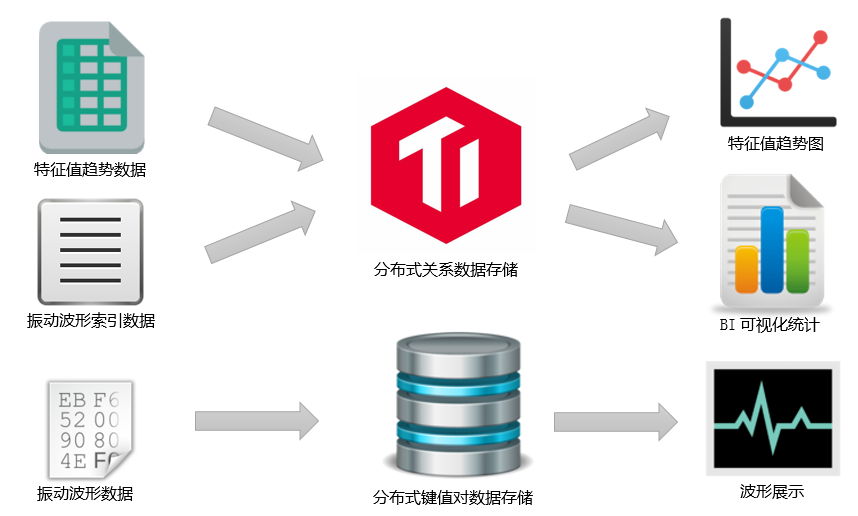
通过基于TiDB和键值对数据库的分布式关系-键值对混合型二级数据存储方案落地实施,中心数据接入能力得到了全面的提升,各项数据接入工作得以有序、高效地开展推进。
2. 基于 SparkSQL 弹性分布式内存计算的自助交互式分析查询

围绕着中心数据的访问使用,上游的BI可视化统计等业务数据访问需求具有典型的自助交互式访问特性,要求数据查询响应时长不宜太长,且不会因数据量的增大而明显变长。这对一般的“PDServer+TiKVServer+TiDBServer”TiDB查询架构构成挑战,实际运行使用过程中经常会因为自助交互式查询提交的数据查询过大而导致TiDBServer资源不够用而中止请求的情况,这不仅导致当前进行的自助交互式分析无法进行,还影响了别的在线数据查询请求。为了避免此问题和更好地满足这种灵活的自助交互式查询需求,引入基于TiSpark的Spark SQL分布式数据查询支持。TiSpark运行架构如下图所示:
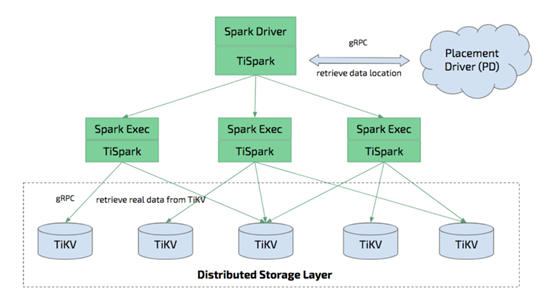
由于此种查询方式基于SparkSQL分布式内存计算框架,同时直接对接TiKVServer存储层,不仅充分利用了Spark分布式弹性内存计算的高性能、高可扩展特性,还最大程度地保证了数据查询的快捷性。而实际使用中也确实如此,SparkSQL交互式查询上线后,对上游的大体量交互式数据查询响应更快了,也能接受处理更多请求了,基于SparkSQL弹性分布式内存计算确实给BI自助交互式分析查询提供了更强大的支持。
四、TiDB 部署架构
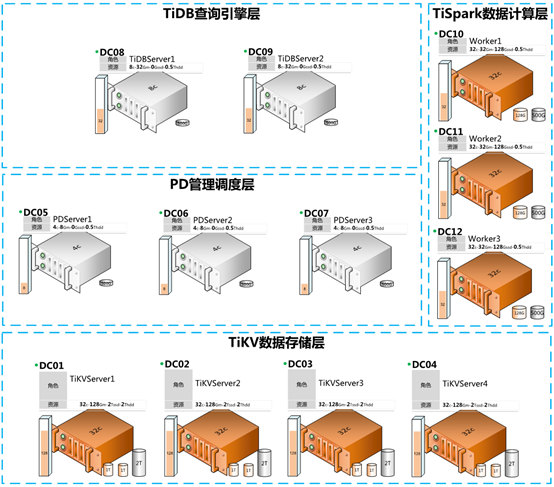
相比于威锐达 WindRDS 远程诊断与运维中心前期项目,本中心在原有部署架构基础上主要做了如下调整变化:
-
PDServer节点数由2个扩展到3个
-
TiKVServer节点数由3个扩展到4个,并将每个节点内存升级至128G
-
TiDBServer节点数由1个扩展到2个
变化后的TiDB部署架构如下图所示:
五、未来展望
未来随着更多风场数据的陆续接入和所有已接入风场数据的源源不断积累,中心积累的数据将会明显增长到一个新的水平,为了更好地确保中心更可靠、稳定、高效地运行,计划从以下两个方面来对现有的TiDB集群进行改进优化:
1. 建立跨互联网的异地容灾分中心
为了更好地确保数据接入的可靠性,将在异地部署上线若干TiKVServer实例,将当前中心的数据同步到异地分中心中,形成异地容灾数据,同时进一步提升异地数据访问的及时性。
2. 建立全生命周期的分级存储体系
考虑到业务数据自身访问使用随时间冷热不同的特点,为了更好地确保数据查询的稳定性、高效性,将存储于TiKVServer上的数据根据业务时间划分成由高到低的不同存储等级,更高存储等级存储时间更近、热度更高的数据,各存储等级使用不同IO性能的存储设备,建立由高到低存储等级数据的自动迁移流转机制,实现不同存储等级数据的按生命周期的存储和查询。